






| 作者:吕震宇 |
什么是并发问题?假设有这么一家书吧,顾客可以到那里喝茶读书。顾客拿着选好要读的图书到柜台登记,然后找个地方去阅读,临走时将图书归还店家。有一天,一个顾客相中了一本书后正要拿去登记,另一个顾客的手也抓住了这仅有的一本书,并发问题出现了。两个顾客要读同一本书,互不相让,这让店主伤透了脑筋。这个案例仅仅是众多并发问题中的一个微小部分,但从中我们可以看出并发问题主要出现在多个用户对有限资源进行访问的时候,如果解决不好会直接影响系统的有效、正常运行。数据库是一个共享的资源,并发问题的出现是必不可免的,如何识别并发类型并加以控制是这一章重点要讲述的内容。
本章将分成两大部分,一部分主要讲Visual FoxPro中并发控制机制。VFP中并发控制相对简单,数据加锁的形式比较单一,非常适合作为初步了解并发问题的切入点。第二部分以SQL Server 2000、ADO.NET以及C#为主要工具,深入了解并发一致性问题、封锁协议、事务隔离等内容,难度相对较深。象一些更为深入的并发控制手段,例如多粒度封锁和意象锁等内容在本章中将不做深入讨论,感兴趣可以参考相关书籍。
2.1 Visual FoxPro中并发控制机制
2.1.1 独占访问
对于上面提出的问题有没有解决办法呢?当然有。一种办法就是"独占访问"―任何时刻你的书吧中只能有一位顾客读书,他可以尽情的挑选钟爱的书籍而决不用担心谁会与他争夺资源。当他读完书走后,下一个顾客才能进来,当然一次只能进一个。你可能会笑,说哪个商家会笨到如此地步。其实如果你的书店一天只有两三个顾客光顾的话,这么做到也无妨:。
如果把书店映射成数据库中的一张表,每本书对应表中的一条记录,那么我们就可以对数据库表应用"独占访问"了。一旦某张表被独占,其它人就无法进行访问,除非独占表的那个人主动将资源释放出来。我们可以使用Visual FoxPro来分别模拟独占方式与共享方式下的数据库行为。请大家完成【实验 2-1 使用Visual FoxPro独占(共享)访问表】。
 实验 2-1 使用Visual FoxPro独占(共享)访问表
实验 2-1 使用Visual FoxPro独占(共享)访问表
独占方式访问可以确保绝不出现并发问题,但却严重影响了数据库使用效率。我想没有一个商家愿意他的商店一次只能有一个顾客惠顾吧。然而现实世界却仍然不乏"独占访问"的案例。几个月前,老婆生孩子住院,医院每天查房和给婴儿洗澡时,为了防止意外(偷孩子)发生,要将整个病区锁起来,每家只能留一个陪床。如果外面的家属想进去,那好,里面的那个陪床必须出来,任何时候只能有一个人在里面,这就是典型的"独占访问"。另外,象"探监"这样的事情想必也必须是"独占"的。
2.1.2 数据加锁
我们的店主对"独占方式"并不感兴趣,毕竟买卖更为重要,一次只让一个顾客访问的方式实在让人难以接受。还有什么好办法吗?那位可能会说:安个抢答器吧,谁先按下书就给谁。安抢答器的想法虽然有些离奇,但变通一下还是可以的。我们的店家凭借聪明的脑筋很快就提出了一个非常可行的方案:
首先,店家制作了一套标签,每个标签上都注有一个书名,书和标签间是一一对应的。书吧也专门在柜台前开设了一个新的窗口,用来发放这些标签。店家给这些标签起了个名字叫"锁",发放"锁"的窗口叫做"领锁处"。这样,当顾客查询好要读的图书后,他必须先到"领锁处"排队(先来先服务)以领取与书相对应的"锁"。通常情况下顾客都可以领到锁,然后去"领书处"登记,"领书处"将对应的图书交给顾客阅读并留下顾客的"锁"。阅读完后,顾客归还图书,"领书处"负责将对应的"锁"归还"领锁处"以备下次发放。当然,如果两个人都想读同一本书,那就看排队时谁在前面了,排在后面的顾客领不到锁就不能去领书处领书。此时,顾客有两个选择,一是放弃阅读的念头,二是等待前面的顾客归还图书后,领书处将"锁"归还"领锁处"。如图 2-1。

图 2-1 书吧运营模式(悲观缓冲模式)
这么一来,就免除了"独占"访问带来的问题。再多的顾客也可以同时选书,只有确认要读的时候再去"领锁处"排队,避免了独占方式下只允许一个顾客访问的问题。"锁"在里面起到了一个"令牌"的作用,只有持有令牌后才有权对其所对应的资源进行访问。另外,每本书都对应一个"锁",张三持有1、3、5的锁,李四还可以持有2、4、6的锁,只要大家访问的资源不冲突,就可以共享图书。即使出现了冲突,那也不怕。谁先排队持有锁,谁就可以访问资源,拿不到锁的人要么等待,要么放弃,就这么简单。
数据库也是通过加锁的方式来解决共享冲突问题的。Visual FoxPro为我们提供了RLOCK()函数对记录进行加锁。一旦某记录被加锁,其它用户就不能再对同一条记录加锁了。只有等待该记录上的锁被释放后才可以再次加锁。请大家完成【实验 2-2 使用Visual FoxPro实现记录锁定与解锁】。
实验 2-2 使用Visual FoxPro实现记录锁定与解锁
2.1.3 乐观与悲观缓冲策略
2.1.3.1 悲观锁
书吧在引入锁机制后运营了一段时间,但店家很快就发现了新的问题。有些顾客害怕别人抢走自己想看的书,于是就预先领取一大批锁,然后安心的逐一阅读,毕竟领到锁就等于领到了书。如图 2-2:
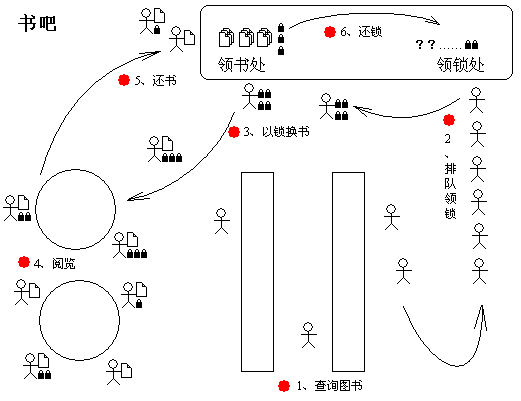
图 2-2 书吧运营出现问题,有人额外占有大量锁,造成领锁处资源紧张
可以从图中看出,顾客占有的锁资源越多,持有锁的时间越长,就造成越多的顾客排队领不到锁,而实际上书的资源并非如此紧张,只是有人"占着茅坑不拉屎"而已,而且是一个人占好几个茅坑![]() 。
。
焦头烂额的店主不得已又找来专家,请他们帮忙出主意。这回专家还真帮忙,不但找到了问题的根源,还给我们的店主下了两副药,解决了书吧的燃眉之急。那问题的根源究竟在哪里,这两副药又是什么呢?
