









目录
- 定义
- 作用
- 特点
- 语法
- 树结构
- 解析方法
定义
XML(extensible Markup Language) ,是一种数据标记语言 & 传输格式
作用
- 对数据进行标记(结构化数据)
- 对数据进行存储
- 对数据进行传输
与html的区别:html用于显示信息;xml用于存储&传输信息
XML特点
- 标签可进行自定义
XML允许作者定义自己的标签和文档结构 - 自我描述性
XML文档实例
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
仅仅是一个纯文本,有文本处理能力的软件都可以处理xml
- 可拓展性
在不中断解析、应用程序的情况下进行拓展。 - 可跨平台数据传输
可在不兼容的系统之间进行交换数据,降低了复杂性 - 数据共享方便
XML以纯文本进行存储,独立于软件、硬件和应用程序的数据存储方式,使得不同应用程序、软件和硬件都能访问xml的数据
语法
- 元素要关闭标签
- 1
- 1
- 对大小写敏感
- 1
- 2
- 1
- 2
- 必须要有根元素(父元素)
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
- 属性值必须加引号
- 1
- 2
- 1
- 2
- 实体引用
| 实体引用 | 符号 | 含义 |
|---|---|---|
| <; | < | 小于 |
| > ; | > | 大于 |
| &; | & | 和浩 |
| &apos; | ‘ | 单引号 |
| "; | “ | 双引号 |
元素不能使用&(实体的开始)和<(新元素的开始)
-
注释
<!-- This is a comment --> -
XML的元素、属性和属性值
文档实例
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
其中,是根元素;是子元素,也是元素类型之一;而中含有属性,即category,属性值是CHILDREN;而元素则拥有文本内容( JK.Rowling)
- 元素与属性的差别
属性即提供元素额外的信息,但不属于数据组成部分的信息。
范例一
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
范例二
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
范例一和二提供的信息是完全相同的。
一般情况下,请使用元素,因为
1. 属性无法描述树结构(元素可以)
2. 属性不容易拓展(元素可以)
