







第五周
Neural Networks: Learning
cost function
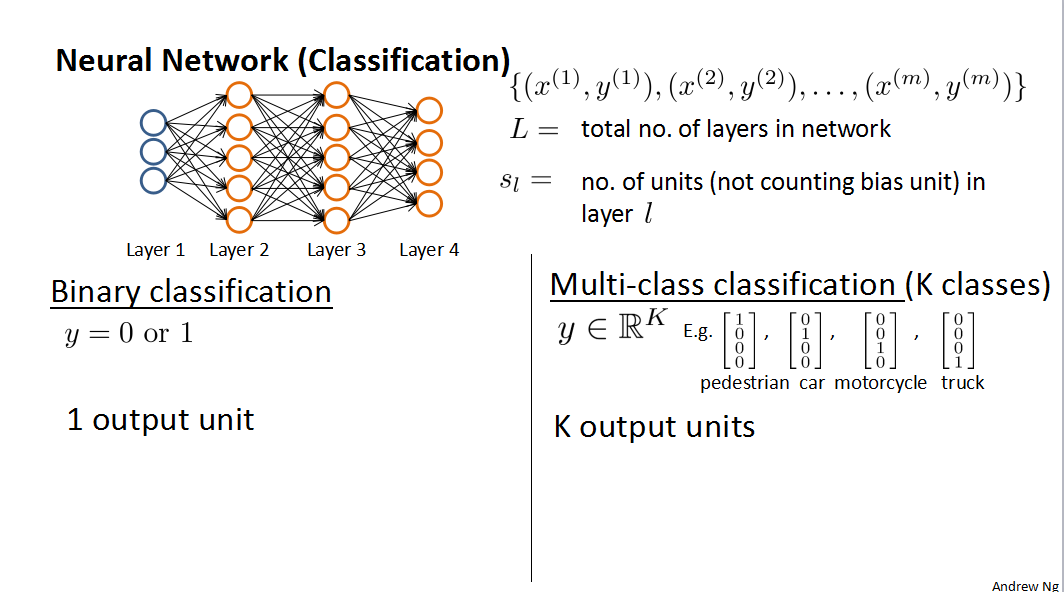
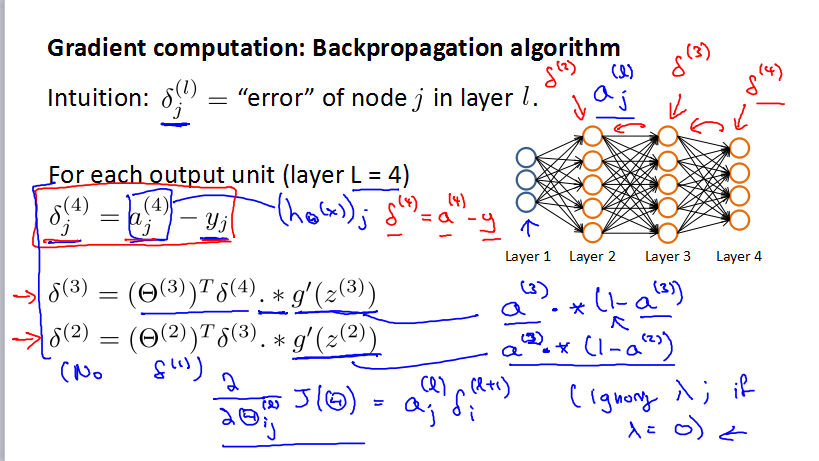
m组数据,图片里面有四层,L=4,最后一层K是输出层的数据,也是sL。Backpropagation algorithm
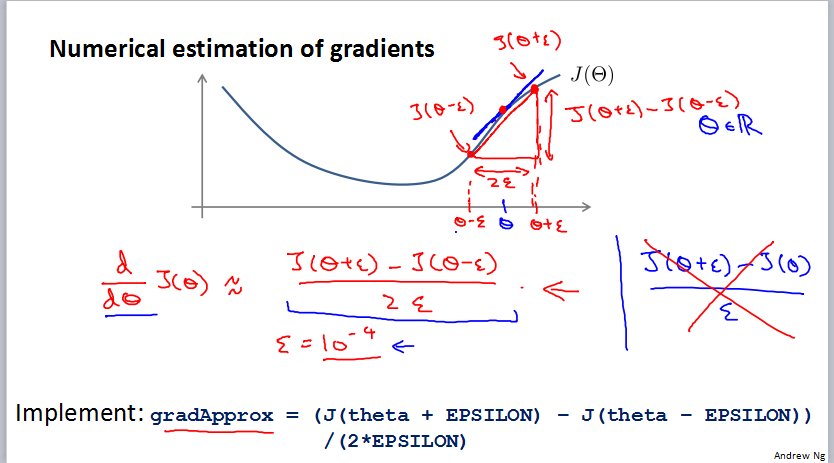
Gradient Checking
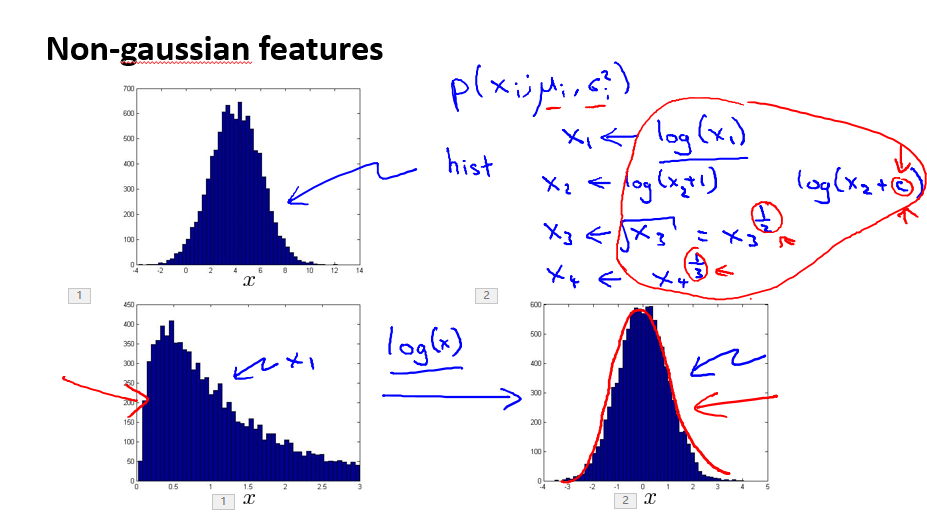
梯度检查是为了检查自己写的代码的确是在梯度下降。第一个是导数的近似替代。
也就是用导数的定义来计算你的算法正确与否。但是替代的这个方法效率很低,所以其实就是实际训练的时候进行屏蔽。
这章主要是介绍一种调试方案吧。

第六周
Advice for applying maching learning
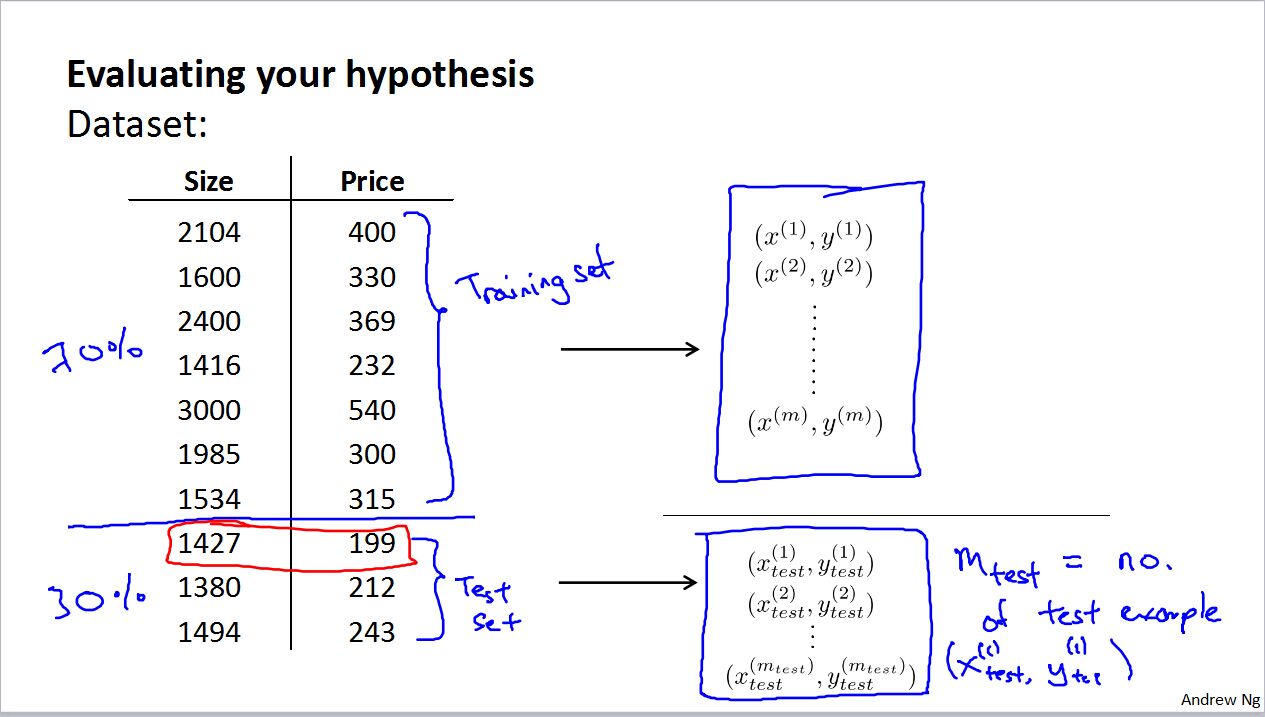