经过专家考查,对原有业务流程进行抽象、总结,将原有的业务流程归纳成如下五步:领锁、领书、阅读、还书、还锁(对应数据库操作过程为:记录加锁、读取数据、修改数据、保存修改、记录解锁)。当一个用户持有某本图书(记录)的锁时,其他用户就不能再持有该书(记录)上的锁了,直到等待锁被释放。出现如此流程的原因在于店主过于悲观,担心出现并发冲突,因此要求先加锁再浏览(读取或修改),这么做相当于在书(记录)的粒度上实现了独占访问,带来的好处是决不会出现并发问题,但代价也是惨重的,致使资源没能有效利用。我们的专家给这种模式起了个名字,叫"悲观锁"(其实叫"悲观缓冲"更合适,只不过现在还没说到"缓冲"的概念,所以暂且叫悲观锁)。
悲观锁的特点是:先加锁,再修改,再保存,再解锁。悲观锁在记录级粒度上实现了"独占访问",解决了并发冲突的问题。同时,悲观锁锁定的记录越多,时间越长,资源的使用效率越低,给人的感觉就是性能越低下。
为此专家提供的药方一便是:(1)尽可能减少每个顾客可锁定的资源数量;(2)尽可能减少资源锁定的时间。为此,我们可以限定每个顾客一次只能领取一个锁,同时限定顾客的阅读时间,让锁尽可能早的回到领锁处。但是,从店家的角度来看,让读者一次只领一个锁还算可行,可限制阅读时间恐怕就不尽人意了。既然不限制读者的阅读时间,就不能排除有人领走一本书的锁后,迟迟不去领书,或读起书来三天打鱼,两天晒网(占着一个茅坑不拉屎![]() ),资源的使用效率仍然不高。
),资源的使用效率仍然不高。
2.1.3.2 缓冲与乐观锁
我们的专家似乎看出了店主的心事,便又给他出了第二个药方。这次需要店主对他的经营模式进行一番彻底改造。改造之一便是引入"缓冲"机制。
何为"缓冲"机制呢?先让我们看看专家提供的新方案(如图 2-3),在这个方案中,每个顾客都持有一个掌上阅读器。而"借阅图书"并不是真的将图书拿走,仅仅是从书吧的众多终端中将其"下载"到阅读器上,然后各自拿着各自的阅读器去阅读。这样一来,多个人可以同时阅读同一本书而互不干扰。我们可以将"阅读器"理解为"缓冲"。数据库中的数据下载到阅读器后,阅读器便可以"离线"(Off Line)工作了,每个顾客都拥有各自的"缓冲",它们之间不会相互干扰。至于你想缓冲多少数据就看店主的限制了。如果店主限制阅读器一次只能装载一本书(一条记录)的话,我们就管这种缓冲模式叫做"行缓冲";如果店主足够大方,允许将书吧中所有图书都下载到阅读器上的话,我们就管它叫做"表缓冲"。其实我们在【2.1.3.1悲观锁】一节看到的专家方案便是悲观行缓冲的方案。
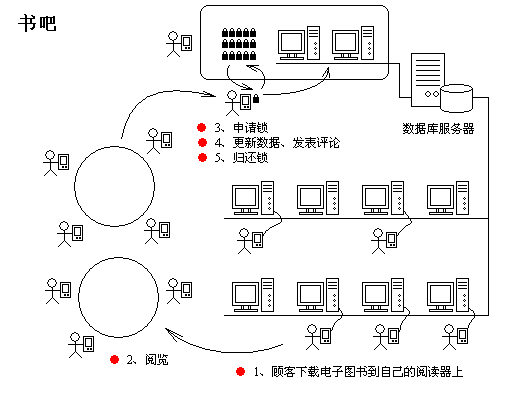
图 2-3 引入新设备、改进业务流程后的书吧
如果我们的书吧仅仅是让顾客读读书,那在引入"缓冲"后就没有什么需要改进的地方了。毕竟所有图书对于顾客而言都是"只读"的罢了。大家各自下载,各自阅读,不会出现什么并发问题。然而我们的专家建议店主为顾客提供一些新的服务:允许在顾客在"还书"时记录该书的阅读次数。同时也允许顾客给每本书添加评论,并且可以将这些评论内容保存起来,以后的读者在下载图书的同时还可以看到该书的阅读次数以及前人的评论。让书吧不但成为一个读书的地方,还成为读者相互交流的场所。
新服务的引入也带来了新问题。假设有两个顾客同时下载了同一本书,同时向数据库提交自己的评论,呵呵,并发问题又来了。为了解决并发问题,我们再次请出"锁"这个法宝。不过这次的锁不同于前面,我们管它叫做"乐观锁"(也叫"乐观缓冲模式")。乐观主义的人往往认为并发冲突发生的可能性非常小,因此可以优先考虑资源利用效率问题,然后再考虑是否会发生冲突。
乐观缓冲模式的特点是:先修改,再加锁,再保存,再解锁。也就是说乐观缓冲模式允许多人同时进行各自的修改操作(因为修改时不加锁),只有保存时才加锁,保存完后立刻解锁。因为用户修改数据往往占用较长的时间,而保存只是一瞬间的事,乐观缓冲模式可以保证锁定资源的时间尽可能的短,从而提高资源的使用效率。然而乐观缓冲模式的缺点就是无法避免并发冲突的发生。
让我们来看一个例子:假设张三和李四同时从书吧下载了同一本图书,该书已经被阅读了10次。在张三和李四的阅读器中都记录了已经阅读10次的信息。张三先读完了该书,并且到吧台要求"还书"以便下载另外一本。在还书的过程中,系统将张三阅读器中的阅读次数加1得到11并存入数据库。此后李四也读完了书,他也来到吧台进行"还书"。系统读出李四阅读器中的阅读次数是10,将其加1得11并存入数据库中。注意,原有图书被阅读了10次,加上张三和李四的阅读次数应当是12次。然而现在我们数据库中记录的却是11次,有一次阅读计数被丢掉了(这是我们在后面要提及的名为"丢失的修改"的并发冲突问题)!
