







阿里妹导读:GC一直是Java应用中讨论的一个热门话题,尤其在像HBase这样的大型在线存储系统中,大堆下(百GB)的GC停顿延迟产生的在线实时影响,成为内核和应用开发者的一大痛点。
过去的一年里,我们准备在Ali-HBase上突破这个被普遍认知的痛点,为此进行了深度分析及全面创新的工作,获得了一些比较好的效果。以蚂蚁风控场景为例,HBase的线上young GC时间从120ms减少到15ms,结合阿里巴巴JDK团队提供的利器——AliGC,进一步在实验室压测环境做到了5ms。本文主要介绍我们过去在这方面的一些工作和技术思想。
背景
JVM的GC机制对开发者屏蔽了内存管理的细节,提高了开发效率。说起GC,很多人的第一反应可能是JVM长时间停顿或者FGC导致进程卡死不可服务的情况。但就HBase这样的大数据存储服务而言,JVM带来的GC挑战相当复杂和艰难。原因有三:
1、内存规模巨大。线上HBase进程多数为96G大堆,今年新机型已经上线部分160G以上的堆配置
2、对象状态复杂。HBase服务器内部会维护大量的读写cache,达到数十GB的规模。HBase以表格的形式提供有序的服务数据,数据以一定的结构组织起来,这些数据结构产生了过亿级别的对象和引用
3、young GC频率高。访问压力越大,young区的内存消耗越快,部分繁忙的集群可以达到每秒1~2次youngGC, 大的young区可以减少GC频率,但是会带来更大的young GC停顿,损害业务的实时性需求。
思路
1. HBase作为一个存储系统,使用了大量的内存作为写buffer和读cache,比如96G的大堆(4G young + 92G old)下,写buffer+读cache会占用70%以上的内存(约70G),本身堆内的内存水位会控制在85%,而剩余的占用内存就只有在10G以内了。所以,如果我们能在应用层面自管理好这70G+的内存,那么对于JVM而言,百G大堆的GC压力就会等价于10G小堆的GC压力,并且未来面对更大的堆也不会恶化膨胀。 在这个解决思路下,我们线上的young GC时间获得了从120ms到15ms的优化效果。
2. 在一个高吞吐的数据密集型服务系统中,大量的临时对象被频繁创建与回收,如何能够针对性管理这些临时对象的分配与回收,AliJDK团队研发了一种新的基于租户的GC算法—AliGC。集团HBase基于这个新的AliGC算法进行改造,我们在实验室中压测的young GC时间从15ms减少到5ms,这是一个未曾期望的极致效果。
下面将逐一介绍Ali-HBase版本GC优化所使用的关键技术。
消灭一亿个对象:更快更省的CCSMap
目前HBase使用的存储模型是LSMTree模型,写入的数据会在内存中暂存到一定规模后再dump到磁盘上形成文件。
下面我们将其简称为写缓存。写缓存是可查询的,这就要求数据在内存中有序。为了提高并发读写效率,并达成数据有序且支持seek&scan的基本要求,SkipList是使用得比较广泛的数据结构。
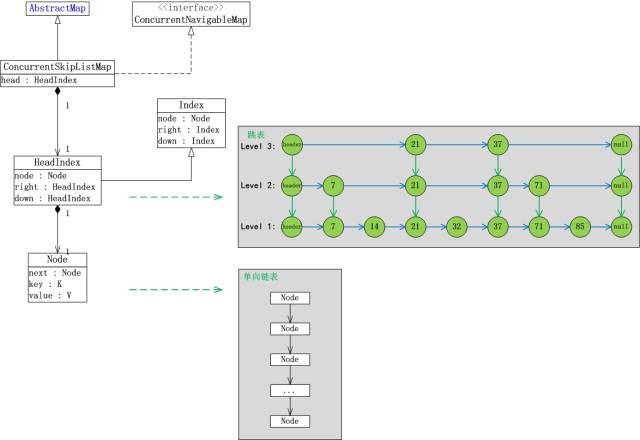
我们以JDK自带的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2970
2970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