Evaluating a hypothesis
把数据的70%作为training set学习参数,然后再抽取30%作为test set验证误差
Model selection and training/validation/test sets
这里面有一个问题就是,如果训练集作为学习参数的数据集,那么训练集得到的误差会蛮小。那么训练集的误差和测试集的误差相比,就会小很多,为了避免这种情况,有了交叉验证集(cross validation set) 。
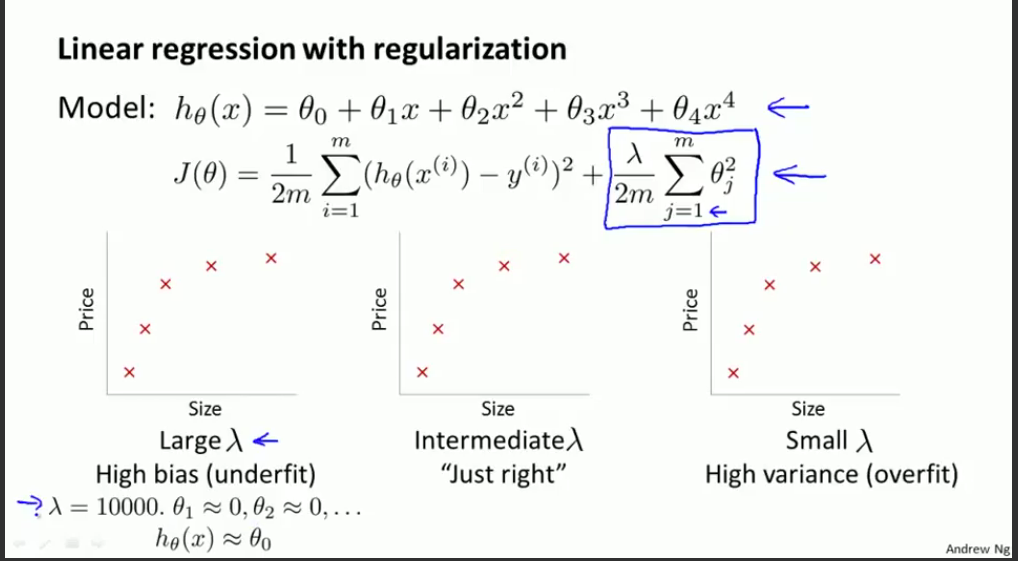
- Bias vs. Variance
这两个翻译成偏差和方差吧。
偏差针对欠拟合,方差针对过拟合。 - Data For Machine Learning
在开始前,收集大量的数据。用不同的算法验证不同大小的训练集。
结果表明,只要训练集够大,那么你的算法的准确性会更高。
所以就有了,取得成功的人不是拥有最好算法而是拥有更多数据的人的一种理论。

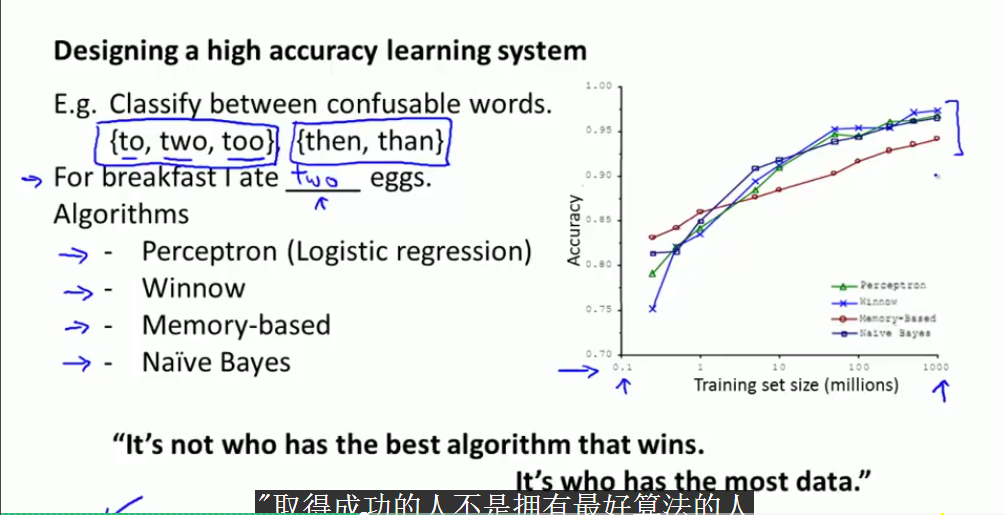
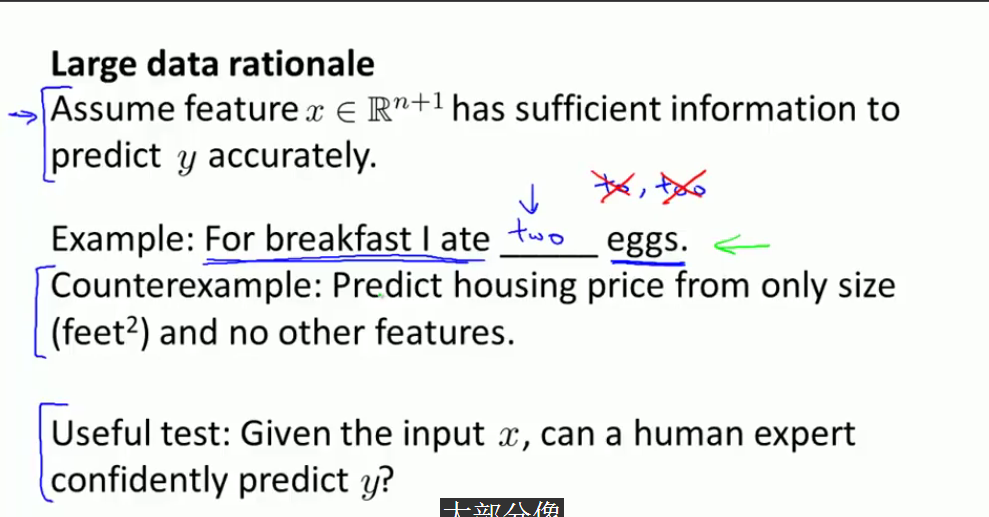