由于乐观缓冲模式允许用户先修改,所以张三、李四各自都可以对数据进行修改,然而在保存时却出现了冲突。乐观缓冲模式在带来了资源使用效率提升的同时也带来了潜在的并发冲突,如果不加以有效的检验,冲突很可能造成很严重的后果。关于Visual FoxPro中如何检测冲突以及如何实现更新将在【2.1.4数据删除与更新】中详细论述。
为了加深乐观缓冲模式的印象,请大家完成【实验 2-3 乐观缓冲模式下更新图书阅读次数及相关并发冲突】。
2.1.3.3 小结
很难说究竟乐观缓冲好还是悲观缓冲好,其实各有千秋。不过在使用悲观缓冲时应尽量确保锁定尽可能少的资源,锁定时间尽可能短。而使用乐观缓冲时,一定要提供一套完善的冲突检测和解决机制,防止并发问题出现。并且,不同场合可能要求使用不同的缓冲策略。
目前绝大多数数据库操作都采用了乐观缓冲模式以提高数据访问效率,同时也对开发数据库应用程序的人提出了更高的要求,那就是必须学会如何编写程序解决并发冲突。我们会在本章后续内容中对此详细论述。乐观缓冲使用频率更高一些并不意味着悲观缓冲没有用处,下面的实验演示了悲观缓冲的一个应用场景:
在Visual FoxPro 6.0中,没有自动增长型字段(注:Visual FoxPro 8.0中已经允许将某一字段设置为自动增长型字段),当我们需要设置某个表的主键字段是自动增长型时,不得不通过编程的方式实现。同时,为确保两个并发用户申请到的主键不至于重复,我们必须使用悲观行缓冲策略。实验 2-4设计并实现了一套悲观缓冲自动增长型字段机制,可以帮助我们理解悲观缓冲的一些应用。
注:在后面的内容中,除非特别提及,否则使用的全是乐观缓冲模式。
2.1.4 数据删除与更新
2.1.4.1 CurrentValue与OldValue
乐观缓冲模式提高了数据库的并发访问效率,但同时也为我们带来了新的课题,那就是要解决并发带来的数据不一致问题。在上文故事中,我们看到张三、李四各浏览图书一次,而更新数据库时仅仅加了1而不是2。如何才能检测出类似问题,并加以规避呢?绝大多数的数据库访问技术都为我们提供了CurrentValue与OldValue(ADO.NET里叫做OriginalValue),通过比对这些值可以帮助我们发现潜在的冲突(注:此方法并不能保证发现所有并发问题,关于更进一步的分析请参考本章第二部分内容)。为了对其有一个感性认识,请完成【实验 2-3 乐观缓冲模式下更新图书阅读次数及相关并发冲突】的步骤3。
那究竟什么是CurrentValue,什么是OldValue呢。让我们用一个全新的例子来说明这个问题。假设张三、李四同时从数据库中读出某商品的数量并存入本地缓存(如图 2-4)。
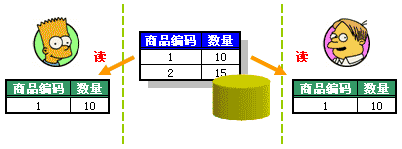
图 2-4 张三、李四从数据库中读入商品编码为1的记录
张三先卖出去1件商品并更新数据库,将数量改为9。此时李四缓冲中的数量仍然是10,他并不知道有人已经将数据库中的数据修改了(如图 2-5)。

图 2-5 张三首先更新数据库,写入9
现在由于新进一批商品,李四要给商品编码为1的商品数量加上10。如果他直接在自己的缓冲中进行操作,然后强行更新数据库的话,他就会将张三卖出1件商品的事实给抹掉,因为更新后数据库中记录的数量是20,而实际情况应当是19。
李四如何确保他不覆盖任何人的更新呢?这时候李四可以采用这样一种策略:当他试图修改缓冲区中的数据时,先对缓冲区的数据进行备份,也就是说保留当时读入的原始数据,而在原始数据的一个副本上进行修改(如图 2-6)。
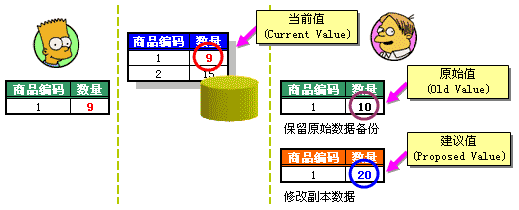
图 2-6 通过保留缓冲备份,得到了三种取值
于是我们便得到了同一个数据的三种不同版本的值,分别是:原始值(Old Value或Original Value),即最初读入缓冲区中的值;当前值(Current Value),即目前数据库中的值;建议值(Proposed Value),即用户打算将数据库中的数据修改成什么值。
现在李四的更新策略可以调整如下:(1)首先锁定数据库中对应的记录,确保在后面的操作过程中数据不会发生改变。(2)比较Current Value与Old Value是否相同。(3-a)如果两个值相同,则说明该数据尚未被人动过,直接完成更新;(3-b)如果两个值不同,说明在李四修改数据的过程中有人修改了数据库中的值,此时可以将当前值、原始值和建议值分别显示给用户,由用户决定是否强制更新。如果强行更新,则不管目前数据库的值是什么,强行写入20。如果不强制更新,用户可用当前值替换掉原始值,并要求用户重新修改好数据。(4)解锁。
在上面的更新策略中,我们又使到了锁,不过数据被加锁的时间是非常短的,因此不会影响数据库的并发效率。通过对原始值与当前值的比对,我们就可以发现是否有人动过数据库中的数据,从而提示用户做进一步的调整。
这么做解决了部分并发问题,但又会引发新的思考。例如图 2-7所示的问题:
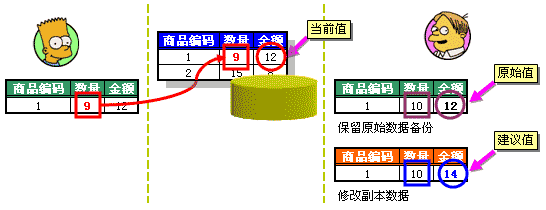
图 2-7 两人各自更新不同的字段
张三修改了数量,而李四修改了金额。数量字段上的当前值与原始值尽管不同,但李四从来没有动过这个字段。在李四修改了的金额字段上,当前值与原始值却是相同的。那究竟李四是可以保存呢还是不可以保存呢?
