







本发明公开了一种自定制的日志收集系统和方法,该系统包括采集系统、中间服务器、存储系统和负载均衡系统;所述采集系统连接所述中间服务器,所述中间服务器连接所述存储系统,所述存储系统连接所述负载均衡系统。本发明能够对各种数据库系统和应用程序进行定制的日志收集,实时的采集运行日志数据,为分析运行系统的状态和用户操作行为等提供实时的数据,一旦出现系统错误信息会及时的知晓并纠正,同时保障如有用户对系统进行不正当的行为操作,可以及时阻止。
技术领域
[0001 ]本发明涉及对各种系统和应用程序的日志进行收集,并针对不同日志进行自定制和筛选处理的处理方法,具体涉及一种自定制的日志收集系统和方法。
背景技术
[0002]日志的收集就是对各个系统和应用程序产生log文件进行收集,log文件包含了当前的程序的运行状态,报错信息,以及用户的操作信息等。
[0003]目前的日志收集系统和方法包括基于Scribe的收集框架,Chukwa的收集框架,f Iume-OG收集框架。
[0004]其中Scirbe框架是将从各个源将日志收集,集中存储到一个中央存储系统,然后进行集中的统计分析,然而由于在agent和col lector之间没有相应的容错的机制,会导致数据出现丢失的情况,同时它是基于thrift,依赖较为复杂,环境的侵入性较强。Chukwa系统主要是针对各种数据的收集,它包含了很多强大和灵活的工具集,并且能同时分析采集到的数据,所以他的扩展性很好,它较之于Scirbe框架,能定期记录已发送的数据来提供容错机制,和hadoop的集成性也很好,但是由于它的版本较新,并且设计的主要初衷是为了各种数据的收集,导致在日志的收集上并有什么具体的商业扩展,因此无商业应用的采用。Flume-OG框架也是一种三层状态的日志收集系统,agent ,collector ,store三层结构,其中agent负责读取,col lector负责采集过滤,store是存储层。同时通过zookeeper来提供负载,使得相对前两种框架更为的可靠安全,然而由于框架过于冗杂,操作起来不是很方便,开发工作量巨大。
发明内容
[0005]本发明克服了现有技术的不足,针对目前的日志收集系统不具备实时性,高可靠性,和高度自定制问题,从而提出了一种高可靠性的自定制的日志收集系统和方法。
[0006]为解决上述的技术问题,本发明采用以下技术方案:
[0007] —种自定制的日志收集系统,包括采集系统、中间服务器、存储系统和负载均衡系统;所述采集系统连接所述中间服务器,所述中间服务器连接所述存储系统,所述存储系统连接所述负载均衡系统。