counterexample是反例的意思。也就是思考给定输入数据,对于判定输出数据的合理性问题。所以前提是对于数据集,X的提供的信息要够多。

所以好的结果需要两个条件满足要求,一个条件是具有很多参数的学习算法,另外一个是需要一个相当大的数据集。
第七周 Support Vector Machines
Large Margin Classification
- Optimization objective
这里主要介绍了cost function,从regular逻辑回归到svm的成本函数的区别。
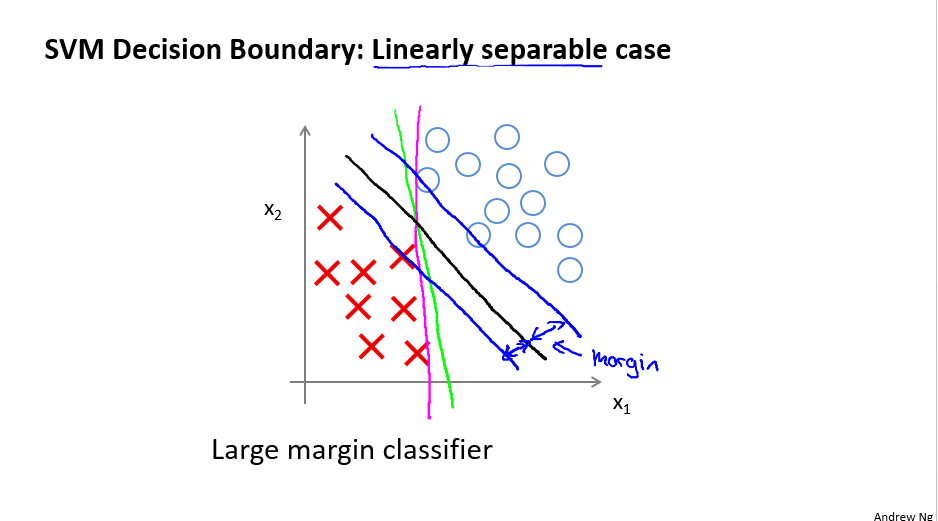
- Large Margin Intuition
这节主要讲了优化函数的意义。
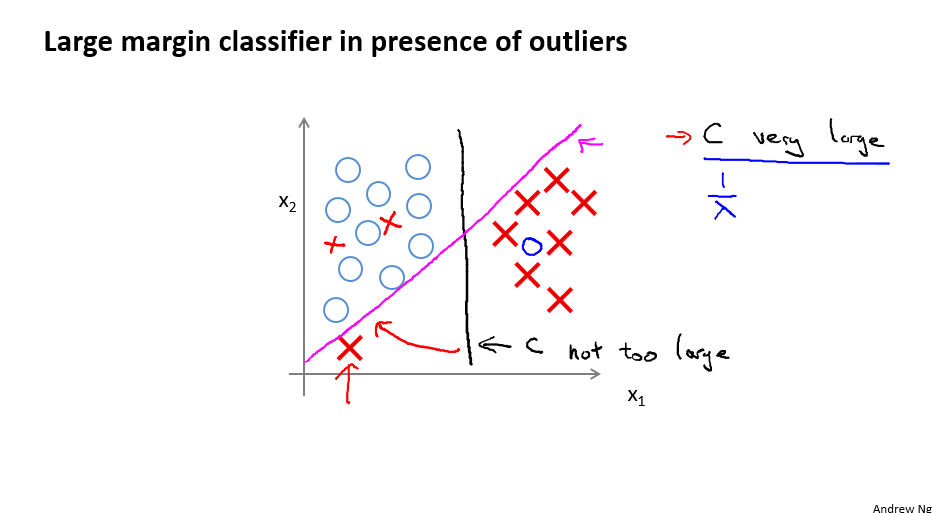
当C比较大的时候,也就是cost function左边的部分比较大,决策边界比起一般的逻辑回归,是从粉红色的线到黑色的线,也就是说,鲁棒性比较好。