我们说这就要看你的更新策略了。如果你认为金额和数量是两个毫不相关的量,可以单独发生变化,这个时候就可以允许李四更新。如果你认为金额和数量密不可分,任何一个变了都会影响另外一个的话,就不能允许李四更新。
话说到这里有些人已经开始头痛了,你如何确保更新策略的实施呢?这正是下面我们要讨论的问题。
2.1.4.2 暗藏机关的Where短语
SQL语言已经成为关系型数据库操作的标准语言,可以说所有的关系型数据库都支持SQL命令。我们在使用各种图形用户界面完成对数据库操作的同时,也应注意到在底层跑的却是非常简单的SQL命令。当你用鼠标按下保存按钮的时候,没准一条UPDATE命令就被发送到数据库中。广义的数据更新命令很多,常用的包括Insert、Delete和Update命令。为了方便起见,在这部分内容里,我们只以Update命令为背景谈一谈"暗藏机关的Where短语"。
在前面的内容中,我们讨论了半天的当前值、原始值和建议值,而在数据库操作的过程中,所有的更新都必须转换成SQL中的UPDATE命令,那么这些值是如何被揉到UPDATE命令中,又是如何检测出并发冲突的呢?其实所有的秘密就在UPDATE的WHERE短语中。让我们看看在图 2-6所示的例子中,WHERE短语是如何发挥秘密武器的作用的。
李四现在要保存所做的修改,他会首先考虑使用UPDATE命令。他书写的命令如下:
UPDATE 商品表 SET 数量=20 WHERE 商品编码=1
这条命令的作用是将商品编码为1的商品数量改成20。命令能否成功执行呢?当然可以。因为商品编号字段是主键,它会唯一定位这条记录,然后将数量改为20,它不会去考虑是否有冲突发生。如果想判断是否有人动过数据,这条UPDATE命令必须写成
UPDATE 商品表 SET 数量=20 WHERE 商品编码=1 AND 数量=10
注意在WHERE短语中添加了一个条件:数量=10。这里使用了数量字段的原始值作为条件,意思是说在数据库中找到这么一行记录,它的商品编码是1,数量是10,然后将其数量改为20。尽管"商品编码=1"的条件就可以唯一定位这条记录了,但还是加上了一个保护条件,就是"数量=10",如果没有人动过这个数据,那它还应当是10,符合WHERE条件的记录就还是1条,更新可以成功执行。如果现在数据库中的数据已经被改为了9,那么加上保护条件后,就再也没有满足WHERE条件的记录了,因此更新也就无法完成。从用户的角度来看,那就是检测到并发冲突了。此时,你可以通过SELECT命令将数据库的当前值读出来,提供给用户做比对。
这回再让我们看看图 2-7所对应的例子。李四在更新时是否考虑数量字段如何通过WHERE短语实现呢?其实道理是一样的。如果李四在更新时只检测金额字段是否有人动过而不关心数量字段,那么他的UPDATE命令可以写成:
UPDATE 商品表 SET 金额=14 WHERE 商品编码=1 AND 金额=12
如果他希望数量和金额两个字段在更新时都没有被别人修改过,那么这回更新命令可以写成:
UPDATE 商品表 SET 金额=14 WHERE 商品编码=1 AND 金额=12 AND 数量=10
数量和金额字段上的原始值都派上了用场。由此也可以看出保留原始数据备份的重要性。
通过上面的例子可以看出,UPDATE命令中的WHERE短语不但可用起到限定更新范围的作用,使用好还可以同时实现检测并发问题的功能。如果在软件设计时精心安排WHERE短语的条件就可以起到意想不到的作用。
然而即便如此,构造WHERE短语仍然比较麻烦,不过很多编程语言都提供好了一组WHERE短语生成策略,将常用的生成方式都包纳进来,我们只要从这些策略中选择合适自己的就可以了。
2.1.4.3 WHERE短语的生成策略
不同语言提供的WHERE短语生成策略可能有微小差异,但基本上不外乎以下几种:关键字、关键字和可更新字段、关键字和已修改字段、时间戳等。
请先完成【实验 2-5 用Visual FoxPro验证WHERE短语生成策略】。
实验 2-5 用Visual FoxPro验证WHERE短语生成策略
通过实验我们可以看出,Visual FoxPro利用WHERE短语生成策略简化了使用者手工编写WHERE短语的麻烦,提高了SQL命令的生成效率。在这里值得一提的就是时间戳。
SQL Server中提供了一种数据类型叫timestamp ,在每次更新数据库时,该值都会自动发生变化。这是最严格的更新策略,在使用"时间戳"WHERE短语生成策略时,即使CurrentValue与OldValue完全相同,只要时间戳不同(比如一个人修改了数据,发现错了,又该了回去。尽管从结果上看数据没有发生变化,但时间戳变了),就无法完成数据更新操作。
在一些O/R Mapping软件中(例如Hibernate),使用一个数值型、只增不减的字段来实现时间戳的功能,这与SQL Server中的timestamp大同小异。
2.1.5 小结
从上面的论述中我们可以看到,Visual FoxPro提供了一套比较完善的冲突检测与解决机制,能够在绝大多数情况下完成有效的并发控制。但是,Visual FoxPro提供的解决机制仍然有所欠缺,在处理更复杂的并发问题时(例如不可重复读、幻影读等)显得力不从心。在本章后续部分中,我们将从完善的并发理论着手,更加深入的探询并发控制机制.
2.2 SQL Server 2000+ADO.NET实现并发控制
2.2.1 并发一致性问题
常见并发并发一致性问题包括:丢失的修改、不可重复读、读脏数据、幻影读(幻影读在一些资料中往往与不可重复读归为一类)。
2.2.1.1 丢失修改
下面我们先来看一个例子,说明并发操作带来的数据的不一致性问题。
考虑飞机订票系统中的一个活动序列:
- 甲售票点(甲事务)读出某航班的机票余额A,设A=16.
- 乙售票点(乙事务)读出同一航班的机票余额A,也为16.
- 甲售票点卖出一张机票,修改余额A←A-1.所以A为15,把A写回数据库.
- 乙售票点也卖出一张机票,修改余额A←A-1.所以A为15,把A写回数据库.