[0008]更进一步的技术方案是还包括拦截器,所述采集系统图连接所述拦截器,所述拦截器连接所述中间服务器。
[0009]更进一步的技术方案是采集系统包括至少三个客户采集端。
[0010]更进一步的技术方案是提供一种自定制的日志收集方法,所述的方法包括以下步骤:
[0011 ]步骤一、根据需要采集的日志文件类型确定自定制的数据库系统结构化日志的采集源程序,实现对日志文件的内容拉取功能;
[0012]步骤二、配置需要采集的文件路径;
[0013]步骤三、设置采用的通道类型;
[0014]步骤四、设置拦截器的内容,用于过滤掉不需要的事件;
[0015]步骤五、根据需要采集的客户端数量设计流向中间服务器的定制框架;
[0016] 步骤六、各个客户端实时拉取日志文件内容并实现过滤后写入到通道中;之后,通过组件avrosink发送到中间的服务器的指定端口,中间服务器收到数据并通过自定制的sink发送到目标的消息存储机制里面,完成日志的采集过程。
[0017]更进一步的技术方案是步骤一中自定制的采集源程序步骤包括:
[0018]步骤a.建立采集文件的配置参数类;
[0019]步骤b.实现文件的采集开始和停止方法;
[0020]步骤c.对文件的起始读取点进行配置和保存在positon文件里;
[0021 ] 步骤d.建立一个线程,从posit1n点开始处理,不断发送的日志更新文件内容;
[0022]步骤e.设置容错点,线程每执行10次,将文件当前读取的最后一次pist1n值保存到posit1n文件里面;
[0023]步骤f.为采集的事件添加tiltle字符串,特定标识内容包括:采集所属服务器名称,采集所属应用程序名称,采集所属服务器的IP。
[0024] 更进一步的技术方案是步骤三中所述通道类型包括:Fi Ie类型或memory类型。
[0025]更进一步的技术方案是步骤六中所述消息存储机制包括:数据库、消息序列器或者分布式文件系统。
[0026]与现有技术相比,本发明的有益效果是:本发明能够对各种数据库系统和应用程序进行定制的日志收集,实时的采集运行日志数据,为分析运行系统的状态和用户操作行为等提供实时的数据,一旦出现系统错误信息会及时的知晓并纠正,同时保障如有用户对系统进行不正当的行为操作,可以及时阻止。
附图说明
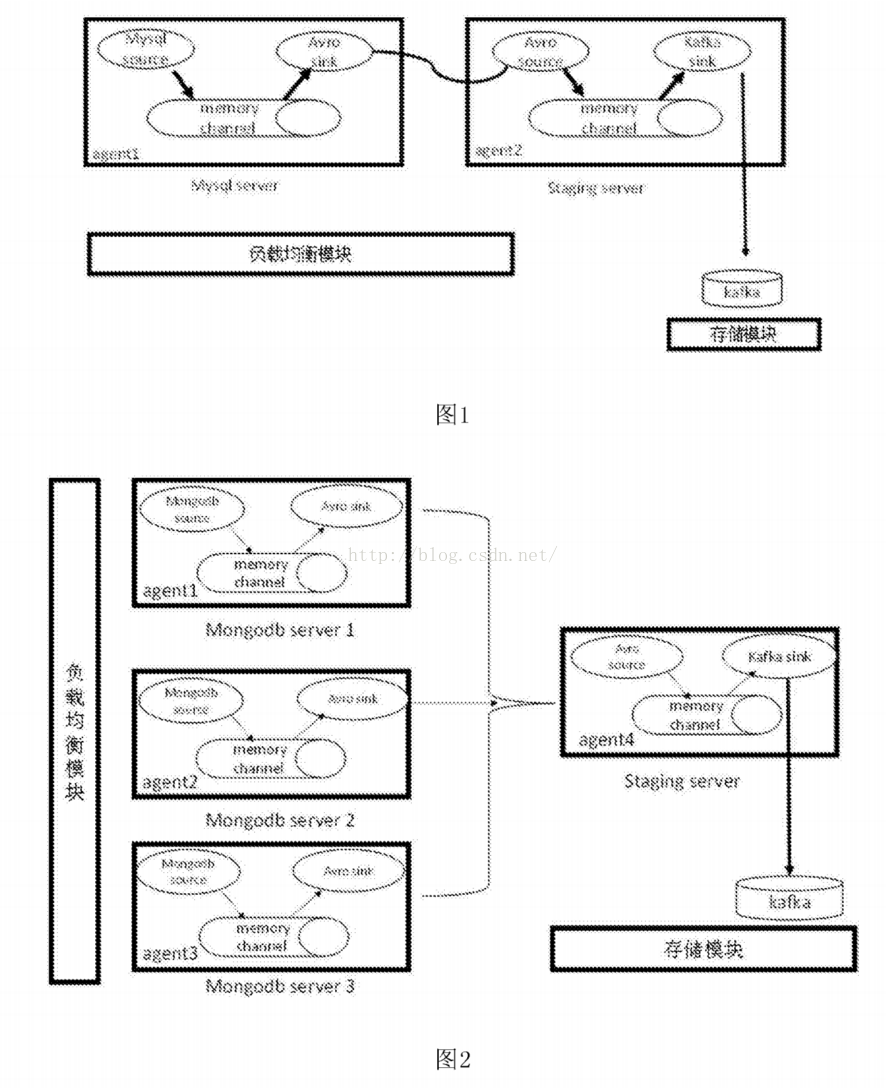
[0027]图1为本发明一个实施例中mysql数据库集群日志收集框架结构示意图。
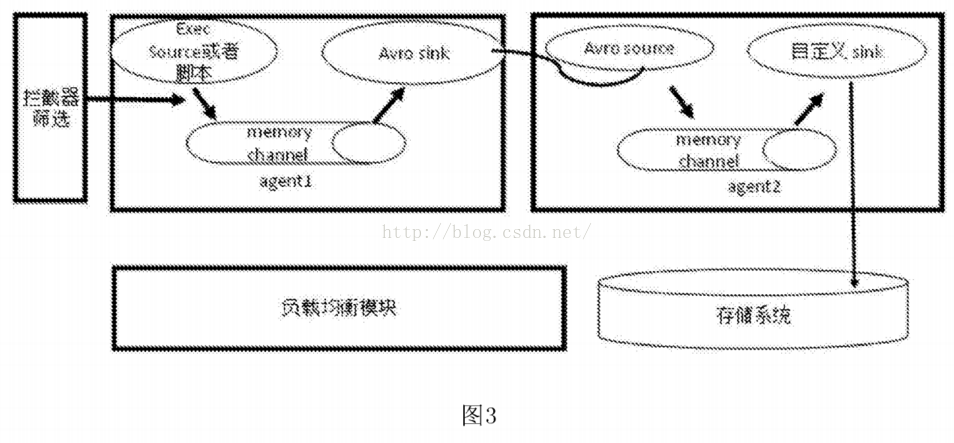
[0028]图2为本发明一个实施例中mongodb数据库集群日志收集框架结构示意图。
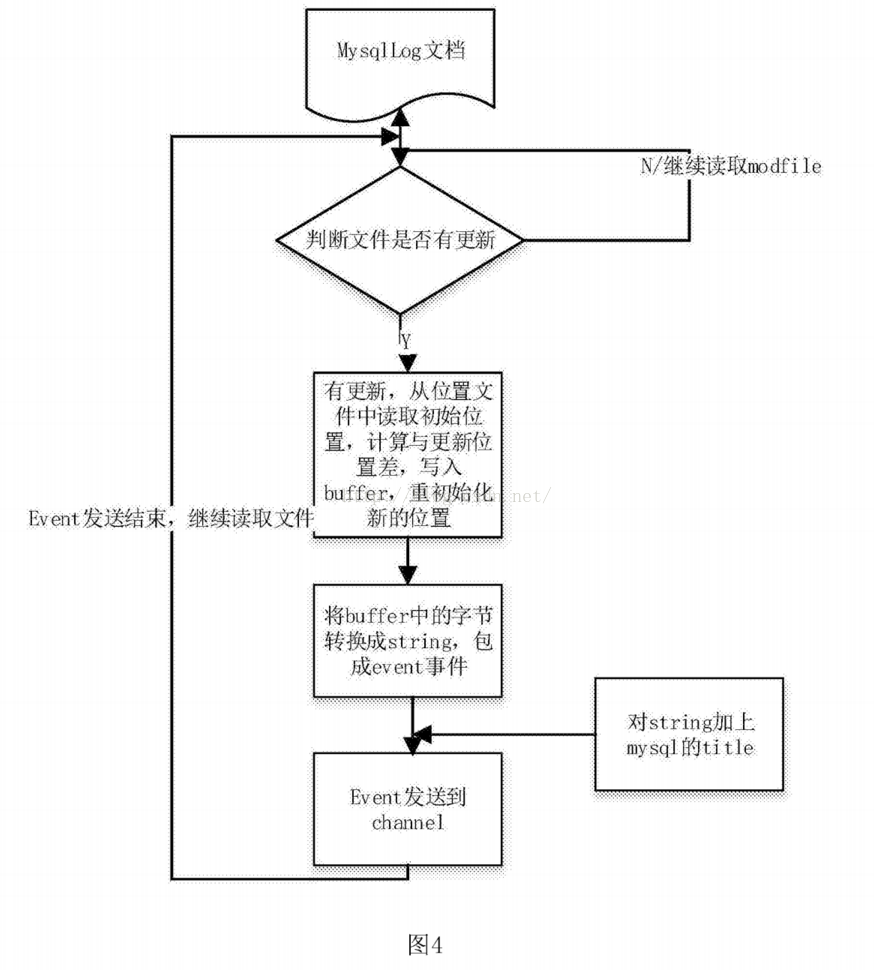
