







模型性能评估综述
对于模型性能的评估,我们通常分为一下三步:
1. 对数据集进行划分,分为训练集和测试集两部分;
2. 对模型在测试集上面的泛化性能进行度量;
3. 基于测试集上面的泛化性能,依据假设检验来推广到全部数据集上面的泛化性能
数据集的划分
对于模型来说,其在训练集上面的误差我们称之为“训练误差”或者“经验误差”,而在测试集上的误差称之为“测试误差”。因为测试集是用来测试学习期对于新样本的学习能力的,因此我们可以把测试误差作为泛化误差的近似(泛化误差:在新样本上的误差)。对于我们来说,我们更care的是模型对于新样本的学习能力,即我们希望通过对已有样本的学习,尽可能的将所有潜在样本的普遍规律学到手,而如果模型对训练样本学的太好,则有可能把训练样本自身所具有的一些特点当做所有潜在样本的普遍特点,这时候我们就会出现“过拟合”的问题。
因此在这里我们通常将已有的数据集划分为训练集和测试集两部分,其中训练集用来训练模型,而测试集则是用来评估模型对于新样本的判别能力。对于数据集的划分,我们通常要保证满足一下两个条件:
1. 训练集和测试集的分布要与样本真实分布一致,即训练集和测试集都要保证是从样本真实分布中独立同分布采样而得;
2. 训练集和测试集要互斥
基于以上两个条件我们主要由三种划分数据集的方式:留出法,交叉验证法和自助法
留出法
留出法是直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T,我们需要注意的是在划分的时候要尽可能保证数据分布的一致性,即避免因数据划分过程引入额外的偏差而对最终结果产生影响。
为了保证数据分布的一致性,通常我们采用分层采样的方式来对数据进行采样。假设我们的数据中有
m1
个正样本,有
m2
个负样本,而S占D的比例为
p
,那么T占D得比例即为
但是样本的不同划分方式会导致模型评估的相应结果也会有差别,例如如果我们把正样本进行了排序,那么在排序后的样本中采样与未排序的样本采样得到的结果会有一些不同,因此通常我们都会进行多次随机划分、重复进行实验评估后取平均值作为留出法的评估结果。
留出法的缺点:对于留出法,如果我们的对数据集D划分后,训练集S中的样本很多,接近于D,其训练出来的模型与D本身训练出来的模型可能很接近,但是由于T比较小,这时候可能会导致评估结果不够准确稳定;如果S样本很少,又会使得训练出来的样本与D所训练出来的样本相差很大。通常,会将D中大约
2/3−4/5
的样本作为训练集,其余的作为测试集。
交叉验证法
k折交叉验证通常把数据集D分为k份,其中的k-1份作为训练集,剩余的那一份作为测试集,这样就可以获得k组训练/测试集,可以进行k次训练与测试,最终返回的是k个测试结果的均值。这里数据集的划分依然是依据分层采样的方式来进行。对于交叉验证法,其k值的选取往往决定了评估结果的稳定性和保真性。通常k值选取10。与留出法类似,通常我们会进行多次划分得到多个k折交叉验证,最终的评估结果是这多次交叉验证的平均值。
当k=1的时候,我们称之为留一法,我们可以发现留一法并不需要多次划分,因为其划分方式只有一种,因为留一法中的S与D很接近,因此S所训练出来的模型应该与D所训练出来的模型很接近,因此通常留一法得到的结果是比较准确的。但是当数据集很大的时候,留一法的运算成本将会非常的高以至于无法忍受。
自助法