结果明明卖出两张机票,数据库中机票余额只减少1。
归纳起来就是:两个事务T1和T2读入同一数据并修改,T2提交的结果破坏了T1提交的结果,导致T1的修改被丢失。前文(2.1.4数据删除与更新)中提到的问题及解决办法往往是针对此类并发问题的。但仍然有几类问题通过上面的方法解决不了,那就是:
2.2.1.2 不可重复读
不可重复读是指事务T1读取数据后,事务T2执行更新操作,使T1无法再现前一次读取结果。具体地讲,不可重复读包括三种情况:
- 事务T1读取某一数据后,事务T2对其做了修改,当事务1再次读该数据时,得到与前一次不同的值。例如,T1读取B=100进行运算,T2读取同一数据B,对其进行修改后将B=200写回数据库。T1为了对读取值校对重读B,B已为200,与第一次读取值不一致。
- 事务T1按一定条件从数据库中读取了某些数据记录后,事务T2删除了其中部分记录,当T1再次按相同条件读取数据时,发现某些记录神密地消失了。
- 事务T1按一定条件从数据库中读取某些数据记录后,事务T2插入了一些记录,当T1再次按相同条件读取数据时,发现多了一些记录。(这也叫做幻影读)
2.2.1.3 读"脏"数据
读"脏"数据是指事务T1修改某一数据,并将其写回磁盘,事务T2读取同一数据后,T1由于某种原因被撤消,这时T1已修改过的数据恢复原值,T2读到的数据就与数据库中的数据不一致,则T2读到的数据就为"脏"数据,即不正确的数据。
产生上述三类数据不一致性的主要原因是并发操作破坏了事务的隔离性。并发控制就是要用正确的方式调度并发操作,使一个用户事务的执行不受其它事务的干扰,从而避免造成数据的不一致性。
2.2.2 并发一致性问题的解决办法
2.2.2.1 封锁(Locking)
封锁是实现并发控制的一个非常重要的技术。所谓封锁就是事务T在对某个数据对象例如表、记录等操作之前,先向系统发出请求,对其加锁。加锁后事务T就对该数据对象有了一定的控制,在事务T释放它的锁之前,其它的事务不能更新此数据对象。
基本的封锁类型有两种:排它锁(Exclusive locks 简记为X锁)和共享锁(Share locks 简记为S锁)。
排它锁又称为写锁。若事务T对数据对象A加上X锁,则只允许T读取和修改A,其它任何事务都不能再对A加任何类型的锁,直到T释放A上的锁。这就保证了其它事务在T释放A上的锁之前不能再读取和修改A。
共享锁又称为读锁。若事务T对数据对象A加上S锁,则其它事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这就保证了其它事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
2.2.2.2 封锁协议
在运用X锁和S锁这两种基本封锁,对数据对象加锁时,还需要约定一些规则,例如应何时申请X锁或S锁、持锁时间、何时释放等。我们称这些规则为封锁协议(Locking Protocol)。对封锁方式规定不同的规则,就形成了各种不同的封锁协议。下面介绍三级封锁协议。三级封锁协议分别在不同程度上解决了丢失的修改、不可重复读和读"脏"数据等不一致性问题,为并发操作的正确调度提供一定的保证。下面只给出三级封锁协议的定义,不再做过多探讨。
- 1级封锁协议
1级封锁协议是:事务T在修改数据R之前必须先对其加X锁,直到事务结束才释放。事务结束包括正常结束(COMMIT)和非正常结束(ROLLBACK)。1级封锁协议可防止丢失修改,并保证事务T是可恢复的。在1级封锁协议中,如果仅仅是读数据不对其进行修改,是不需要加锁的,所以它不能保证可重复读和不读"脏"数据。
- 2级封锁协议
2级封锁协议是:1级封锁协议加上事务T在读取数据R之前必须先对其加S锁,读完后即可释放S锁。2级封锁协议除防止了丢失修改,还可进一步防止读"脏"数据。
- 3级封锁协议
3级封锁协议是:1级封锁协议加上事务T在读取数据R之前必须先对其加S锁,直到事务结束才释放。3级封锁协议除防止了丢失修改和不读'脏'数据外,还进一步防止了不可重复读。
2.2.3 事务隔离级别
尽管数据库理论对并发一致性问题提供了完善的解决机制,但让程序员自己去控制如何加锁以及加锁、解锁的时机显然是很困难的事情。索性绝大多数数据库以及开发工具都提供了事务隔离级别,让用户以一种更轻松的方式处理并发一致性问题。常见的事务隔离级别包括:ReadUnCommitted、ReadCommitted、RepeatableRead和Serializable四种。不同的隔离级别下对数据库的访问方式以及数据库的返回结果有可能是不同的。我们将通过几个实验深入了解事务隔离级别以及SQL Server在后台是如何将它们转换成锁的。
2.2.3.1 ReadUnCommitted与ReadCommitted
ReadUnCommitted是最低的隔离级别,这个级别的隔离允许读入别人尚未提交的脏数据,除此之外,在这种事务隔离级别下还存在不可重复读的问题。
ReadCommitted是许多数据库的缺省级别,这个隔离级别上,不会出现读取未提交的数据问题,但仍然无法避免不可重复读(包括幻影读)的问题。当你的系统对并发控制的要求非常严格时,这种默认的隔离级别可能无法提供数据有效的保护,但对于决大多数应用来讲,这种隔离级别就够用了。
我们使用下面的实验来进行测试:
首先配置SQL Server 2000数据库,附加DBApp数据库。然后在Visual Studio .net中建立一管理控制台应用程序,添加必要的命名空间引用:
using System; using System.Data; using System.Data.SqlClient; using System.Configuration;
然后建立两个数据库链接,并分别采用不同的事务隔离级别:
private static SqlConnection conn1;
private static SqlConnection conn2;
private static SqlTransaction tx1;
private static SqlTransaction tx2;
private static void Setup()
{
conn1 = new SqlConnection(connectionString);
conn1.Open();
tx1 = conn1.BeginTransaction(IsolationLevel.ReadUncommitted);
conn2 = new SqlConnection(connectionString);
conn2.Open();
tx2 = conn2.BeginTransaction(IsolationLevel.ReadCommitted);
}
其中事务1允许读入未提交的数据,而事务2只允许读入已提交数据。
在主程序中,我们模拟两个人先后的不同操作,以产生并发一致性问题:
public static void Main()
{
Setup();
try
{
ReadUnCommittedDataByTransaction1();
UnCommittedUpdateByTransaction2();
ReadUnCommittedDataByTransaction1();
tx2.Rollback();
Console.WriteLine("/n-- Transaction 2 rollbacked!/n");
ReadUnCommittedDataByTransaction1();
tx1.Rollback();
}
catch
{
……
}
}
第一步,使用ReadUnCommittedDataByTransaction1方法利用事务1从数据库中读入id值为1的学生信息。此时的信息是数据库的初始信息。