使用属性的情况:用于分配ID索引,用于标识XML元素。
实例
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
上述属性(id)仅用于标识不同的便签,并不是数据的组成部分
-
XML元素命名规则
- 不能以数字或标点符号开头
- 不能包含空格
- 不能以xml开头
-
CDATA
不被解析器解析的文本数据,所有xml文档都会被解析器解析(cdata区段除外)
- 1
- 1
- PCDATA
被解析的字符数据
XML树结构
XML文档中的元素会形成一种树结构,从根部开始,然后拓展到每个树叶(节点),下面将以实例说明XML的树结构。
- 假设一个XML文件如下
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
其树结构如下
-
XML节点解释
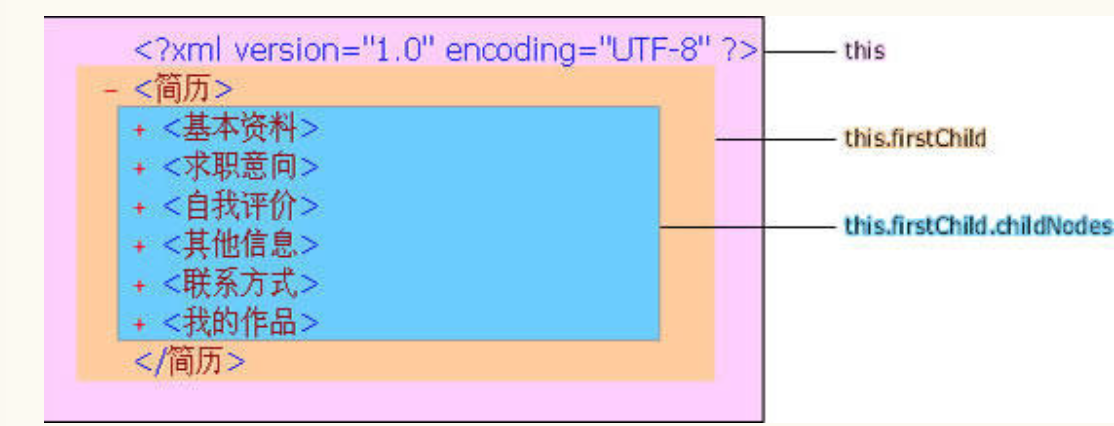
XML文件是由节点构成的。它的第一个节点为“根节点”。一个XML文件必须有且只能有一个根节点,其他节点都必须是它的子节点。
this 代表整个XML文件,它的根节点就是 this.firstChild 。 this.firstChild.childNodes 则返回由根节点的所有子节点组成的节点数组。
每个子节点又可以有自己的子节点。节点编号由0开始,根节点的第一个子节点为 this.firstChild.childNodes[0],它的子节点数组就是this.firstChild.childNodes[0].childNodes 。
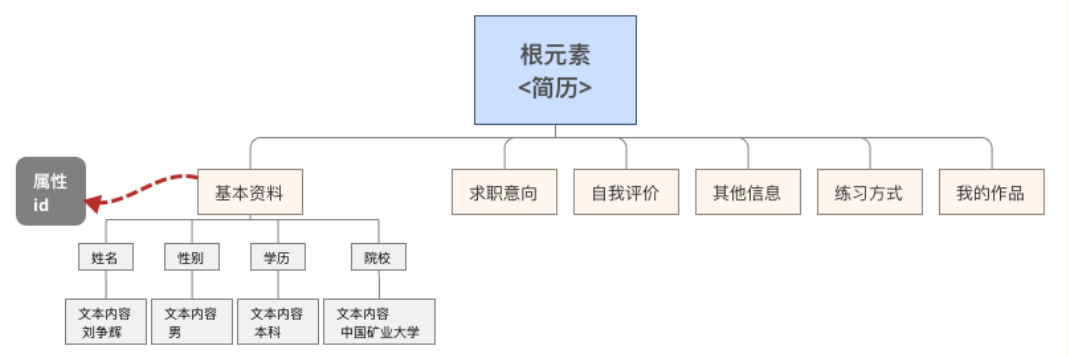
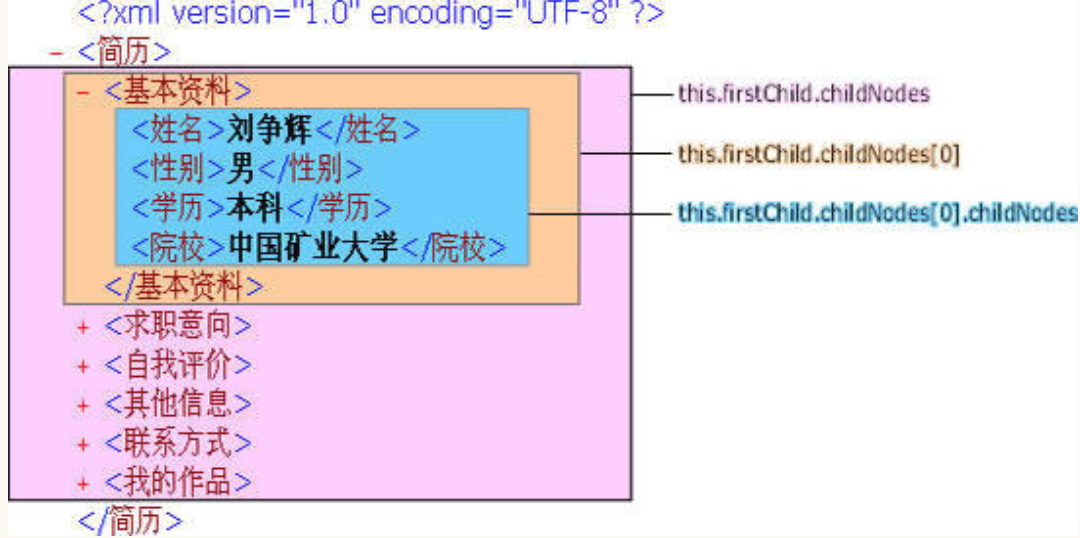
根节点第一个子节点的第二个子节点 this.firstChild.childNodes[0].childNodes[1],它返回的是一个XML对象(Object) 。这里需要特别注意,节点标签之间的数据本身也视为一个节点 this.firstChild.childNodes[0].childNodes[1].firstChild ,而不是一个值。
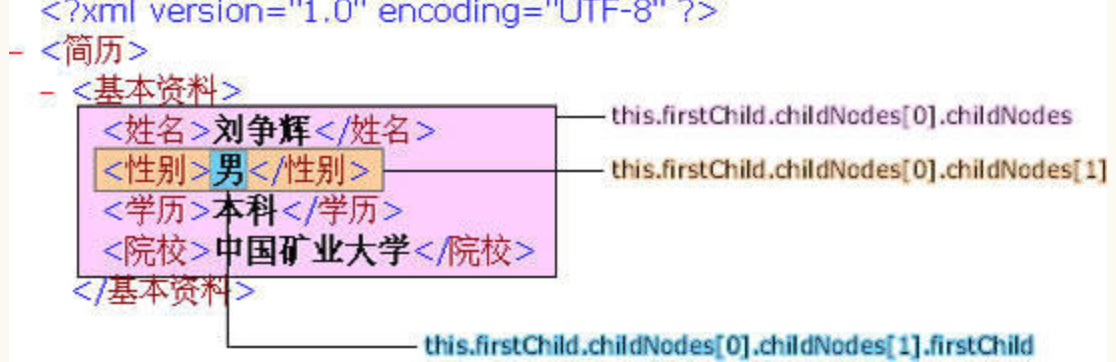
我们解析XML的最终目的当然就是获得数据的值:this.firstChild.childNodes[0].childNodes[1].firstChild.nodeValue 。
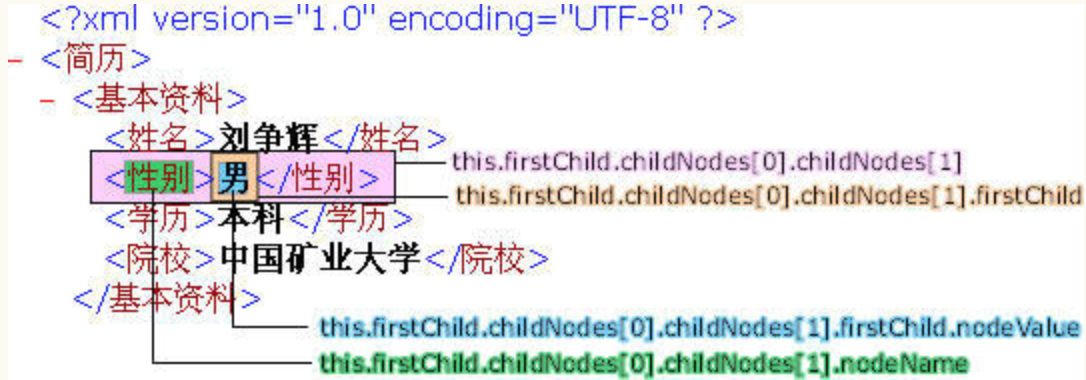
请注意区分:节点名称(<性别>
XML解析
