







https://antkillerfarm.github.io/
花式池化
池化和卷积一样,都是信号采样的一种方式。
普通池化
池化的一般步骤是:选择区域P,令 Y=f(P) 。这里的f为池化函数。
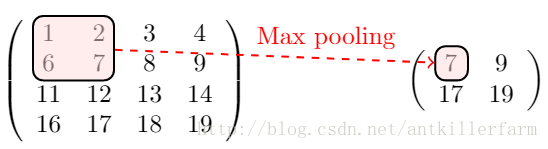
上图是Max Pooling的示意图。除了max之外,常用的池化函数还有mean、min等。
ICLR2013上,Zeiler提出了另一种pooling手段stochastic pooling。只需对Pooling区域中的元素按照其概率值大小随机选择,即元素值大的被选中的概率也大。而不像max-pooling那样,永远只取那个最大值元素。
根据相关理论,特征提取的误差主要来自两个方面:
(1)邻域大小受限造成的估计值方差增大;
(2)卷积层参数误差造成估计均值的偏移。
一般来说,mean-pooling能减小第一种误差,更多的保留图像的背景信息,max-pooling能减小第二种误差,更多的保留纹理信息。
Stochastic-pooling则介于两者之间,通过对像素点按照数值大小赋予概率,再按照概率进行亚采样,在平均意义上,与mean-pooling近似,在局部意义上,则服从max-pooling的准则。
池化的反向传播
池化的反向传播比较简单。以上图的Max Pooling为例,由于取的是最大值7,因此,误差只要传递给7所在的神经元即可。
这里再次强调一下,池化只是对信号的下采样。对于图像来说,这种下采样保留了图像的某些特征,因而是有意义的。但对于另外的任务则未必如此。
比如,AlphaGo采用CNN识别棋局,但对棋局来说,下采样显然是没有什么物理意义的,因此,AlphaGo的CNN是没有Pooling的。
全局平均池化
Global Average Pooling是另一类池化操作,一般用于替换FullConnection层。
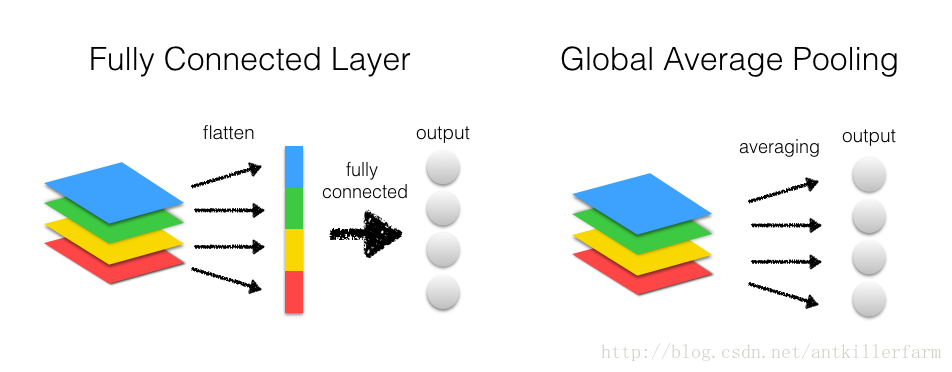
上图是FC和GAP在CNN中的使用方法图。从中可以看出Conv转换成FC,实际上进行了如下操作:
1.对每个通道的feature map进行flatten操作得到一维的tensor。
2.将不同通道的tensor连接成一个大的一维tensor。
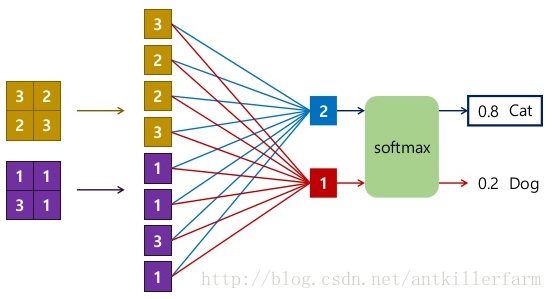
上图展示了FC与Conv、Softmax等层联动时的运算操作。
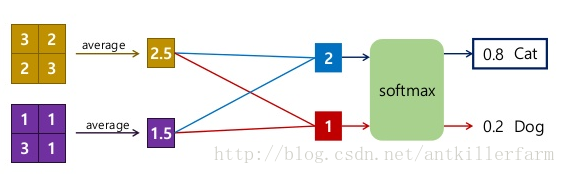
上图是GAP与Conv、Softmax等层联动时的运算操作。可以看出,GAP的实际操作如下:
1.计算每个通道的feature map的均值。
2.将不同通道的均值连接成一个一维tensor。
UnPooling
UnPooling是一种常见的上采样操作。其过程如下图所示:
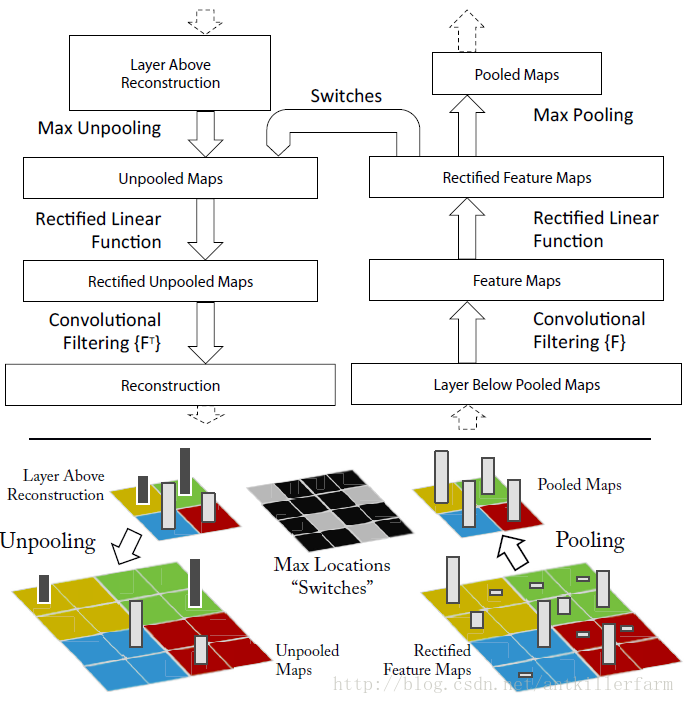
1.在Pooling(一般是Max Pooling)时,保存最大值的位置(Max Location)。
2.中间经历若干网络层的运算。
3.上采样阶段,利用第1步保存的Max Location,重建下一层的feature map。
从上面的描述可以看出,UnPooling不完全是Pooling的逆运算:
1.Pooling之后的feature map,要经过若干运算,才会进行UnPooling操作。
2.对于非Max Location的地方以零填充。然而这样并不能完全还原信息。
参考:
http://blog.csdn.net/u012938704/article/details/52831532
caffe反卷积
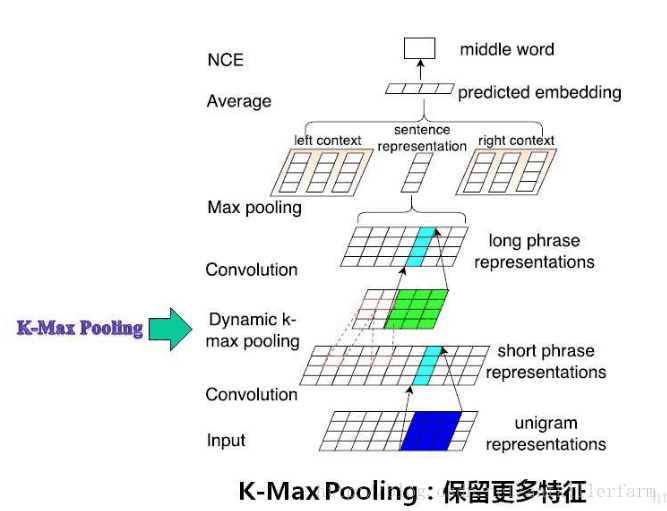