[0029]图3为本发明一个实施例中应用程序非结构化日志收集框架结构示意图。
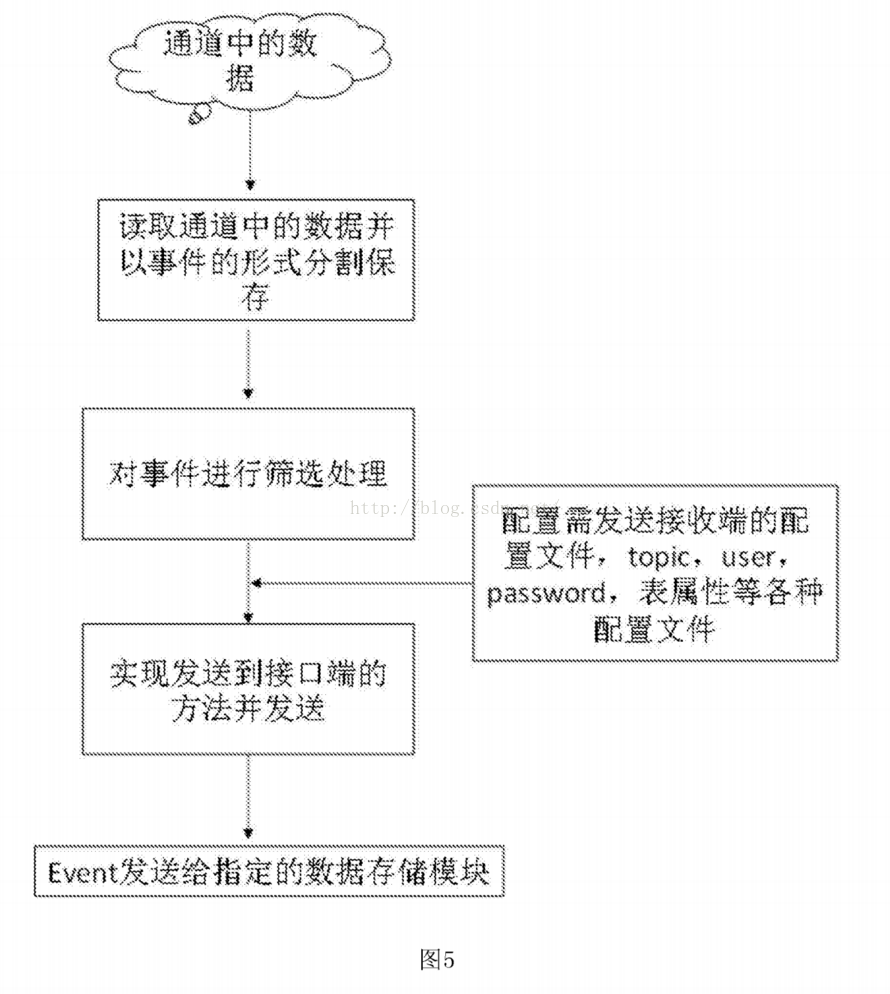
[0030]图4为本发明一个实施例中采集源程序流程图。
[0031]图5为本发明一个实施例中日志筛选写入消息序列流程图。
具体实施方式
[0032]本说明书中公开的所有特征,或公开的所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以以任何方式组合。
[0033]本说明书(包括任何附加权利要求、摘要和附图)中公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换。即,除非特别叙述,每个特征只是一系列等效或类似特征中的一个例子而已。
[0034]下面结合附图及实施例对本发明的具体实施方式进行详细描述。
[0035]根据本发明的一个实施例,本实施例公开一种自定制的日志收集系统,它包括采集系统、中间服务器、存储系统和负载均衡系统;所述采集系统连接所述中间服务器,所述中间服务器连接所述存储系统,所述存储系统连接所述负载均衡系统。
[0036]具体的,如图1所示,图1是对mysql数据库集群产生的日志进行收集的系统架构图,因mysql集群的日志互相连通的,因此采用单流向的框架。该系统包括客户端agent采集平台,中间服务器写入平台,存储系统,负载均衡系统。其中客户端采集平台主要通过自定制的采集源程序负责日志的内容可靠读取,过滤筛选,并传输到中间服务器。中间服务器平台主要是通过自定制开发的发送程序,发送到kafka分布式消息队列里。存储模块就是基于kaf ka的分布式消息系统。
[0037]如图2所示,图2是对mongodb数据库集群查询日志进行收集的系统构架图,采用汇集流向的方式搭建。该系统包括3个客户采集端,一个中间服务器,存储系统,负载均衡系统。其中3个客户采集端,采集了日志后都发送到中间服务器的指定端口,中间服务器用自定制的sin写入到分布式消息队列中。
[0038]如图3所示,图3是应用程序产生的非结构化日志收集的装置和系统架构图。该系统主要由采集客户端,拦截器,负载均衡,中间发送模块,存储模块。首先:
[0039] a)采集客户端,针对不同的应用程序,他们的日志结构是不一样的。因此采用Iinux命令行或者python脚本的方法,直接采集程序的运行状态日志。
[0040] b)使用拦截器,将正确的运行状态过滤掉,直接将error的运行状态截取出来。
[0041] c)将error运行状态以事件的形式发送给具有内网权限的中间服务器。