解析XML,即从XML中提取有用的信息
解析方式
基于文档驱动方式
- 主流方式:DOM方式
- 简介:XML DOM(XML Document Object Model),XML文件对象模型,定义了访问和**操作**xml文档元素的方法和接口
- 工作原理: DOM是基于树形结构的的节点的文档驱动方法。使用DOM对XML文件进行操作时,首先解析器读入整个XML文档到内存中,然后解析全部文件,并将文件分为独立的元素、属性等,以树结构的形式在内存中对XML文件进行表示,开发人员通过使用DOM API遍历XML树,根据需要修改文档或检索所需数据
DOM解析
- 假设需要解析的XML文档如下(subject.xml)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 核心代码
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
总结Dom解析的步骤
1、调用 DocumentBuilderFactory.newInstance() 方法得到 DOM 解析器工厂类实例。
2、调用解析器工厂实例类的 newDocumentBuilder() 方法得到 DOM 解析器对象
3、调用 DOM 解析器对象的 parse() 方法解析 XML 文档得到代表整个文档的 Document 对象。
基于事件驱动
- 主流方式:SAX、PULL方式
- 解析方式:可直接根据需要读取所需的JSON数据,不需要像DOM方法把文档先入到内存中
PULL解析
- 工作原理:PULL的解析方式与SAX解析类似,都是基于事件的模式。
PULL提供了开始元素和结束元素。当某个元素开始时,我们可以调用parser.nextText从XML文档中提取所有字符数据,与SAX不同的是,在PULL解析过程中触发相应的事件调用方法返回的是数字,且我们需要自己获取产生的事件然后做相应的操作,而不像SAX那样由处理器触发一种事件的方法从而执行代码。当解释到一个文档结束时,自动生成EndDocument事件。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
SAX解析
- 工作原理:基于事件驱动,在读取XML文档内容时,事件源顺序地对文档进行扫描,当扫描到文档的开始与结束(Document)标签、节点元素的开始与结束(Element)标签时,直接调用对应的方法,并将状态信息以参数的形式传递到方法中,然后我们可以依据状态信息来执行相关的自定义操作。
同样是采用事件驱动进行解析,但相比pull解析方法,采用SAX方式进行XML解析可能会较为复杂,这里就不作实例展示,有兴趣的童鞋们可以自己去尝试下,毕竟实践出真知!
