







 本文深入探讨了Spark应用在Standalone集群中Executor的分配过程,从SparkContext创建TaskScheduler开始,详细阐述TaskScheduler如何通过SchedulerBackend与Master交互,如何选择Worker分配Executor,以及Worker如何创建Executor。内容涵盖注册Application、Executor的添加与更新、资源分配策略等关键步骤,揭示了Spark集群资源管理的内部机制。
本文深入探讨了Spark应用在Standalone集群中Executor的分配过程,从SparkContext创建TaskScheduler开始,详细阐述TaskScheduler如何通过SchedulerBackend与Master交互,如何选择Worker分配Executor,以及Worker如何创建Executor。内容涵盖注册Application、Executor的添加与更新、资源分配策略等关键步骤,揭示了Spark集群资源管理的内部机制。
当用户应用new SparkContext后,集群就会为在Worker上分配executor,那么这个过程是什么呢?本文以Standalone的Cluster为例,详细的阐述这个过程。序列图如下:
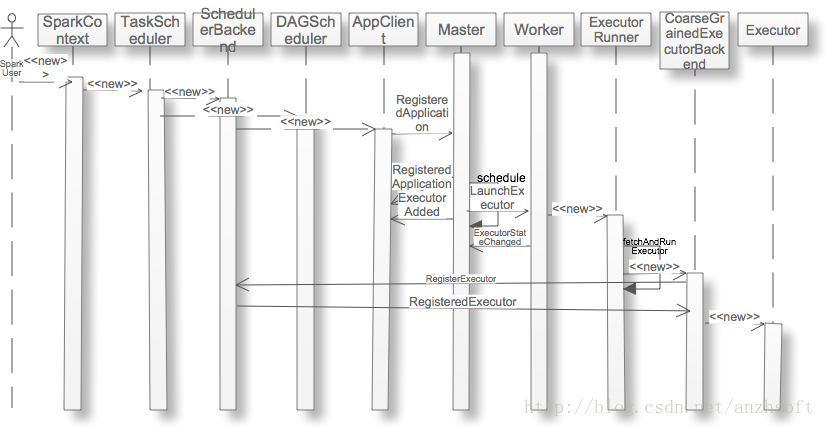
1. SparkContext创建TaskScheduler和DAG Scheduler
SparkContext是用户应用和Spark集群的交换的主要接口,用户应用一般首先要创建它。如果你使用SparkShell,你不必自己显式去创建它,系统会自动创建一个名字为sc的SparkContext的实例。创建SparkContext的实例,主要的工作除了设置一些conf,比如executor使用到的memory的大小。如果系统的配置文件有,那么就读取该配置。否则则读取环境变量。如果都没有设置,那么取默认值为512M。当然了这个数值还是很保守的,特别是在内存已经那么昂贵的今天。
private[spark] val executorMemory = conf.getOption("spark.executor.memory")
.orElse(Option(System.getenv("SPARK_EXECUTOR_MEMORY")))
.orElse(Option(System.getenv("SPARK_MEM")).map(warnSparkMem))
.map(Utils.memoryStringToMb)
.getOrElse(512)除了加载这些集群的参数,它 完成了TaskScheduler和DAGScheduler的创建:
// Create and start the scheduler
private[spark] var taskScheduler = SparkContext.createTaskScheduler(this, master)
private val heartbeatReceiver = env.actorSystem.actorOf(
Props(new HeartbeatReceiver(taskScheduler)), "HeartbeatReceiver")
@volatile private[spark] var dagScheduler: DAGScheduler = _
try {
dagScheduler = new DAGScheduler(this)
} catch {
case e: Exception => throw
new SparkException("DAGScheduler cannot be initialized due to %s".format(e.getMessage))
}
// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler's
// constructor
taskScheduler.start()TaskScheduler是通过不同的SchedulerBackend来调度和管理任务。它包含资源分配和任务调度。它实现了FIFO调度和FAIR调度,基于此来决定不同jobs之间的调度顺序。并且管理任务,包括任务的提交和终止,为饥饿任务启动备份任务。
不同的Cluster,包括local模式,都是通过不同的SchedulerBackend的实现其不同的功能。这个模块的类图如下:

2. TaskScheduler通过SchedulerBackend创建AppClient
SparkDeploySchedulerBackend是Standalone模式的SchedulerBackend。通过创建AppClient,可以向Standalone的Master注册Application,然后Master会通过Application的信息为它分配Worker,包括每个worker上使用CPU core的数目等。
private[spark] class SparkDeploySchedulerBackend(
scheduler: TaskSchedulerImpl,
sc: SparkContext,
masters: Array[String])
extends CoarseGrainedSchedulerBackend(scheduler, sc.env.actorSystem)
with AppClientListener
with Logging {
var client: AppClient = null //注:Application与Master的接口
val maxCores = conf.getOption("spark.cores.max").map(_.toInt) //注:获得每个executor最多的CPU core数目
override def start() {
super.start()
// The endpoint for executors to talk to us
val driverUrl = "akka.tcp://%s@%s:%s/user/%s".format(
SparkEnv.driverActorSystemName,
conf.get("spark.driver.host"),
conf.get("spark.driver.port"),
CoarseGrainedSchedulerBackend.ACTOR_NAME)
//注:现在executor还没有申请,因此关于executor的所有信息都是未知的。
//这些参数将会在org.apache.spark.deploy.worker.ExecutorRunner启动ExecutorBackend的时候替换这些参数
val args = Seq(driverUrl, "{
{EXECUTOR_ID}}", "{
{HOSTNAME}}", "{
{CORES}}", "{
{WORKER_URL}}")
//注:设置executor运行 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1041
1041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









