









数据预处理有四个任务,数据清洗、数据集成、数据 变换和数据规约。
一、数据清洗
1.缺失值处理
处理缺失值分为三类:删除记录、数据补差和不处理。
数据补插方法:
1. 补插均值/中位数/众数
2. 使用固定值
3. 最近邻补插
4. 回归方法
5. 插值法
插值法介绍:
(1)拉格朗日插值法
python 的Scipy库提供
代码:
#coding=utf-8
import pandas as pd #导入数据分析库Pandas
from scipy.interpolate import lagrange #导入拉格朗日插值函数
inputfile = 'data/catering_sale.xls' #销量数据路径
outputfile = 'tmp/sales.xls' #输出数据路径
data = pd.read_excel(inputfile) #读入数据
#过滤异常值,将其变为空值
row_indexs = (data[u'销量'] < 400) | (data[u'销量'] > 5000) #得到过滤数据的索引
data.loc[row_indexs,u'销量'] = None #过滤数据
#自定义列向量插值函数
#s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
def ployinterp_column(s, n, k=5):
y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))] #取数
y = y[y.notnull()] #剔除空值
return lagrange(y.index, list(y))(n) #插值并返回插值结果
#逐个元素判断是否需要插值
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull())[j]: #如果为空即插值。
data[i][j] = ployinterp_column(data[i], j)
data.to_excel(outputfile) #输出结果,写入文件
插入值为:
(2)牛顿插值法
需要另写,具有承袭性和易于变动节点的特点
(3)Hermite插值
(4)分段插值
(5)样条插值
2.异常值处理
(1)删除有异常值的记录
(2)视为缺失值
(3)平均值修正
(4)不处理
要分析异常值的原因,再决定取舍。
二、数据集成
将多个数据源放在一个统一的数据仓库中。
1.实体识别
同名异义
异名同义
单位不统一
2.冗余属性识别
同一属性多次出现
同一属性命名不一致
三、数据变换
对数据进行规范化处理
1.简单函数变换
原始数据进行数学函数变换,平方、开方、取对数、差分运算。用来将不具有正太分布的数据变换成具有正太性的数据。
时间序列分析中,对数变换或者差分运算可以将非平稳序列转换为平稳序列。
2.规范化
消除指标间量纲影响
(1)最小-最大规范化