K-max Pooling
参考
http://www.cnblogs.com/tornadomeet/p/3432093.html
Stochastic Pooling简单理解
http://mp.weixin.qq.com/s/XzOri12hwyOCdI1TgGQV3w
新型池化层sort_pool2d实现更快更好的收敛:表现优于最大池化层
http://blog.csdn.net/liuchonge/article/details/67638232
CNN与句子分类之动态池化方法DCNN–模型介绍篇
Batch Normalization
在《深度学习(二)》中,我们已经简单的介绍了Batch Normalization的基本概念。这里主要讲述一下它的实现细节。
我们知道在神经网络训练开始前,都要对输入数据做一个归一化处理,那么具体为什么需要归一化呢?归一化后有什么好处呢?
原因在于神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对数据都要做一个归一化预处理的原因。
对输入数据归一化,早就是一种基本操作了。然而这样只对神经网络的输入层有效。更好的办法是对每一层都进行归一化。
然而简单的归一化,会破坏神经网络的特征。(归一化是线性操作,但神经网络本身是非线性的,不具备线性不变性。)因此,如何归一化,实际上是个很有技巧的事情。
首先,我们回顾一下归一化的一般做法:
其中, x=(x(0),x(1),…x(d)) 表示d维的输入向量。
接着,定义归一化变换函数:
这里的 γ(k),β(k) 是待学习的参数。
BN的主要思想是用同一batch的样本分布来近似整体的样本分布。显然,batch size越大,这种近似也就越准确。
用 B={x1,…,m} 表示batch,则BN的计算过程如下:
Step 1.计算mini-batch mean。
Step 2.计算mini-batch variance。
Step 3.normalize。
这里的 ϵ 是为了数值的稳定性而添加的常数。
Step 4.scale and shift。
在实际使用中,BN计算和卷积计算一样,都被当作神经网络的其中一层。即:
从另一个角度来看,BN的均值、方差操作,相当于去除一阶和二阶信息,而只保留网络的高阶信息,即非线性部分。因此,上式最后一步中b被忽略,也就不难理解了。
BN的误差反向算法相对复杂,这里不再赘述。
在inference阶段,BN网络忽略Step 1和Step 2,只计算后两步。其中, β,γ 由之前的训练得到。 μ,σ 原则上要求使用全体样本的均值和方差,但样本量过大的情况下,也可使用训练时的若干个mini batch的均值和方差的FIR滤波值。
Instance Normalization
Instance Normalization主要用于CV领域。
论文:
《Instance Normalization: The Missing Ingredient for Fast Stylization》
首先我们列出对图片Batch Normalization的公式:
其中,T为图片数量,i为通道,j、k为图片的宽、高。
Instance Normalization的公式:
从中可以看出Instance Normalization实际上就是对一张图片的一个通道内的值进行归一化,因此又叫做对比度归一化(contrast normalization)。
参考:
http://www.jianshu.com/p/d77b6273b990
论文中文版














 651
651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









