







 首先我们先来了解一下什么是管道
首先我们先来了解一下什么是管道
管道用于进程间通信,进程通过管道传输数据,是一种最基本的IPC机制
举个不太恰当的例子哈:就好比你去肯德基买吃的,服务员把你点好的食物放到柜台上,你来取你的食物。服务员把食物放柜台上就相当于一个进程在往管道写数据,你来取食物就相当于另一个进程来管道里读取数据,而柜台就相当于管道。
管道是一个固定大小的缓冲区,一个管道实际上就是个只存在于内存中的文件,对这个文件的操作要通过两个已经打开文件进行,它们分别代表管道的两端。管道是一种特殊的文件,它不属于某一种文件系统,而是一种独立的文件系统,有其自己的数据结构。根据管道的适用范围将其分为:匿名管道和命名管道。
 对匿名管道来说要进行通信要有什么特点呢?
对匿名管道来说要进行通信要有什么特点呢?
(1)一个匿名管道只能进行单向数据通信,如果想双向通信,可以创建两个管道通信
(2)匿名管道只能应用于只能有血缘关系(如父子进程,兄弟进程)的进程,常用于父子进程
(3)匿名管道提供的是流式服务(发送的时候可以发任意个字节,接收的时候也可以接收任意个字节,不受特定格式的约 束)
(4)匿名管道依赖的是文件系统,当进程创建完毕退出后,管道会被系统回收,管道的生命周期随进程
(5)匿名管道给不同的进程提供了同步与互斥的机制,保证读写事件的正确性
(6)匿名管道是存在于内存中的特殊文件
对命名管道来说要进行通信要有什么特点呢?
(1)它可以用于任何两个进程之间的通信,不管这两个进程是不是父子进程,也不管这两个进程之间有没有关系
(2)命名管道是一个可见的设备文件,存在硬盘上
(3)命名管道的通信可看作是一个进程往文件里面写入数据,另一个进程打开文件进行读取数据
(4)进程与创建FIFO的进程不存在亲缘关系,只要可以访问该路径,就能够通过FIFO相互通信
 管道用于进程间通信的初步实现:
管道用于进程间通信的初步实现:
匿名管道:
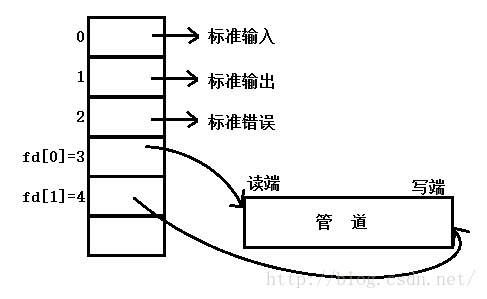
调用pipe函数时在内核中开辟一块缓冲区(称为管道)用于通信,它有一个读端一个写端,然后通过filedes参数传出给用户程序两个文件描述符,filedes[0]指向管道的读端,filedes[1]指向管道的写端(很好记,就像0是标准输入1是标准输出一样)。所以管道在用户程序看起来就像一个打开的文件,通过read(filedes[0]);或者write(filedes[1]);向这个文件读写数据其实是在读写内核缓冲区。pipe函数调用成功返回0,调用失败返回-1
命名管道:
mkfifo函数的作用是在文件系统中创建一个文件,该文件用于提供FIFO功能
int mkfifo(const char *filename, mode_t mode);filename指定了文件名,
而mode则指定了文件的读写权限
命名管道一旦建立,之后它的读、写以及关闭操作都与普通管道完全相同。虽然FIFO文件的inode节点在磁盘上,但是仅是一个节点而已,文件的数据还是存在于内存缓冲页面中,和普通管道相同。
 两个进程在管道中通信的具体实现:
两个进程在管道中通信的具体实现:
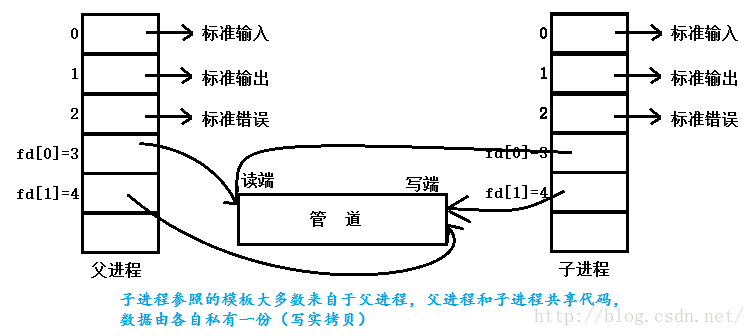