(2)零-均值规范化


(3)小数定标规范化


代码:
-*- coding: utf-8 -*-
#数据规范化
import pandas as pd
import numpy as np
datafile = 'data/normalization_data.xls' #参数初始化
data = pd.read_excel(datafile, header = None) #读取数据
min=(data - data.min())/(data.max() - data.min()) #最小-最大规范化
zero=(data - data.mean())/data.std() #零-均值规范化
float=data/10**np.ceil(np.log10(data.abs().max())) #小数定标规范化
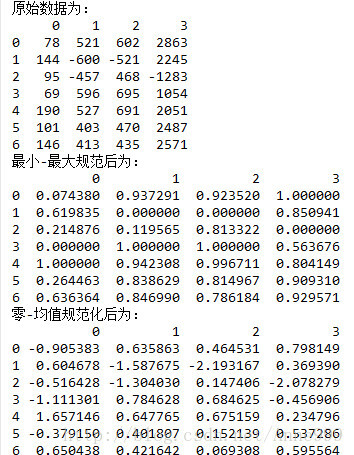
print "原始数据为:\n",data
print "最小-最大规范后为:\n",min
print "零-均值规范化后为:\n",zero
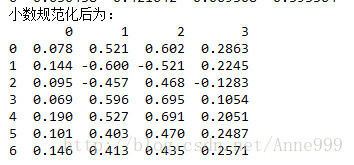
print "小数规范化后为:\n",float运行结果:
3.连续属性离散化
将连续属性变为分类属性,即连续属性离散化。数据离散化本质上通过断点集合将连续的属性空间划分为若干区,最后用不同的符号或者整数值代表落在每个子区间中的数据。离散化涉及两个子任务:确定分类以及如何将连续属性值映射到这些分类值。
(1)等宽法
(2)等频法
(3)基于聚类分析的方法
代码:
#-*- coding: utf-8 -*-
#数据规范化
import pandas as pd
datafile = 'data/discretization_data.xls' #参数初始化
data = pd.read_excel(datafile) #读取数据
data = data[u'肝气郁结证型系数'].copy()
k = 4
d1 = pd.cut(data, k, labels = range(k)) #等宽离散化,各个类比依次命名为0,1,2,3
#等频率离散化
w = [1.0*i/k for i in range(k+1)]
w = data.describe(percentiles = w)[4:4+k+1] #使用describe函数自动计算分位数
w[0] = w[0]*(1-1e-10)
d2 = pd.cut(data, w, labels = range(k))
from sklearn.cluster import KMeans #引入KMeans
kmodel = KMeans(n_clusters = k, n_jobs = 4) #建立模型,n_jobs是并行数,一般等于CPU数较好
kmodel.fit(data.reshape((len(data), 1))) #训练模型
c = pd.DataFrame(kmodel.cluster_centers_).sort(0) #输出聚类中心,并且排序(默认是随机序的)
w = pd.rolling_mean(c, 2).iloc[1:] #相邻两项求中点,作为边界点
w = [0] + list(w[0]) + [data.max()] #把首末边界点加上
d3 = pd.cut(data, w, labels = range(k))
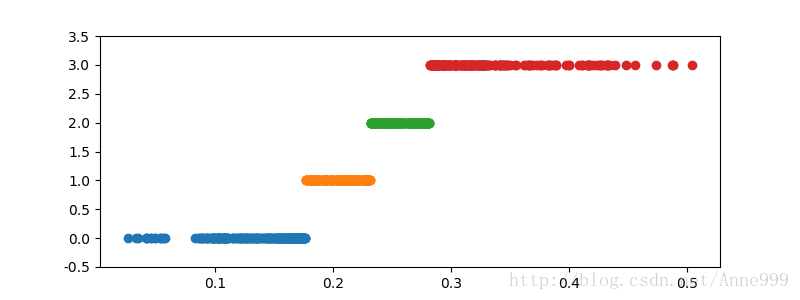
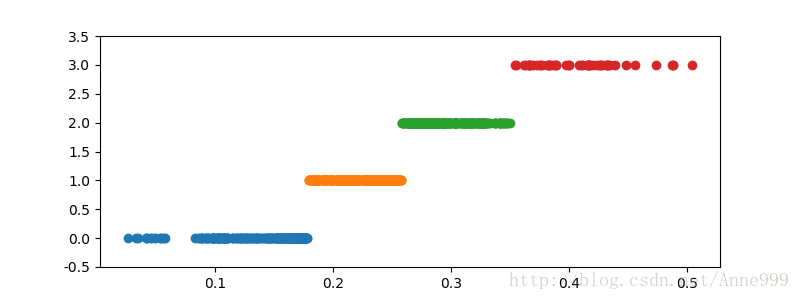
def cluster_plot(d, k): #自定义作图函数来显示聚类结果
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.figure(figsize = (8, 3))
for j in range(0, k):
plt.plot(data[d==j], [j for i in d[d==j]], 'o')
plt.ylim(-0.5, k-0.5)
return plt
cluster_plot(d1, k).savefig("/home/python/syy/images/pic4_1.png")
cluster_plot(d2, k).savefig("/home/python/syy/images/pic4_2.png")
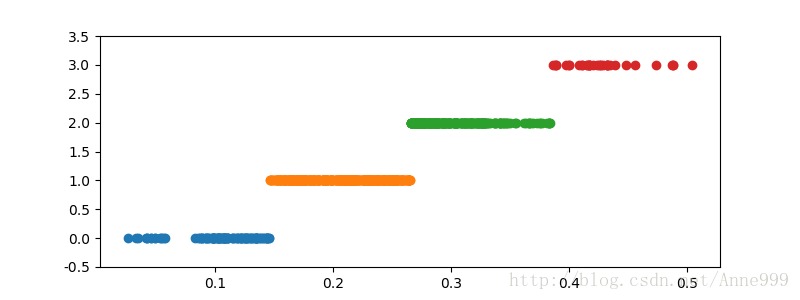
cluster_plot(d3, k).savefig("/home/python/syy/images/pic4_3.png")运行结果:
4.属性构造
利用已有的属性构造新的属性,并加到现有的属性中。
代码:
#coding=utf-8
#-*- coding: utf-8 -*-
#线损率属性构造
import pandas as pd
#参数初始化
datafile= 'data/electricity_data.xls' #供入供出电量数据
outputfile = 'tmp/electricity_data.xls' #属性构造后数据文件
data = pd.read_excel(datafile) #读入数据
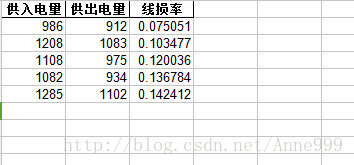
data[u'线损率'] = (data[u'供入电量'] - data[u'供出电量'])/data[u'供入电量']
data.to_excel(outputfile, index = False) #保存结果运行结果:
5.小波变换
非平稳序列的分析手段。
基于小波变换的特征提取方法:
(1)基于小波变换的多尺度空间能量分布特征提取法
(2)基于小波变换的多尺度空间的模极大特征值提取法
(3)基于小波变换的特征提取方法
(4)基于适应性小波神经网络的特征提取方法
代码:
#-*- coding: utf-8 -*-
#利用小波分析进行特征分析
#参数初始化
inputfile= 'data/leleccum.mat' #提取自Matlab的信号文件
from scipy.io import loadmat #mat是MATLAB专用格式,需要用loadmat读取它
mat = loadmat(inputfile)
signal = mat['leleccum'][0]
import pywt #导入PyWavelets
coeffs = pywt.wavedec(signal, 'bior3.7', level = 5)
#返回结果为level+1个数字,第一个数组为逼近系数数组,后面的依次是细节系数数组
………….
四、数据规约
降低无效,错误数据对建模的影响,提高建模的准确性。
少量且代表性的数据将大幅缩减数据挖掘所需时间。
降低存储数据成本。
1.属性规约
- 合并属性
- 逐步向前选择
- 逐步向后删除
- 决策树归纳
- 主成分分析


