







PRAM 模型
并行计算中的并行随机存取器(PRAM,parallel random access machine)模型是并行架构体系的一种理想化模型,最初由 Fortune 和 Wyllie 在 1978 提出。
PRAM 模型 可以描述为:包含有 p 个同样的RAM处理器,每个都拥有自己的私有内存,并共享一块很大的共有内存。在一个单位时间内,每个处理器能够读取一个全局或局部的内存地址,执行一个单独的RAM操作,以及写入一个全局或局部的内存地址。
PRAM(Parallel Random Access Machine)模型是单指令流多数据流(SIMD)并行机中的一种具有共享存储的模型。它假设有一个无限大容量的共享存储器,并且有多个功能相同的处理器,在任意时刻处理器可以访问共享存储单元。缺点是不现实,首先容量无限大的存储器是不存在的,而且由于各方面的原因,全局访存通常要比预想的慢。其次,他忽略了通信带宽的影响。 优点是结构简单,便于进行理论分析。
PRAM 模型 is very successful as a basis for parallel algorithm design. The model ignores algorithmic complexity of machine connectivity and communication contention, data locality, synchronization, and reliability.
In particular the PRAM model is generally classified into four sub-categories which relate to the use of shared memory:
- EREW : exclusive read, exclusive write
- CREW : concurrent read, exclusive write
- CRCW : concurrent read, concurrent write
- ERCW : exclusive read, concurrent write (shown only for completeness)
An EREW PRAM does not allow simultaneous access to a memory location for read or for write operations.
A CREW PRAM allows simultaneous access for reading but not for writing.
A CRCW PRAM allows simultaneous access for reading and for writing.
并发的写操作,需要一个更进一步的划分来定义冲突处理的方式:
COMMON:一个值可以被写入,当且仅当所有(产生冲突的)处理器都写相同的值(otherwise an error condition may be flagged);
ARBITRARY:在众多产生冲突的处理中,随机选择一个来使其完成写操作(当然这要求算法在无论哪个处理器被选中时都不会出问题);
PRIORITY:在产生冲突的各个处理器中具有最小标识符(lowest identifier)的那个处理器(也就是具有最高优先级的那个)可以执行写操作;
COMBINING:A function of the conflicting values is written; this model requires defining the combining operation.
不同PRAM模型的相互模拟——在EREW PRAM上模拟PRIORITY PRAM CRCW
一条在PRIORITY PRAM CRCW模型(设模型上有n个处理器)上的指令,可以在EREW模型上(同样具有有n个处理器)用O(log n)的时间实现之。(假设we can sort n numbers on an EREW PRAM with n processors in O(log n) time)
证明:令 Q1, Q2, ..., Qn 是PRIORITY PRAM CRCW模型中的处理器,其中 Qk 要读取Mk单元中的内容(或者要向该地址写入内容)。现在指定 P1, P2, ..., Pn 是EREW PRAM 模型上的n个模拟处理器。也就是说我们用 Pk 来尝试模拟处理器Qk ,1<=k<=n,EREW PRAM中的全局存储单元a1, a2, ..., an保留用于特殊用途(在某些资料上通常用一个数组a[n]来指代这n个存储单元,即用数组中的一个元素a[k]来代表ak)。
for k = 1, ..., n,并行地执行如下步骤:
在EREW PRAM,Pk 来设置二元组(Mk, k),并将其存于单元ak,即ak←(Mk, k)。
(*一些资料上的其他说法:
If Qk wants to access Mk processor Pk writes pair (Mk ,k) into a[k].
If Qk does not wants to access any PRIORITY cell, processor Pk writes pair (0,k) int a[k].)
(注意这一步在EREW PRAM上是一个合法的操作步骤,而且执行时间为O(1))
现在用EREW PRAM上所有的处理器(共n个)对 a1, a2, ..., an中存储的n个二元组(Mk, k)进行排序(先根据memory location Mk再根据k来排序),其中1<=k<=n,这一步根据我们最开始给出的假设需要花费的时间为O(log n)。
for k = 1, ..., n,并行地执行如下步骤:

(*一些资料上的其他说法:每一个Pk appends to cell a[k] a flag f:
f = 1,如果the first component of a[k] ≠ the first component of a[k-1]
or the first component of a[k] ≠ 0
f = 0,otherwise)
现在二元组(或者三元组中的前两个数)(Mk ,k) 就可以被组织成一些块,使得每块中的二元组都具有相同的第一个分量(Mk,即全局存储单元的地址);每块的代表(也即是排在块组中最前面的一个)具有最小的第二分量,它可以在O(1)时间内选出。(本小节最后给出了更便于理解的示例)这样,在EREW PRAM上,处理器 Pk 就可以在O(1)的时间内并行地对由“三元组”所指定的单元进行读或者写操作。
PRIORITY WRITE: 每一个Pk读取三元组(Mk, k, f) from cell a[k] and writes into Mk iff f = 1.
最后是一个例子:你可以看到经过排序后,二元组被分成了四块,即[(0, 7)]、[(1,4)]、[(2,1), (2, 3), (2, 6)]、[(4,2), (4,5)]。其中每块的第一个分量都相同,它是要读取或者要写入的全局地址,第二分量则是优先级排序,排在最前的也是该块的代表,它具有最高优先级。

工作量与加速比
现在,设S为一个待处理的问题,其输入的大小为n,S能够在PRAM上使用p(n)个处理器,用一个并行算法在t(n)个步骤内求解。
那么被这个并行算法所处理的工作量就用w(n)=t(n)p(n)来表示。任何PRAM算法所执行的工作量w(n)都可以转化成一个在w(n)时间内执行的串行算法,只要用一个处理器模拟执行PRAM中的所有并行步骤即可。
直觉上来说,当程序规定时,一个并行的执行通常意味着更短的耗时,这一点可以用加速因子(speedup factor)来表示:

其中,p是处理器的数量,ts是串行执行的时间,tp是并行执行的时间。在实际中,时间通常是指挂钟时间。但是对于PRAM算法来说,我们所说的时间通常是指算法执行步骤的多少。
阿姆达尔定律(Amdahl’s Law)
阿姆达尔定律(Amdahl’s Law)是一条用以阐释并行计算所能达到之基本极限的法则,it is formulated by 美国计算机科学家 Gene Amdahl in 1967。或者说,Amdahl’s Law是一种给定问题规模的前提下,用以预测(或估计)最大可达的加速因子(或称加速比)的方法。
如果 ts 是串行执行的时间,f 是其中不能被并行化的部分所占之比例,那么当处理器数量为p时,最大加速比(the maximum speedup)就是
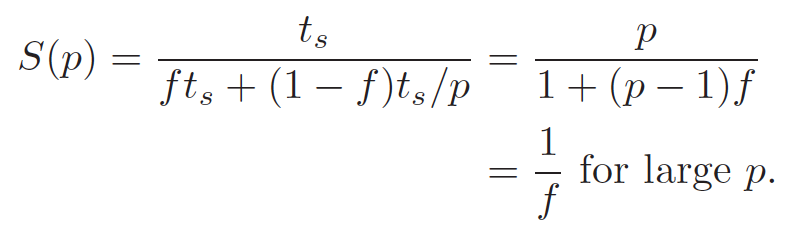
注意,下面这种(文献2中所采用的)表述与上面这种是一致的(只要将分子分母同时除以p即可):

Amdahl’s Law给出了在一个系统中,基于可并行化和串行化的组件各自所占之比重,程序通过获得额外的计算机资源,理论上能够获得的最大加速。
推荐阅读与参考文献:
【1】陈国良,并行算法的设计与分析(第3版),高等教育出版社,2009
【2】Dr Aaron Harwood,The University of Melbourne 并行与多核计算课程材料
【3】左飞,代码揭秘:从C/C++的角度探秘计算机系统,电子工业出版社
【4】http://pages.cs.wisc.edu/~tvrdik/2/html/Section2.html#Simulation2















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