第二步,调用UnCommittedUpdateByTransaction2方法,从第2个事务中发送一UPDATE命令更新数据库,但尚未提交。
第三步,再次调用ReadUnCommittedDataByTransaction1,从事务1中读取数据库数据,你会发现由事务2发布的尚未提交的更新被事务1读取出来(ReadUnCommitted)。
第四步,事务2放弃提交,回滚事务tx2.Rollback();。
第五步,再次调用ReadUnCommittedDataByTransaction1();,读取数据库中的数据,此次是已经回滚后的数据。
程序运行结果如下:
-- Read age from database: Age:20 -- Run an uncommitted command: UPDATE student SET age=30 WHERE id=1 -- Read age from database: Age:30 -- Transaction 2 rollbacked! -- Read age from database: Age:20
关于ReadUnCommittedDataByTransaction1()与UnCommittedUpdateByTransaction2()的方法定义如下:
private static void UnCommittedUpdateByTransaction2()
{
string command = "UPDATE student SET age=30 WHERE id=1";
Console.WriteLine("/n-- Run an uncommitted command:/n{0}/n", command);
SqlCommand cmd = new SqlCommand(command, conn2);
cmd.Transaction = tx2;
cmd.ExecuteNonQuery();
}
private static void ReadUnCommittedDataByTransaction1()
{
Console.WriteLine("-- Read age from database:");
SqlCommand cmd = new SqlCommand("SELECT age FROM student WHERE id = 1", conn1);
cmd.Transaction = tx1;
try
{
int age = (int)cmd.ExecuteScalar();
Console.WriteLine("Age:{0}", age);
}
catch(SqlException e)
{
Console.WriteLine(e.Message);
}
}
从上面的实验可以看出,在ReadUnCommitted隔离级别下,程序可能读入未提交的数据,但此隔离级别对数据库资源锁定最少。
本实验的完整代码可以从"SampleCode/Chapter 2/Lab 2-6"下找到。
让我们再来做一个实验(这个实验要求动作要快的,否则可能看不到预期效果)。首先修改上面代码中的Setup()方法代码,将
tx1 = conn1.BeginTransaction(IsolationLevel.ReadUncommitted);
改为:
tx1 = conn1.BeginTransaction(IsolationLevel.ReadCommitted);
再次运行代码,你会发现程序执行到第三步就不动了,如果你有足够的耐心等下去的话,你会看到"超时时间已到。在操作完成之前超时时间已过或服务器未响应。"的一条提示,这条提示究竟是什么意思呢?让我们探察一下究竟发生了什么:
第一步,在做这个实验之前,先将SQL Server 2000的企业管理器打开,然后再将SQL Server事件探察器打开并处于探察状态。
第二步,运行改动后的程序,程序执行到一半就暂停了。此时迅速切换到企业管理器界面,右击"管理"下面的"当前活动",选择"刷新"(整个过程应在大约15秒内完成即可,如图 2-8所示),我们便得到了数据库当前进程的一个快照。
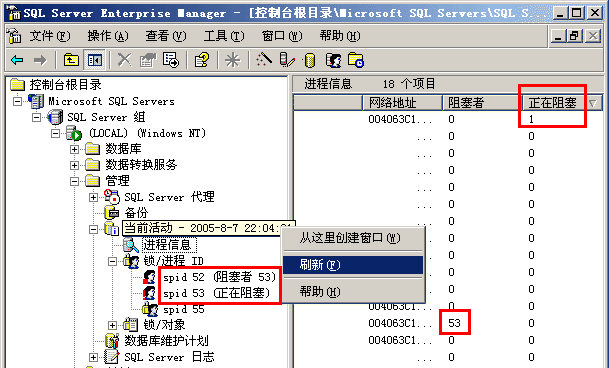
图 2-8 使用企业管理器查看当前活动
我们发现此时进程出现了阻塞,被阻塞者是52号进程,而阻塞者是53号进程。也就是说53号进程的工作妨碍了52号进程继续工作。(不同实验时进程号可能各不相同)
第三步,为了进一步查明原因真相,我们切换到事件探察器窗口,看看这两个进程都是干什么的。如图 2-9所示,事件探察器显示了这两个进程的详细信息。从图中我们可以看出,52号进程对应我们的事务1,53号进程对应我们的事务2。事务2执行了UPDATE命令,但尚未提交,此时事务1去读尚未提交的数据便被阻塞住。从图中我们可以看出52号进程是被阻塞者。
此时如果事务2完成提交,52号进程便可以停止等待,得到需要的结果。然而我们的程序没有提交数据,因此52号进程就要无限等下去。所幸SQL Server 2000检测到事务2的运行时间过长(这就是上面的错误提示"超时时间已到。在操作完成之前超时时间已过或服务器未响应。"),所以将事务2回滚以释放占用的资源。资源被释放后,52号进程便得以执行。
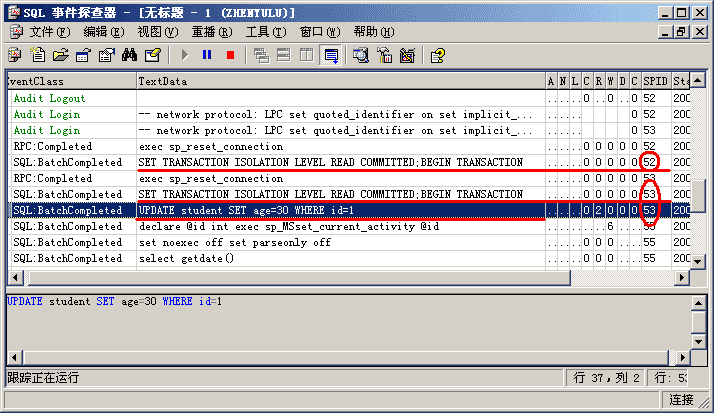
图 2-9 事件探察器探察阻塞命令
第四步,了解了上面发生的事情后,我们现在可以深入讨论一下共享锁和排它锁的使用情况了。重新回到企业管理器界面,让我们查看一下两个进程各占用了什么资源。从图 2-10中我们可以看出,53号进程(事务2)在执行更新命令前对相应的键加上了排它锁(X锁),按照前文提到的1级封锁协议,该排它锁只有在事务2提交或回滚后才释放。现在52号进程(事务1)要去读同一行数据,按照2级封锁协议,它要首先对该行加共享锁,然而 该行数据已经被事务2加上了排它锁,因此事务1只能处于等待状态,等待排它锁被释放。因此我们就看到了前面的"阻塞"问题。
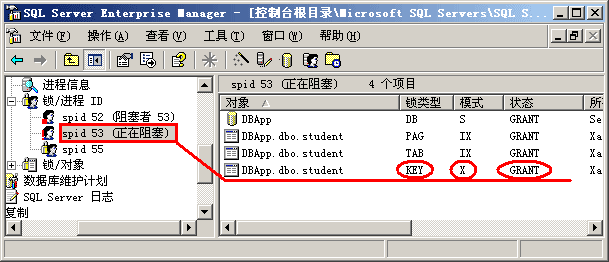
图 2-10 进程执行写操作前首先加了排它锁
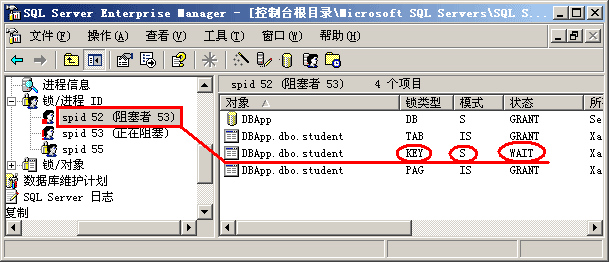
图 2-11 进程读操作前要加共享锁,但被阻塞
当事务1的事务隔离级别是ReadUnCommitted时,读数据是不加锁的,因此排它锁对ReadUnCommitted不起作用,进程也不会被阻塞,不过确读到了"脏"数据。
2.2.3.2 RepeatableRead
RepeatableRead是指可重复读,它的隔离级别要比ReadCommitted级别高。它允许某事务执行重复读时数据保持不变,但是仍然无法解决幻影读的问题。为了更深入的了解RepeatableRead所能解决的问题,我们还是使用下面的实验来加以印证:
第一步,事务1与事务2同时设置为ReadCommitted,并同时开启事务。
private static void Setup()
{
conn1 = new SqlConnection(connectionString);
conn1.Open();
tx1 = conn1.BeginTransaction(IsolationLevel.ReadCommitted);
conn2 = new SqlConnection(connectionString);
conn2.Open();
tx2 = conn2.BeginTransaction(IsolationLevel.ReadCommitted);
}
第二步,事务1读取数据库中数据。注意此时并没有通过提交或回滚的方式结束事务1,事务1仍然处于活动状态。