主成分降维代码:
import pandas as pd
#参数初始化
inputfile = 'data/principal_component.xls'
outputfile = 'tmp/dimention_reducted.xls' #降维后的数据
data = pd.read_excel(inputfile, header = None) #读入数据
from sklearn.decomposition import PCA
pca = PCA()
pca.fit(data)
com=pca.components_ #返回模型的各个特征向量
pca=pca.explained_variance_ratio_ #返回各个成分各自的方差百分比
print com,"百分比:\n",pca运行结果:
[[ 0.56788461 0.2280431 0.23281436 0.22427336 0.3358618 0.43679539
0.03861081 0.46466998]
[ 0.64801531 0.24732373 -0.17085432 -0.2089819 -0.36050922 -0.55908747
0.00186891 0.05910423]
[-0.45139763 0.23802089 -0.17685792 -0.11843804 -0.05173347 -0.20091919
-0.00124421 0.80699041]
[-0.19404741 0.9021939 -0.00730164 -0.01424541 0.03106289 0.12563004
0.11152105 -0.3448924 ]
[-0.06133747 -0.03383817 0.12652433 0.64325682 -0.3896425 -0.10681901
0.63233277 0.04720838]
[ 0.02579655 -0.06678747 0.12816343 -0.57023937 -0.52642373 0.52280144
0.31167833 0.0754221 ]
[-0.03800378 0.09520111 0.15593386 0.34300352 -0.56640021 0.18985251
-0.69902952 0.04505823]
[-0.10147399 0.03937889 0.91023327 -0.18760016 0.06193777 -0.34598258
-0.02090066 0.02137393]]
百分比:
[ 7.74011263e-01 1.56949443e-01 4.27594216e-02 2.40659228e-02
1.50278048e-03 4.10990447e-04 2.07718405e-04 9.24594471e-05]
由此可见,选择三维:
pca=PCA(3)
pca.fit(data)
low_d=pca.transform(data)#降维
pd.DataFrame(low_d).to_excel(outputfile)
pca.inverse_transform(low_d)降维后的数据:
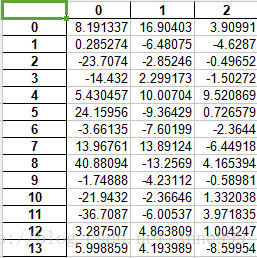
2.数值规约
通过选择替代的、较小的数据来减少数据量,包含有参数方法和无参数方法两类;有参数方法使用模型评估数据,不需要存放真实数据,只需要存放参数,例如回归、对数线性模型。无参数需要数据,例如直方图、聚类、抽样。


五、python中常用数据预处理函数
1.interpolate:一维,高维数据插值
f.scipy.interpolate.lagrange(x,y)
2.unique:去除重复元素
np.unique(D)
D.unique( )
import pandas as pd
import numpy as np
D=pd.Series([1,1,2,3,5])
d1=D.unique()
d2=np.unique(D)
print "d1 is:\n",d1
print "d2 is:\n",d2d1 is: [1 2 3 5]
d2 is: [1 2 3 5]
3.isnull/notnull:判断空值/非空值
4.random:生成随机矩阵
k x m x n维0-1之间;
np.random.rand(k,m,n…)
k x m x n维,正态分布;
np.random.randn(k,m,n)
5.PCA:主成分分析














 2603
2603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