[0042] d)中间服务器的自定制发送模块可以将收到的事件发送到mongodb,hive,hbase等数据存储模块,以方便处理端进行调取处理。
[0043]根据本发明的另一个实施例,本实施例公开一种自定制的日志收集方法,该方法包括以下步骤:
[0044]步骤一、根据需要采集的日志文件类型确定自定制的数据库系统结构化日志的采集源程序,实现对日志文件的内容拉取功能;
[0045]自定制的采集源程序步骤包括:
[0046]步骤a.建立采集文件的配置参数类;
[0047]步骤b.实现文件的采集开始和停止方法;
[0048]步骤c.对文件的起始读取点进行配置和保存在positon文件里;
[0049] 步骤d.建立一个线程,从posit1n点开始处理,不断发送的日志更新文件内容;
[0050]步骤e.设置容错点,线程每执行10次,将文件当前读取的最后一次pist1n值保存到posit1n文件里面;
[0051]步骤f.为采集的事件添加tiltle字符串,特定标识内容包括:采集所属服务器名称,采集所属应用程序名称,采集所属服务器的IP。
[0052]步骤二、配置需要采集的文件路径;
[0053]步骤三、设置采用的通道类型;
[0054]步骤四、设置拦截器的内容,用于过滤掉不需要的事件;
[0055]步骤五、根据需要采集的客户端数量设计流向中间服务器的定制框架;
[0056] 步骤六、各个客户端实时拉取日志文件内容并实现过滤后写入到通道中;之后,通过组件avrosink发送到中间的服务器的指定端口,中间服务器收到数据并通过自定制的sink发送到目标的消息存储机制里面,完成日志的采集过程。
[0057]具体的,结合附图对本实施例的方法做详细说明。如图4所示,图4是采集源程序的流程图,采集结构化日志的步骤为:
[0058] a)设置一个线程,用于不停的循环读取日志文件内容和发送处理过的的日志。
[0059] b)设置最新的文件大小,从何字节数开始执行读取,存入到posit1n文件中。
[0000] c )读取文档的更新时间,若新的更新时间η ο wmo d f i I e和上次的更新事件Iastmodfile不相等,则表示日志文档已经有新的内容被写入,可以进行实时的读取,以获取最新的日志更新内容。
[0061 ] d)比较当前FiIe和posit1n中的字节大小,读取差值并设置posit1n的值,将posit1n到最新大小之间的日志数据以事件的形式存储到缓存中,并将最新的posit1n的值存入到文件中,下次执行时再次读取比较。
[0062] e)对buffer中的数据进行解码操作,并以string事件的形式分割出每一条日志。