当C从小到大,就是黑色的线到粉红色的线,这里想讲的概念是对异常点的处理问题。黑色的线处理效果更好。 - The mathematics behind large margin classification (optional)
这里讲了一些数学原理,主要针对SVM的margin - kernel
核函数决定了cost function,主要讨论了逻辑回归,线性核函数和高斯核函数。以及他们的应用场景。

第八周 无监督学习
clustering
K-means algorithm
聚类讲了最简单的K-means
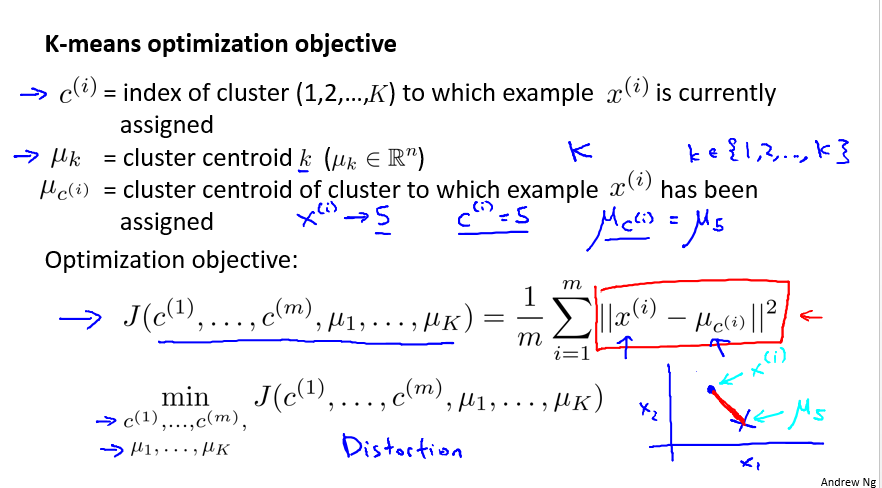
- Optimization objective
优化目标 - Random initialization
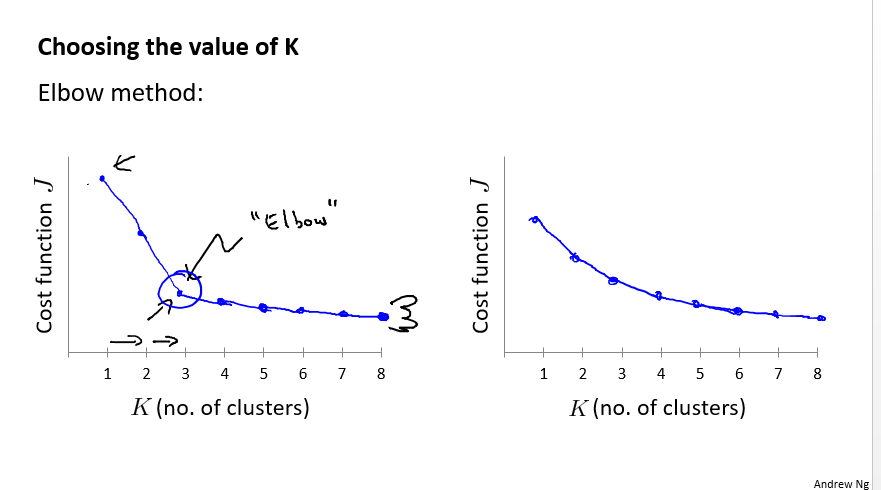
如果k比较小的话,可以多次随机初始化,这样可能得到好的结果,因为不同的初始点,k-means聚类的结果可能并没有那么好。 - Choosing the number of clusters
有两种选择方式,一种是”肘部方法”,选择拐点那个地方