DOM、SAX、PULL三类方式对比
DOM方式
- 原理:基于文档驱动,是先把dom全部文件读入到内存中,构建一个主流内存的树结构,然后使用DOM的API遍历所有数据,调用API检索想要的数据和操作数据。
所以,DOM方式的优缺点是: - 特点:
优点:整个文档树存在内存中,可对XML文档进行操作:删除、修改等等;可多次访问已解析的文档;由于在内存中以树形结构存放,因此检索和更新效率会更高。;
缺点:解析 XML 文件时会将整个 XML 文件的内容解析成树型结构存放在内存中并创建新对象,比较消耗时间和内存; - 使用情境
对于像手机这样的移动设备来讲,内存是非常有限的,在XML文档比较小、需要对解析文档进行一定的操作且一旦解析了文档需要多次访问这些数据的情况下可以考虑使用DOM方式,因为其检索和解析效率较高
SAX方式
- 原理:基于事件驱动,在读取XML文档内容时,事件源顺序地对文档进行扫描,当扫描到文档的开始与结束(Document)标签、节点元素的开始与结束(Element)标签时,直接调用对应的方法,并将状态信息以参数的形式传递到方法中,然后我们可以依据状态信息来执行相关的自定义操作。
- 特点:
优点:解析效率高、占存少、灵活性高
缺点:解析方法复杂(API接口复杂),代码量大;可拓展性差:无法对 XML 树内容结构进行任何修改 - 使用情境
适用于需要处理大型 XML 文档、性能要求较高、不需要对解析文档进行修改且不需要对解析文档多次访问的场合
PULL方式
- 原理:PULL的解析方式与SAX解析类似,都是基于事件的模式。
PULL提供了开始元素和结束元素。当某个元素开始时,我们可以调用parser.nextText从XML文档中提取所有字符数据,与SAX不同的是,在PULL解析过程中触发相应的事件调用方法返回的是数字,且我们需要自己获取产生的事件然后做相应的操作,而不像SAX那样由处理器触发一种事件的方法从而执行代码。当解释到一个文档结束时,自动生成EndDocument事件。 -
特点:
优点:SAX的优点PULL都有,而且解析方法比SAX更加简单
缺点:可拓展性差:无法对 XML 树内容结构进行任何修改 -
使用情境
适用于需要处理大型 XML 文档、性能要求较高、不需要对解析文档进行修改且不需要对解析文档多次访问的场合
同样的使用情景,在SAX和PULL解析方法中,更加推荐PULL方法















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









