







在windows10下通过Eclipse远程连接Linux运行hadoop程序wordCount
本Jemp在虚拟机下面安装了一个Centos7系统,并在Centos下搭建了hadoop环境,在Centos7命令行终端运行样例正常,并且自己写的wordCount程序也成功运行。
准备工作:
- 远程机器可以正常运行hadoop程序(本Jemp搭建的是完全分布式系统)
- 本地windows10系统下已安装jdk和Eclipse,能够正常编译运行java项目
- Eclipse安装hadoop插件(安装教程请百度)
- 远程机器的namenode和datanode已开启(Linux通过jps命令可以查看是否开启)
遇到的问题
下面说说本Jemp在捣鼓过程中遇到的一些问题及相应解决方法,如果能够对大家有一点点帮助,也是极好的。
1. 缺少jar包
因为在Windows下面没有安装hadoop,所以在Wordcount程序中提示找不到相关的类
解决方法:
从网上下载hadoop,解压以后,把里面的jar包通过Eclipse里的BuidPath选项(在项目名上面鼠标右键即可看见),然后找到相关的jar包并导入。
其中我导入的jar包如下(hadoop版本2.5+)
先进入hadoop安装的目录下:
cd $HADOOP_HOME
- common目录下的三个jar包
- hdfs目录下的三个jar包
- mapreduce目录下的三个jar包
- tools/lib目录下的所有jar(可能程序里面有些jar包没有用到,但是为了避免出现缺少相关jar包的情况最好还是全部导入吧,当然,如果你对每个jar包的用处熟悉的话可以根据自己的需求来导入相关的jar包)
其实根据路径名大概可以知道这些jar包的用途,比如mapreduce下的jar包就是关于mapreduce运算的,那么我想说明的是tools/lib目录下的jar包是干什么的呢?主要是一些工具类,比如如果你要从命令行读取参数的话需要用到 org.apache.commons.cli.Options这个类,而这个类就是在 tools/lib/commons-cli-***.jar里面,(这里的***表示的是版本号)。
2. 缺少二进制命令文件
提示以下错误
2017-03-10 17:33:22,491 ERROR [main] util.Shell (Shell.java:getWinUtilsPath(397)) - Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable I:\hadoop-common-2.7.1-bin-master\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:379)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:394)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:387)
at org.apache.hadoop.util.GenericOptionsParser.preProcessForWindows(GenericOptionsParser.java:440)
at org.apache.hadoop.util.GenericOptionsParser.parseGeneralOptions(GenericOptionsParser.java:486)
at org.apache.hadoop.util.GenericOptionsParser.<init>(GenericOptionsParser.java:170)
at org.apache.hadoop.util.GenericOptionsParser.<init>(GenericOptionsParser.java:153)
at test.WordCount.main(WordCount.java:63)
2017-03-10 17:33:23,009 WARN [main] util.NativeCodeLoader (NativeCodeLoader.java:<clinit>(62)) - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2017-03-10 17:33:30,903 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(1173)) - session.id is deprecated. Instead, use dfs.metrics.session-id
2017-03-10 17:33:30,905 INFO [main] jvm.JvmMetrics (JvmMetrics.java:init(76)) - Initializing JVM Metrics with processName=JobTracker, sessionId=
Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://192.168.195.135:8020/OutputData already exists
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:146)
at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:266)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:139)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Unknown Source)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1698)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1308)
at test.WordCount.main(WordCount.java:77)解决方法:
参考以下博客:
http://www.cnblogs.com/zq-inlook/p/4386216.html
但是,我配置以后还是有错误。找了一下原来是版本问题,我Centos7上跑的的64位hadoop2.7.3,所以重新找了一个比较新的下载:hadoop-common-2.7.1-bin-master
下载链接:https://github.com/JempChou/Jemp-/blob/master/tools/hadoop-common-2.7.1-bin-master.zip
用这个代替上面博客提供的文件然后配置好环境变量,ok!
3. 提示找不到输入文件
这是我用来测试的wordCount程序代码。
package test;
/**
* * Licensed to the Apache Software Foundation (ASF) under one
* * or more contributor license agreements. See the NOTICE file
* * distributed with this work for additional information
* * regarding copyright ownership. The ASF licenses this file
* * to you under the Apache License, Version 2.0 (the
* * "License"); you may not use this file except in compliance
* * with the License. You may obtain a copy of the License at
* *
* * http://www.apache.org/licenses/LICENSE-2.0
* *
* * Unless required by applicable law or agreed to in writing, software
* * distributed under the License is distributed on an "AS IS" BASIS,
* * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* * See the License for the specific language governing permissions and
* * limitations under the License.