留出法与交叉验证法都是使用分层采样的方式进行数据采样与划分,而自助法则是使用有放回重复采样的方式进行数据采样,即我们每次从数据集D中取一个样本作为训练集中的元素,然后把该样本放回,重复该行为m次,这样我们就可以得到大小为m的训练集,在这里面有的样本重复出现,有的样本则没有出现过,我们把那些没有出现过的样本作为测试集。进行这样采样的原因是每个样本不被采到的概率为
1−1m
,那么经过m次采样,该样本都不会被采到的概率为
(1−1m)m
,那么取极限有
limm→∞(1−1m)m→1e≈0.368
,因此我们可以认为在D中约有36.8%的数据没有在训练集中出现过
这种方法对于那些数据集小、难以有效划分训练/测试集时很有用,但是由于该方法改变了数据的初始分布导致会引入估计偏差。
总结
- 对于数据量充足的时候,通常采用留出法或者k折交叉验证法来进行训练/测试集的划分;
- 对于数据集小且难以有效划分训练/测试集时使用自助法;
- 对于数据集小且可有效划分的时候最好使用留一法来进行划分,因为这种方法最为准确
性能度量
对于模型的性能度量,我们通常用一下几种方法来进行度量:
1. 错误率/精度(accuracy)
2. 准确率(查准率,precision)/召回率(查全率,recall)
3. P-R曲线,F1度量
4. ROC曲线/AUC(最常用)
5. 代价曲线
接下来,我们将会更加详细的来介绍这些概念以及那些度量方法是最常用的。
错误率/精度(accuracy)
假设我们拥有m个样本个体,那么该样本的错误率为:
准确率/召回率(查全率)
我们将准确率记为P,召回率记为R,通过下面的混淆矩阵我们有
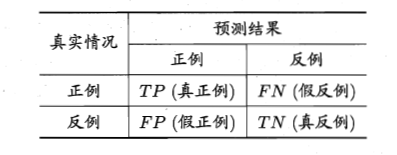
其中,TP(true positive),FP(false positive),FN(false negative),TN(true negative)
通过上面对准确率和召回率的描述我们可以发现,准确率更care的是在已经预测为真的结果中,预测正确的比例,这时候我们可以发现如果我们预测为真的个体数越少,准确率越高的可能性就会越大,即如果我们只预测最可能为真的那一个个体为真,其余的都为假,那么这时候我们的准确率很可能为100%,但此时召回率就会很低;而召回率care的是在所有为真的个体中,被预测正确的个体所占的比例,那么可以看到如果我们预测为真的个体越多,那么召回率更高的可能性就会越大,即如果我们把所有的个体都预测为真,那么此时的召回率必然为100%,但是准确率此时就会很低。因此这两个度量往往是相互对立的,即准确率高则召回率通常比较低,召回率高则准确率往往会很低。因此我们分别用准确率或召回率对模型的预测结果进行评价会有片面性,故接下来介绍P-R曲线来对模型进行更准确的评价。
P-R曲线/F1度量
P-R曲线是以召回率R为横轴,准确率P为纵轴,然后根据模型的预测结果对样本进行排序,把最有可能是正样本的个体排在前面,而后面的则是模型认为最不可能为正例的样本,再按此顺序逐个把样本作为正例进行预测并计算出当前的准确率和召回率得到的曲线。
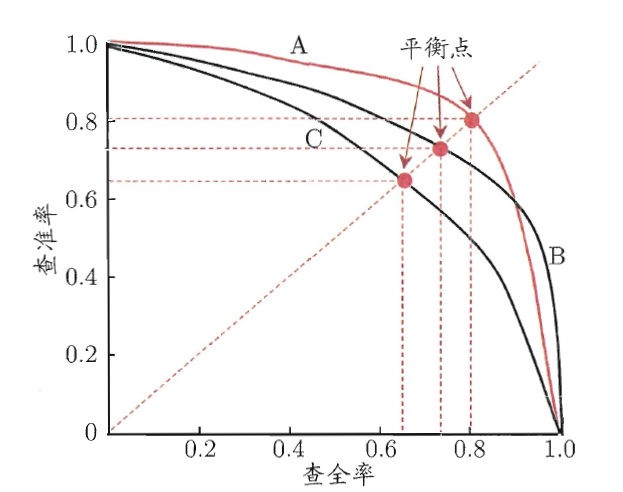
通过上图我们可以看到,当我们只把最可能为正例的个体预测为正样本时,其准确率最高位1.0,而此时的召回率则几乎为0,而我们如果把所有的个体都预测为正样本的时候,召回率为1.0,此时准确率则最低。但是我们如何通过PR曲线来判断哪个模型更好呢?这里有以下集中判断方式:
- 基于曲线是否覆盖来进行判断。即如果模型B的PR曲线此时完全包住了模型C的PR曲线,此时我们认为模型B对于该问题更优于模型C,这也可以理解,因为在相同召回率的情况下,模型B的准确率要比模型C的更高,因此B必然更优一些。但是这种方法在曲线有交叉的时候不好判断;
