







前言
梯度下降法(Gradient Descent)是机器学习中最常用的优化方法之一,常用来求解目标函数的极值。
其基本原理非常简单:沿着目标函数梯度下降的方向搜索极小值(也可以沿着梯度上升的方向搜索极大值)。 - 假设需要求解目标函数是
func(x) = x * x的极小值,由于 func 是一个凸函数,因此它唯一的极小值同时也是它的最小值,其一阶导函数 为dfunc(x) = 2 * x。
import numpy as np
import matplotlib.pyplot as plt
# 目标函数:y=x^2
def func(x):
return np.square(x)
# 目标函数一阶导数:dy/dx=2*x
def dfunc(x):
return 2 * x梯度下降法函数
def GD(x_start, df, epochs, lr):
"""
梯度下降法。给定起始点与目标函数的一阶导函数,求在epochs次迭代中x的更新值
:x_start: x的起始点
:df: 目标函数的一阶导函数
:epochs: 迭代周期
:lr: 学习率
:return: x在每次迭代后的位置(包括起始点),长度为epochs+1
"""
xs = np.zeros(epochs+1)
x = x_start
xs[0] = x
for i in range(epochs):
dx = df(x)
# v表示x要改变的幅度
v = - dx * lr
x += v
xs[i+1] = x
return xs- 假设起始搜索点为-5,迭代周期为5,学习率为0.3:
def demo0_GD():
x_start = -5
epochs = 5
lr = 0.3
x = GD(x_start, dfunc, epochs, lr=lr)
print x
demo0_GD()
def demo0_GD():
line_x = np.linspace(-5, 5, 100)
line_y = func(line_x)
x_start = -5
epochs = 5
lr = 0.3
x = GD(x_start, dfunc, epochs, lr=lr)
fig = plt.figure(figsize=(6,6))
color = 'r'
plt.plot(line_x, line_y, c='b')
plt.plot(x, func(x), c=color, label='lr={}'.format(lr))
plt.scatter(x, func(x), c=color, )
plt.legend()
plt.show()
demo0_GD()
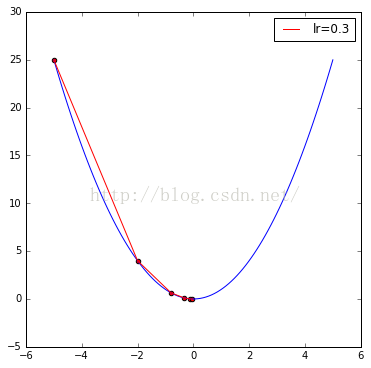
从运行结果来看,当学习率为0.3的时候,迭代5个周期似乎便能得到较理想的效果。
学习率对梯度下降法的影响
- 设置学习率分别为0.1、0.3与0.9进行测试:
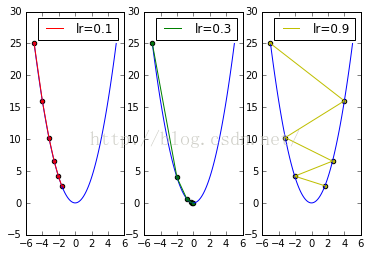
从下图输出结果可以看出两点,在迭代周期不变的情况下:
- 学习率较小时,收敛到正确结果的速度较慢。
- 学习率较大时,容易在搜索过程中发生震荡。
学习率大小对梯度下降法的搜索过程起着非常大的影响! 













 5435
5435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









