









首先通过一张Spark的架构图来了解Worker在Spark中的作用和地位:
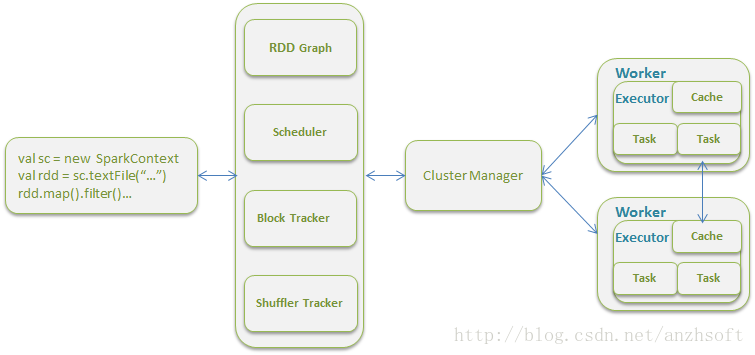
Worker所起的作用有以下几个:
1. 接受Master的指令,启动或者杀掉Executor
2. 接受Master的指令,启动或者杀掉Driver
3. 报告Executor/Driver的状态到Master
4. 心跳到Master,心跳超时则Master认为Worker已经挂了不能工作了
5. 向GUI报告Worker的状态
说白了,Worker就是整个集群真正干活的。首先看一下Worker重要的数据结构:
val executors = new HashMap[String, ExecutorRunner]
val finishedExecutors = new HashMap[String, ExecutorRunner]
val drivers = new HashMap[String, DriverRunner]
val finishedDrivers = new HashMap[String, DriverRunner]这些Hash Map存储了名字和实体时间的对应关系,方便通过名字直接找到实体进行调用。
看一下如何启动Executor:
case LaunchExecutor(masterUrl, appId, execId, appDesc, cores_, memory_) =>
if (masterUrl != activeMasterUrl) {
logWarning("Invalid Master (" + masterUrl + ") attempted to launch executor.")
} else {
try {
logInfo("Asked to launch executor %s/%d for %s".format(appId, execId, appDesc.name))
val manager = new ExecutorRunner(appId, execId, appDesc, cores_, memory_,
self, workerId, host,
appDesc.sparkHome.map(userSparkHome => new File(userSparkHome)).getOrElse(sparkHome),
workDir, akkaUrl, ExecutorState.RUNNING)
executors(appId + "/" + execId) = manager
manager.start()
coresUsed += cores_
memoryUsed += memory_
masterLock.synchronized {
master ! ExecutorStateChanged(appId, execId, manager.state, None, None)
}
} catch {
case e: Exception => {
logError("Failed to launch executor %s/%d for %s".format(appId, execId, appDesc.name))
if (executors.contains(appId + "/" + execId)) {
executors(appId + "/" + execId).kill()
executors -= appId + "/" + execId
}
masterLock.synchronized {
master ! ExecutorStateChanged(appId, execId, ExecutorState.FAILED, None, None)
}
}
}1行到3行是验证该命令是否发自一个合法的Master。7到10行定义了一个ExecutorRunner,实际上系统并没有一个类叫做Executor,我们所说的Executor实际上是由ExecutorRunner实现的,这个名字起得也比较贴切。11行将新建的executor放到上面提到的Hash Map中。然后12行启动这个Executor。13行和14行将现在已经使用的core和memory进行的统计。15到17行实际上是向Master报告Executor的状态。这里需要加锁。
如果在这过程中有异常抛出,那么需要check是否是executor已经加到Hash Map中,如果有则首先停止它,然后从Hash Map中删除它。并且向Master report Executor是FAILED的。Master会重新启动新的Executor。
接下来看一下Driver的Hash Map的使用,通过KillDriver:
case KillDriver(driverId) => {
logInfo(s"Asked to kill driver $driverId")
drivers.get(driverId) match {
case Some(runner) =>
runner.kill()
case None =>
logError(s"Asked to kill unknown driver $driverId")
}
}这个KillDirver的命令实际上由Master发出的,而Master实际上接收了Client的kill driver的命令。这个也可以看出Scala语言的简洁性。















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