(1)父进程调用pipe或者mkfifo开辟管道,得到两个文件描述符指向管道的两端
(2)父进程调用fork创建子进程,子进程中也有两个文件描述符指向同一个管道
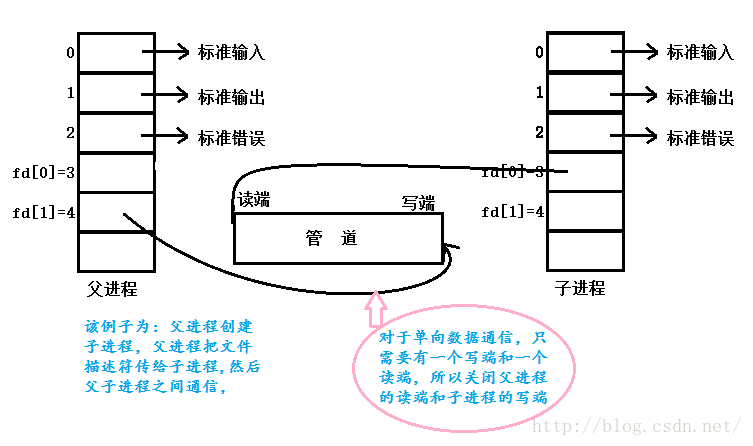
(3)父进程关闭读端,子进程关闭写端,父进程可以往管道里写,子进程可以从管道里读,管道是用环形队列实现的,数据从写端流入从读端流出,这样就实现了进程间通信。
 管道通信的方式:
管道通信的方式:
父进程把文件描述符传给子进程之后父子进程之间通信,也可以父进程创建两个子进程,把文件描述符传给两个子进程,然后两个子进程之间通信, 总之需要通过在创建管道的时候传递文件描述符使两个进程都能访问同一管道,它们才能通信。
 下图为父进程创建一个子进程,父子进程之间通过管道通信的过程
下图为父进程创建一个子进程,父子进程之间通过管道通信的过程
对于匿名管道,创建管道的时候,父进程调用的是pipe函数
对于命名管道,创建管道的时候,父进程调用的是mkfifo函数
 使用单个缓冲区遇到的问题:
使用单个缓冲区遇到的问题:
(1)写端写一部分后不写了并且不关闭写端,读端读完管道里的东西后,读端会以阻塞的方式等待
(2)写端一直写,读端前段时间读,后段时间不读取了,但是也不关闭读端:当管道被写满时,写端会被阻塞
(3)写端写一段时间,不写了,读端一直读,当管道被读空的时候,读端读到文件结尾0,将不会再读
(4)写端一直在写,读段前段时间一直在读,后段时间不读,但是它释放了读端,写端将不会再写,子进程退出,写端将没有意义,写端会收到一个SIGNPIPE信号让进程异常退出,因为异常退出,退出码没有意义
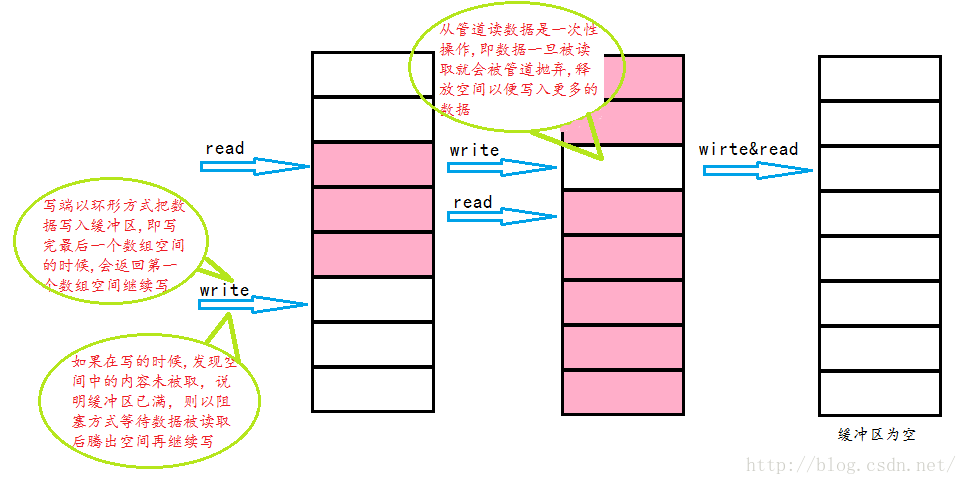
需要注意的是:从管道读数据是一次性操作,即数据一旦被读取,就会被管道抛弃,释放空间以便写入更多的数据
 环形缓冲区
环形缓冲区
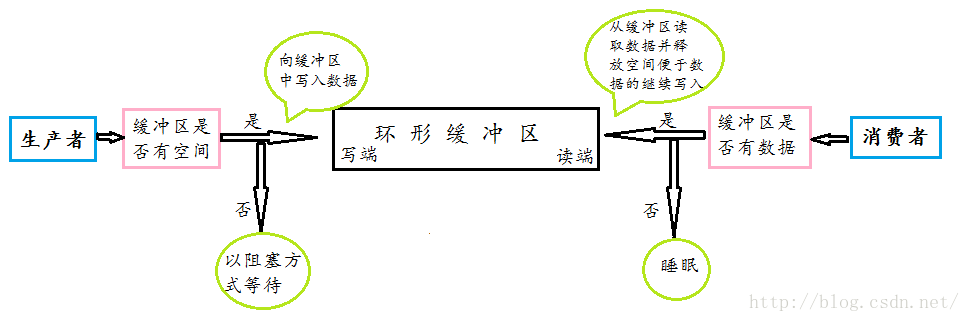
管道是一个固定大小的缓冲区,对于缓冲区,我们在缓冲区内实如何实现读和写的呢?对此,我们用的是环形缓冲区每个管道只有一个页面作为缓冲区,该页面是按照环形缓冲区的方式来使用的。这种访问方式是典型的“生产者——消费者”模型。当“生产者”进程有大量的数据需要写时,而且每当写满一个页面就需要以阻塞方式等待,等待“消费者”从管道中读走一些数据,为其腾出一些空间。相应的,如果管道中没有可读数据,“消费者”进程就要睡眠等待,具体过程如下图所示
 环形缓冲区实现原理:
环形缓冲区实现原理:
环形缓冲区是嵌入式系统中一个常用的重要数据结构。一般采用数组形式进行存储,即在内存中申请一块连续的线性空间,可以在初始化的时候把存储空间一次性分配好。只是要模拟环形,必须在逻辑上把数组的头尾相连接。只要对数组最后一个元素进行特殊的处理——访问尾部元素的下一元素时,重新回到头部元素。对于从尾部回到头部只需模缓冲长度即可(假设maxlen为环形缓冲的长度,当读指针read指向尾部元素时,只需执行read=read%maxlen即可使read回到头部元素)。














 2197
2197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