但是很多时候这个方法不适用,那就根据你聚类的目的选择方法。

Dimensionality Reduction
- Principal Component Analysis algorithm
为什么这个算法有效并没有证明,其实知道中间过程也是差不多。 - Advice for applying PCA
这里讲了一下pca的应用情况,一种是加速算法,节约空间,或者是可视化。
与此同时,pca不应该拿来代替正则化。


第八周 异常检测和系统推荐
Anomaly detection
- Gaussian distribution
- Developing and evaluating an anomaly detection system
- Choosing what features to use
- Multivariate Gaussian distribution
- Anomaly detection using the multivariate Gaussian distribution
这里面有一个sigma可逆的问题,多元高斯分布的sigma矩阵前提是可逆的,那就要保证选定的特征m>矩阵的行数或者列数,另外要保证特征不重复或者没有相加关系,就是保证特征行列式不为0把。




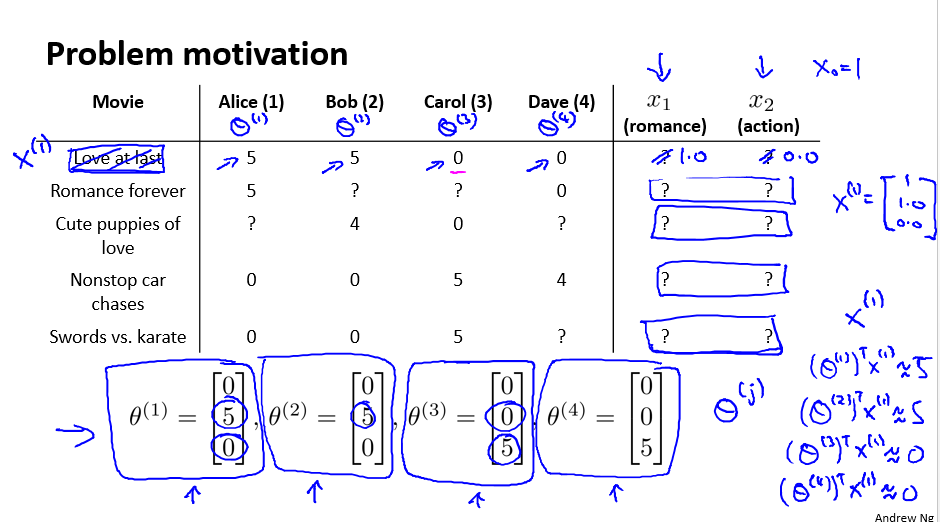
Recommender Systems
- Collaborative filtering
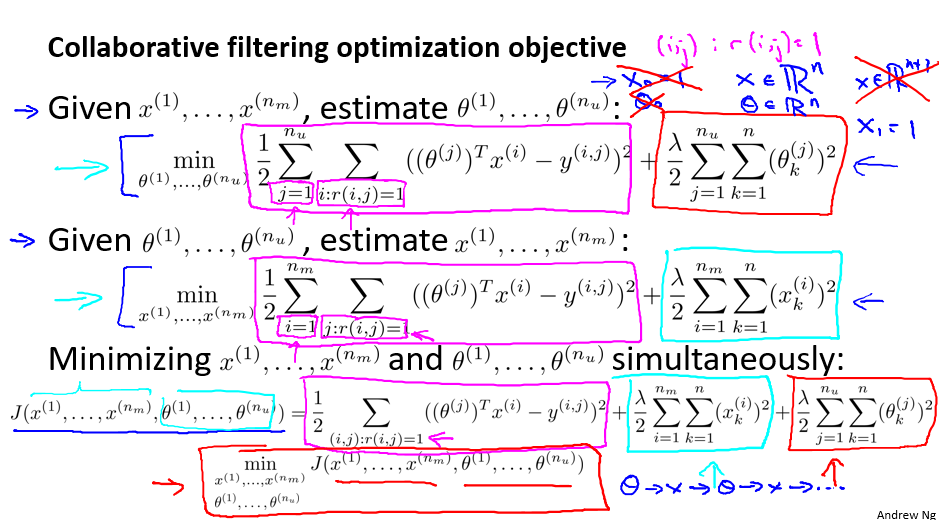
这里举得例子是用户评分的例子,要学习两组参数,一组是用户的特征,另外一组是电影的特征。 - Collaborative filtering algorithm
下面一个是: Mean normalization还有Vectorization: Low rank matrix factorization,不贴了。
第10周Large scale machine learning
- Stochastic gradient descent
batch gradient descent和stochastic gradient descent的区别是,batch是利用全部数据来算,而stochastic是利用一个的数据来算梯度下降。 - Mini-batch gradient descent