private static int ReadAgeByTransaction1()
{
return (int)ExecuteScalar("SELECT age FROM student WHERE (id = 1)");
}
private static object ExecuteScalar(string command)
{
Console.WriteLine("-- Execute command: {0}", command);
SqlCommand cmd = new SqlCommand(command, conn1);
cmd.Transaction = tx1;
return cmd.ExecuteScalar();
}
第三步,事务2修改年龄数据并提交修改。
private static void ModifyAgeByTransaction2()
{
string command = "UPDATE student SET age=30 WHERE id=1";
Console.WriteLine("-- Modify age by transaction2, command:{0}", command);
SqlCommand cmd = new SqlCommand(command, conn2);
cmd.Transaction = tx2;
try
{
cmd.ExecuteNonQuery();
tx2.Commit();
}
catch(Exception e)
{
Console.WriteLine(e.Message);
tx2.Rollback();
}
}
第四步,事务1重复读取年龄数据,此时会发现读取出来的数据是修改过的数据,与上次读取的数据不一样了!顾名思义,不可重复读。主程序代码如下:
public static void Main()
{
Setup();
try
{
int age1 = ReadAgeByTransaction1();
ModifyAgeByTransaction2();
int age2 = ReadAgeByTransaction1();
Console.WriteLine("/nFirst Read: age={0}/nSecond Read: age={1}", age1, age2);
}
catch(Exception e)
{
Console.WriteLine("Got an error! " + e.Message);
}
finally
{
CleanUp();
}
}
程序的运行结果如下:
-- Execute command: SELECT age FROM student WHERE (id = 1) -- Modify age by transaction2, command:UPDATE student SET age=30 WHERE id=1 -- Execute command: SELECT age FROM student WHERE (id = 1) First Read: age=20 Second Read: age=30
之所以出现了重复读时读取的数据与第一次读取的不一样,是因为事务1被设置成了ReadCommitted隔离类型,该隔离级别无法防止不可重复读的问题。要想在一个事务中两次读取数据完全相同就必须使用RepeatableRead事务隔离级别。
让我们修改上面的Setup()方法中的代码,将事务1的隔离级别设置为RepeatableRead:
tx1 = conn1.BeginTransaction(IsolationLevel.RepeatableRead);
再次运行该程序,你会发现程序执行到第二步就暂停了,如果等待一段时间后你就会看到"超时时间已到。在操作完成之前超时时间已过或服务器未响应。"的错误提示,此时,重复读的数据确和第一次读完全一样。程序执行结果如下:
-- Execute command: SELECT age FROM student WHERE (id = 1) -- Modify age by transaction2, command:UPDATE student SET age=30 WHERE id=1 超时时间已到。在操作完成之前超时时间已过或服务器未响应。 -- Execute command: SELECT age FROM student WHERE (id = 1) First Read: age=20 Second Read: age=20
为了探明原因,还是象上一个案例一样,再次执行该程序,当出现暂停时迅速切换到企业管理器中查看当前活动的快照,并检查阻塞进程中数据锁定情况,你会发现如图 2-12和图 2-13所示的内容:
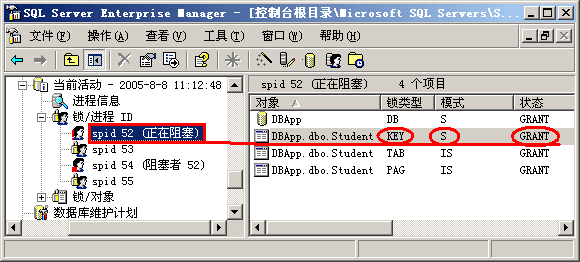
图 2-12 RepeatableRead在读数据时加S锁,直到事务结束才释放
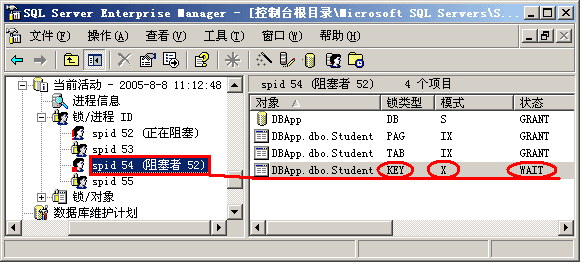
图 2-13 修改数据要求加X锁,但被阻塞
根据3级封锁协议,事务T在读取数据之前必须先对其加S锁,直到事务结束才释放。因此,事务1在第一次读取数据时便对数据加上了共享锁,第一次数据读取完成后事务并未结束,因此该共享锁并不会被释放,此时事务2试图修改该数据,按照2级封锁协议,在写之前要加排它锁,但数据上的共享锁尚未被释放,导致事务2不得不处于等待状态。当事务2等待时间超时后,SQL Server就强制将该事务回滚。尽管事务2执行失败,但保证了事务1实现了可重复读级别的事务隔离。
RepeatableRead事务隔离级别允许事务内的重复读操作,但是这并不能避免出现幻影读的问题,如果您的程序中存在幻影读的潜在问题的话,就必须采用最高的事务隔离级别:Serializable。
2.2.3.3 Serializable
Serializable隔离级别是最高的事务隔离级别,在此隔离级别下,不会出现读脏数据、不可重复读和幻影读的问题。在详细说明为什么之前首先让我们看看什么是幻影读。
所谓幻影读是指:事务1按一定条件从数据库中读取某些数据记录后,事务2插入了一些符合事务1检索条件的新记录,当事务1再次按相同条件读取数据时,发现多了一些记录。让我们通过以下案例来重现幻影读的问题:
第一步,将事务1和事务2均设为RepeatableRead隔离级别,并同时开启事务。
private static void Setup()
{
conn1 = new SqlConnection(connectionString);
conn1.Open();
tx1 = conn1.BeginTransaction(IsolationLevel.RepeatableRead);
conn2 = new SqlConnection(connectionString);
conn2.Open();
tx2 = conn2.BeginTransaction(IsolationLevel.RepeatableRead);
}
第二步,事务1读取学号为1的学生的平均成绩以及所学课程的门数。此时读到学生1学了3门课程,平均成绩为73.67。注意,此时事务1并未提交。
private static double ReadAverageMarksByTransaction1()
{
return (double)ExecuteScalar("SELECT AVG(mark) AS AvgMark FROM SC WHERE (id = 1)");
}
private static int ReadTotalCoursesByTransaction1()
{