* */
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}在Linux系统上运行时,我已经把本地测试数据put到HDFS上的/InputData目录中了,所以在命令行直接输入执行命令
hadoop jar WordCount.jar wordcount /InputData /OutputData
关于后面三个参数说明(实际上程序中保需要后两个参数):
wordcount :此项目(job)的名称,在WordCount.java中并未引用,但是不可少
/InputData:hdfs上的数据输入目录
/OutputData:hdfs上的数据输出目录(不需提前创建,Hadoop会自动创建)
所以在Eclipse下运行时也需要进行参数配置,方法是,右键——》run as——》run configuration——》Arguments——》program arguments ,当时我的参数配置如下:
/InputData /OutputData
但是,却提示以下错误:
2017-03-10 18:47:34,394 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(1173)) - session.id is deprecated. Instead, use dfs.metrics.session-id
2017-03-10 18:47:34,398 INFO [main] jvm.JvmMetrics (JvmMetrics.java:init(76)) - Initializing JVM Metrics with processName=JobTracker, sessionId=
2017-03-10 18:47:35,024 WARN [main] mapreduce.JobResourceUploader (JobResourceUploader.java:uploadFiles(171)) - No job jar file set. User classes may not be found. See Job or Job#setJar(String).
2017-03-10 18:47:35,035 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:submitJobInternal(249)) - Cleaning up the staging area file:/tmp/hadoop-JempChou/mapred/staging/JempChou325643891/.staging/job_local325643891_0001
Exception in thread "main" org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: file:/InputData
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:323)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:265)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.getSplits(FileInputFormat.java:387)
at org.apache.hadoop.mapreduce.JobSubmitter.writeNewSplits(JobSubmitter.java:301)
at org.apache.hadoop.mapreduce.JobSubmitter.writeSplits(JobSubmitter.java:318)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:196)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Unknown Source)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1698)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1308)
at test.WordCount.main(WordCount.java:77)可以看到第三行错误提示:
Exception in thread “main” org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: file:/InputData
意思是输入路径不存在。
解决办法:
原因出在这两行代码
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));因为是远程连接运行,所以不能直接这样写,需要加上具体的Namenode所在的机器的ip地址与端口号,修改后的参数配置如下:
hdfs://ip地址:端口号/InputData hdfs://ip地址:端口号/OutputData
注意中间的空格。具体的ip地址及端口号要根据你自己来填写。比如ip地址为111.112.113.114,端口号为8020,那么参数配置就应该如下:
hdfs://111.112.113.114:8020/InputData hdfs://111.112.113.114:8020/OutputData
8020是hadoop默认的端口号,查看端口号可以在浏览器中输入
http://具体namenode的ip地址:50070 进行查看,前提是Namenode已经在运行。正常会显示如下:
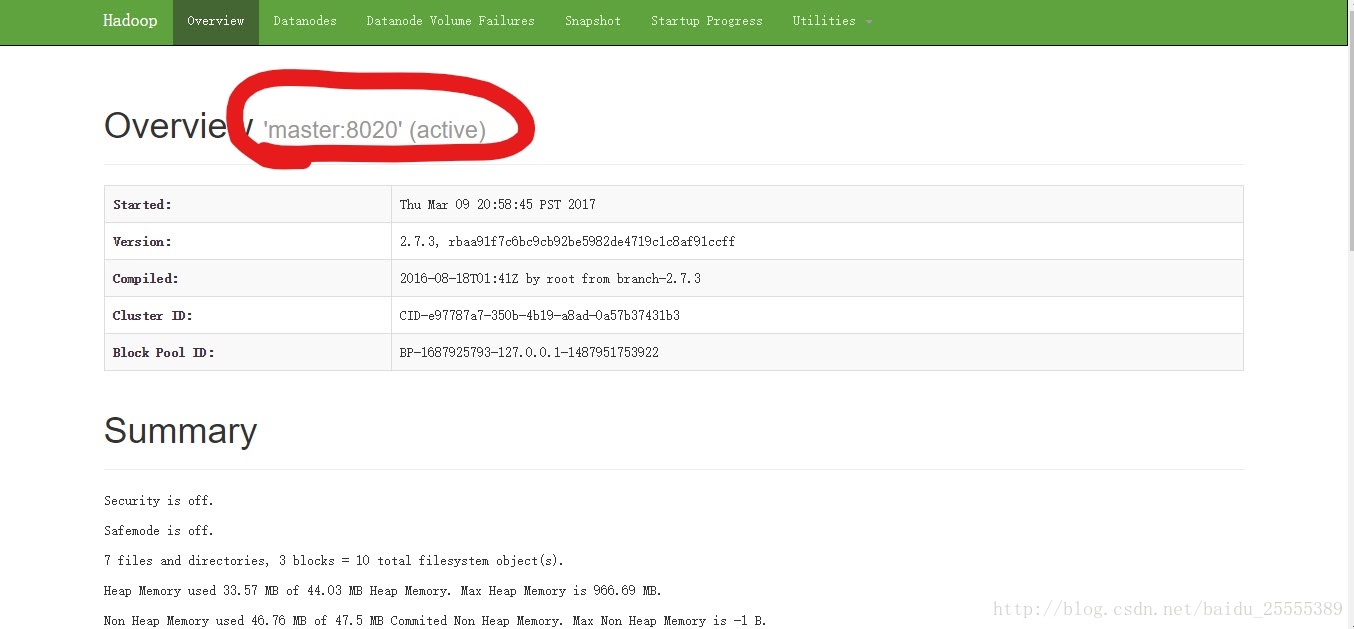
圈圈中的数字便是你的端口号。
好了,我的已经可以正常运行,你的呢?如果有问题,欢迎骚扰^^。














 3548
3548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