它介于上面两者之间,有了p个数据以后迭代一次theta。
- Online learning
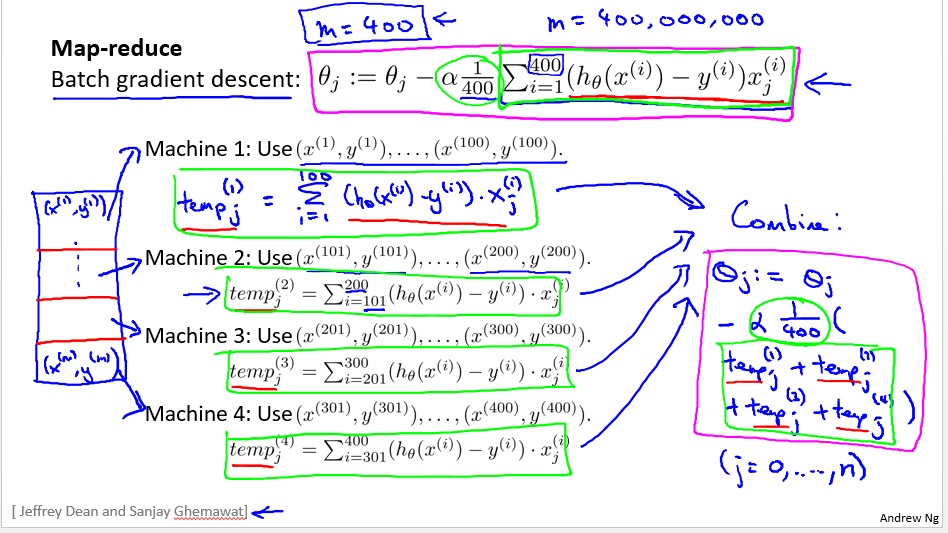
在线学习是针对流数据调整参数,数据是不断地新产生,然后这个集合能够根据数据来不断地进行改变。 - Map-reduce and data parallelism
map-reduce主要针对加法优化,multi-core也是。
然后一些线性代数库会利用计算机的资源自动优化算法。


第11周
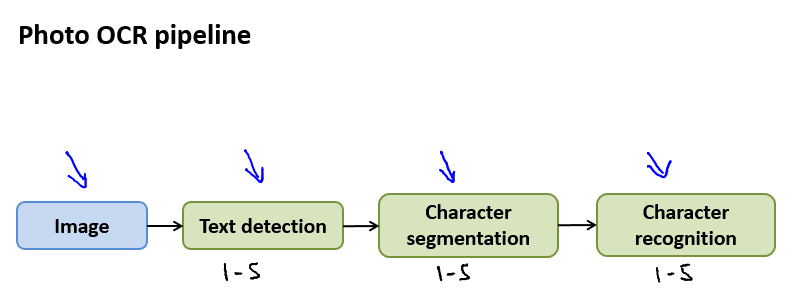
Application Example: Photo OCR
- Problem description and pipeline
pipeline的意思是,就是把一个大问题,分解成很多小问题。
- Getting lots of data: Artificial data synthesis
这里主要讲,如果数据量变大的话,那么你的结果容易变好,那么什么样子的情况下,数据量会变大?
