







这是参加的第二个kaggle的比赛:facebook V:Predicting Check ins,其与前一阵子Expedia比赛很相似,其预测目标集合都是非常大的。这是比赛入口:https://www.kaggle.com/c/facebook-v-predicting-check-ins。本文可以当做一个简单粗糙的数据挖掘tutorial。
1、关于赛题
比赛题目要求是预测登入用户的地点id,数据集是10km * 10km的方形区域(facebook团队创造的虚拟人工世界)中100,000个地点id的用户相关信息,其中的数据带有程度不定的噪声。提交的文件要求预测test.csv中每一个row_id(8,607,230 个)对应的地点id预测,选手可为每个row_id提供三个预测地点。结果的评估公式如下:
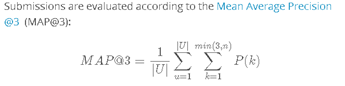
如上所示,评估的公式采用MAP公式,即要求推荐的三个place_id 中没有一个预测正确则不得分。在三个place_id中,有次序关系,若预测正确的place_id次序越前,则得分越高。
2、数据探索
2.1 数据概况:
在对于该数据挖掘问题的方案制定前,需要先对数据进行探索。数据探索有助于对数据有个初步的了解。其中训练数据为1.24G、测试数据为0.27G。机器为8G RAM。故将训练数据数据抽取10,000,000个样本读入内存,了解其概况信息。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df_train = pd.read_csv('../train_sample_10000000.csv')
# 读入文件
## 画分布图
statis_values = df_train['place_id'].value_counts().values
# 统计地点id
place_statis = Series(statis_values, index = range(len(statis_values)))
# 为地点id重新编号
place_statis.plot()
# 绘图
plt.show()
# 显示
## 数据统计描述
print(descirbe(df_train))以下是抽样数据大致的概貌情况:
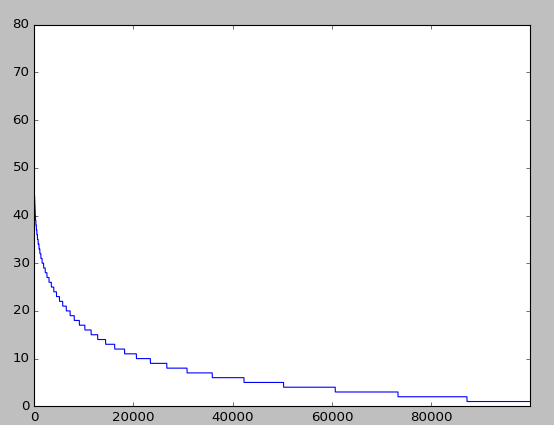
图1:100,000个地点的频数分布
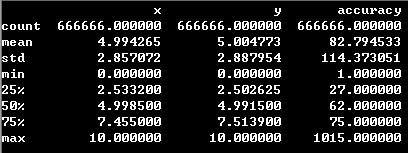
图2:特征的统计特性
如上图所示:由于需要预测的类别集合元素有100,000个,故这种情况不适合使用回归、SVM、神经网络以及决策树等算法直接构建分类器。因为这些算法仅仅在类别数目比较少时才能有效工作。
2.2 问题分解
2.2.1 抽样问题:
由以上观察的数据结果,我们可以对训练数据进行抽样。鉴于训练样本集有大致2千多万条条目,故抽样数据不能够太少,否则会使得抽样后的样本分布对比原分布改变太多。
以下是抽样函数的实现代码:
## 抽样数据集
def pickSample(filename, nSample = 1000000):
df = pd.read_csv(filename)
len_df = len(df.index)
samp_id = sorted(random.sample(range(len_df), nSample))
# 得到随机的抽样id
outputFilename = filename[len(PATH_SAVE) : -4] + '_' + 'sample' + '_' + str(nSample) + '.csv'
# 生成样本数据的文件名
samps_train = df[df.row_id.isin(samp_id)]
samps_train.to_csv(PATH_SAVE + outputFilename, index = False, mode = 'w') pickSample('../train.csv', 1000000)
# 抽取1000000个训练样本2.2.2 地理坐标网格化:
由于训练数据与预测数据的条目非常多,对于任何一个机器学习算法都是一个不小的负担。特别对于在这个地方,尝试通过将x,y地点切分为40*40网格的方型区域,随机其中选取中一个网格进行数据探索。
## 将数据分到相应的网格中去
n_cell_x = 40
n_cell_Y = 40
# x, y尺度归一
size_x = 10.  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2115
2115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