return (int)ExecuteScalar("SELECT COUNT(*) AS num FROM SC WHERE (id = 1)");
}
private static object ExecuteScalar(string command)
{
Console.WriteLine("-- Execute command: {0}", command);
SqlCommand cmd = new SqlCommand(command, conn1);
cmd.Transaction = tx1;
return cmd.ExecuteScalar();
}
第三步,事务2向数据库插入一条新记录,让学号为1的同学再学1门课程,成绩是80。然后提交修改到数据库。
private static void InsertRecordByTransaction2()
{
string command = "INSERT INTO SC VALUES(1, 5, 80)";
Console.WriteLine("-- Insert to table SC by transaction 2");
Console.WriteLine("-- Command:{0}/n", command);
SqlCommand cmd = new SqlCommand(command, conn2);
cmd.Transaction = tx2;
try
{
cmd.ExecuteNonQuery();
tx2.Commit();
}
catch(Exception e)
{
Console.WriteLine(e.Message);
tx2.Rollback();
}
}
第四步,事务1再次读取学号为1的学生的平均成绩以及所学课程的门数。此时读到确是4门课程,平均成绩为75.25。与第一次读取的不一样!居然多出了一门课程,多出的这门课程就像幻影一样出现在我们的面前。测试用主程序如下:
public static void Main()
{
Setup();
try
{
Console.WriteLine(">>>> Step 1");
double avg = ReadAverageMarksByTransaction1();
int total = ReadTotalCoursesByTransaction1();
Console.WriteLine("avg={0,5:F2}, total={1}/n", avg, total);
Console.WriteLine(">>>> Step 2");
InsertRecordByTransaction2();
Console.WriteLine(">>>> Step 3");
avg = ReadAverageMarksByTransaction1();
total = ReadTotalCoursesByTransaction1();
Console.WriteLine("avg={0,5:F2}, total={1}/n", avg, total);
}
catch(Exception e)
{
Console.WriteLine("Got an error! " + e.Message);
}
finally
{
CleanUp();
}
}
程序执行结果如下:
>>>> Step 1 -- Execute command: SELECT AVG(mark) AS AvgMark FROM SC WHERE (id = 1) -- Execute command: SELECT COUNT(*) AS num FROM SC WHERE (id = 1) avg=73.67, total=3 >>>> Step 2 -- Insert to table SC by transaction 2 -- Command:INSERT INTO SC VALUES(1, 5, 80) >>>> Step 3 -- Execute command: SELECT AVG(mark) AS AvgMark FROM SC WHERE (id = 1) -- Execute command: SELECT COUNT(*) AS num FROM SC WHERE (id = 1) avg=75.25, total=4
大家可以思考一下,为什么RepeatableRead隔离模式并不能使得两次读取的平均值一样呢?(可以从锁的角度来解释这一现象)。
仍然象前面的做法一样,我们看看究竟发生了什么事情。在探察之前,先将Setup方法中事务1的隔离级别设置为Serializable,再次运行程序,当发现程序运行暂停时,查看数据库当前活动快照,你会发现如图 2-14和图 2-15所示的锁定问题:
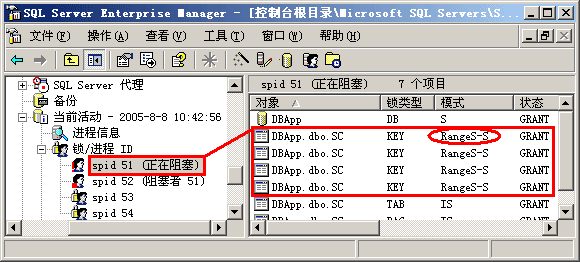
图 2-14 Serializable隔离模式对符合检索条件的数据添加了RangeS-S锁
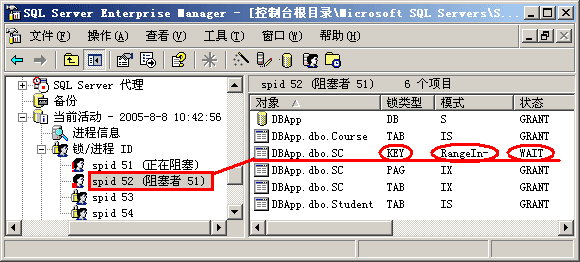
图 2-15 当试图插入符合RangeIn条件的记录时,只能处于等待状态
从图中我们可以看出,在Serializalbe隔离模式下,数据库在检索数据时,对所有满足检索条件的记录均加上了RangeS-S共享锁。事务2试图去插入一满足RangeIn条件的记录时,必须等待这些RangS-S锁释放,否则就只能处于等待状态。在等待超时后,事务2就会被SQL Server强制回滚。
修改后的程序运行结果如下:
>>>> Step 1 -- Execute command: SELECT AVG(mark) AS AvgMark FROM SC WHERE (id = 1) -- Execute command: SELECT COUNT(*) AS num FROM SC WHERE (id = 1) avg=73.67, total=3 >>>> Step 2 -- Insert to table SC by transaction 2 -- Command:INSERT INTO SC VALUES(1, 5, 80) 超时时间已到。在操作完成之前超时时间已过或服务器未响应。 >>>> Step 3 -- Execute command: SELECT AVG(mark) AS AvgMark FROM SC WHERE (id = 1) -- Execute command: SELECT COUNT(*) AS num FROM SC WHERE (id = 1) avg=73.67, total=3
事务2的运行失败确保了事务1不会出现幻影读的问题。这里应当注意的是,1、2、3级封锁协议都不能保证有效解决幻影读的问题。
2.3 建议
通过上面的几个例子,我们更深入的了解了数据库在解决并发一致性问题时所采取的措施。锁机制属于最底层的保证机制,但很难直接使用。我们可以通过不同的事务隔离模式来间接利用锁定机制确保我们数据的完整一致性。在使用不同级别的隔离模式时,我们也应当注意以下一些问题:
- 一般情况下ReadCommitted隔离级别就足够了。过高的隔离级别将会锁定过多的资源,影响数据的共享效率。
- 你所选择的隔离级别依赖于你的系统和商务逻辑。
- 尽量避免直接使用锁,除非在万不得已的情况下。
- 我们可以通过控制WHERE短语中的字段实现不同的更新策略,防止出现丢失的修改问题。但不必要的更新策略可能造成SQL命令执行效率低下。所以要慎用时间戳和过多的保护字段作为更新依据。














 480
480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