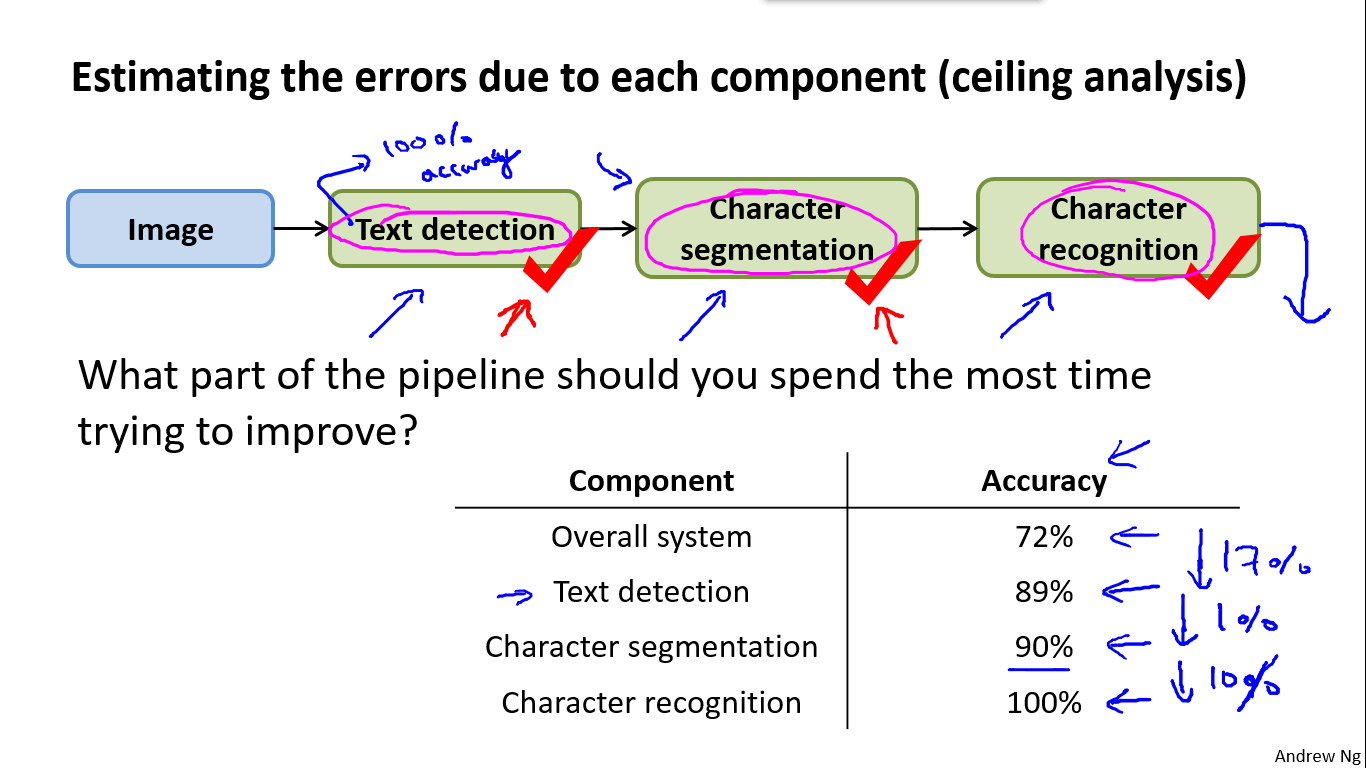
- Ceiling analysis: What part of the pipeline to work on next
就是假定这一模块完全正确,那么它的正确率能够提高多少,也就是上限能够提高的分析,如果能够提高很大的正确率,那么说明这个模块的改进空间很大,反之则不行。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