[0063] f)对事件增加title,title的内容包括日志所属服务器,产生日志的系统或者应用程序,日志所属的业务线以及服务器的IP,这样在处理汇集集群产生的日志时候可以很清楚的分辨出是哪个服务器的工作状态出了问题。
[0064] g)将分割好并添加了title的日志传递给发送器模块,不断循环发送到通道中,直到本次buff er里面的数据都发送完毕。
[0065] h)此次发送结束后重新又开始比较文件是否有更新,从b)步骤开始执行。形成了实时的读取文件内容并发送。
[0066]如图5所示,图5是日志被读取到通道后,经过发送端的处理筛选后发送到指定消息序列的流程图。包括以下步骤:
[0067] I)设置管道,并从管道中以事件的形式读取数据。
[0068] 2)将读取的事件做筛选处理,若发送到kafka分布式消息系统,增加发送的Topic等值,若发送到mongodb等数据库,需要设置数据的相关参数。
[0069] 3)将设置好的值用接口的实现方式写入到指定的数据存储模块中。
[0070]本实施例是基于Flume-NG第三方框架的基础上,增加了额外的方法,来实现高可靠性,高度自定制的的日志采集,实现了对非结构化日志和结构化日志的采集,并做简单处理和筛选,能实时的将采集的日志发送到存储系统,为分析处理日志提供良好的保障。本实施例不但继承了Flume-NG框架的优点和底层结构,又可以根据自己的独特需求,自定制更多适合自己的日志采集方案,提高了用户对系统资源的高度利用,还能保障系统的稳定运行,大大提高了用户对日志采集的使用效率。
[0071]在本说明书中所谈到的“一个实施例”、“另一个实施例”、“实施例”等,指的是结合该实施例描述的具体特征、结构或者特点包括在本申请概括性描述的至少一个实施例中。在说明书中多个地方出现同种表述不是一定指的是同一个实施例。进一步来说,结合任一个实施例描述一个具体特征、结构或者特点时,所要主张的是结合其他实施例来实现这种特征、结构或者特点也落在本发明的范围内。
[0072]尽管这里参照发明的多个解释性实施例对本发明进行了描述,但是,应该理解,本领域技术人员可以设计出很多其他的修改和实施方式,这些修改和实施方式将落在本申请公开的原则范围和精神之内。更具体地说,在本申请公开权利要求的范围内,可以对主题组合布局的组成部件和/或布局进行多种变型和改进。除了对组成部件和/或布局进行的变型和改进外,对于本领域技术人员来说,其他的用途也将是明显的。














 2375
2375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









