







中文分词的文章,非常有意思
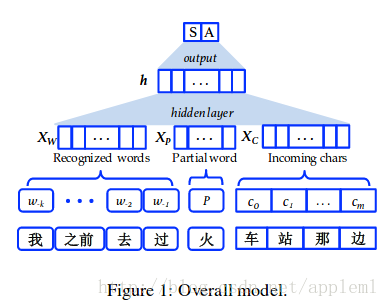
之所以有意思是因为这篇文章将transition-based的方法引入到了neural network, 而且用来分词,当然transition-based用来做parsing的有很多文章,本文的关键问题是如何表示word, P, 和character. 并不是初始化而已,也是本文的创新点,就是pretraining word embedding, P embedding 和 character embedding.
预训练可以看如下图示:
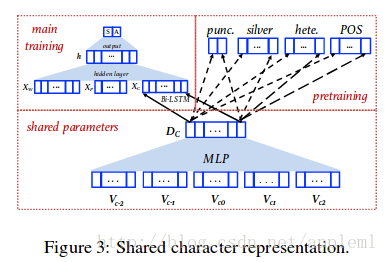
我们以punc.为例,输入序列是5个窗口的字符,输出是判断中间字符之前是否出现标点符号,以此训练字符的embedding, 还有MLP之间的参数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















02-24
 930
930
930
09-17
959
959
05-22
872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