- 基于平衡点来进行判断。平衡点即为召回率与准确率相等的点,如果该点的值越大,则认为模型越优,但这样的判断过于简单;
- 利用F1度量来进行判断。 F1=2∗P∗RP+R , F1 的值越大越好,可以发现, F1 是一个准确率和召回率的调和平均数,其更care较小值,因此如果P与R中一个值太小会对 F1 产生更大的影响,但是这样的判断都是以准确率和召回率同等重要为基础的,但是对于很多问题,其会更care其中的一个指标,例如癌症的判断,其更关注的是召回率而不是准确率,因为如果我们更关注准确率,就会使得很多的癌症患者被误诊为不是癌症,从而造成患者的死亡率会更高;
- 利用 Fβ 来判断。 Fβ=(1+β2)∗P∗Rβ2∗P+R ,当 β=1 的时候,即为 F1 度量,当 β>1 的时候,召回率有更大的影响,反之准确率有更大的影响,这个很好理解,我们把 Fβ 转换一下又 Fβ=11+β2(β2R+1P) ,通过该公式我们可以看到当 β>1 的时候,R对于 Fβ 的影响更大。
但是对于PR曲线,其对于样本类别是否平衡非常的敏感,在这里我们可以做一个证明:
假设我们拥有n个样本,我们首先对样本进行排序,把在该模型下最可能预测为正例的样本放在前面,把最不可能为正例的样本放在后面,然后我们选取阈值c,那么在c之前的样本我们会预测为正,c之后的样本我们会预测为负。
p(fp)
表示我们对样本预测为正的概率,那么我们有:
-
TP=n∫c−∞p(Y=1|fp)p(fp)dfp=n∫c−∞p(Y=1,fp)dfp=n∫c−∞p(fp|Y=1)P(Y=1)dfp=nP(Y=1)∫c−∞p(fp|Y=1)dfp
-
FP=n∫c−∞p(Y=0|fp)p(fp)dfp=n∫c−∞p(Y=0,fp)dfp=n∫c−∞p(fp|Y=0)P(Y=0)dfp=nP(Y=0)∫c−∞p(fp|Y=0)dfp
-
TN=n∫∞cp(Y=0|fp)p(fp)dfp=n∫∞cp(Y=0,fp)dfp=n∫∞cp(fp|Y=0)P(Y=0)dfp=nP(Y=0)∫∞cp(fp|Y=0)dfp
-
FN=N∫∞cp(Y=1|fp)p(fp)dfp=n∫∞cp(Y=1,fp)dfp=n∫∞cp(fp|Y=1)P(Y=1)dfp=nP(Y=1)∫∞cp(fp|Y=1)dfp
那么准确率
我们可以看到准确率P与数据的先验分布 P(Y) 有很大的关系,当我们采的样本不均衡的时候, P(Y) 会有变化,从而导致准确率也会发生变化,因此PR曲线对于数据采样的均衡性具有很高的敏感度
ROC曲线/AUC
ROC曲线则是以假正例率FPR为横轴,真正例率TPR为纵轴。其中
我们可以看到真正例率与召回率是一样的,那么ROC曲线图如下图所示:
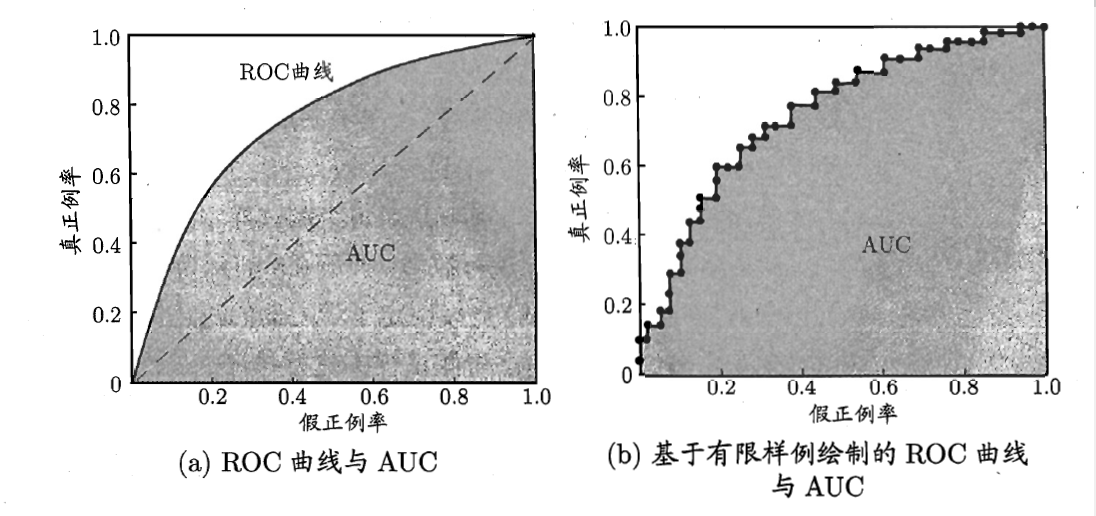
该曲线与绘制PR曲线类似,也是首先将样本按照正例的可能性进行排序,然后按顺序逐个把样本预测为正例(其实相当于取不同的阈值),然后计算FPR值和TPR值,即可获得该曲线。
对于该曲线,我们首先有4个特殊的点要说明一下:
(0,0)点:我们把所有的个体都预测为假,那我们可以知道TP与FP都为0,因为TP表示预测为真实际也为真,而FP表示预测为真实际为假的个体;
(0,1)点:我们所有预测为真的个体都正确,这是我们最理想的情况,此时 TP=TP+FN ,而 FP=0 ;
(1,0)点:这是预测最糟糕的情况,即所有的预测都是错误的,那么此时 TP=0 ,而 FP=FP+TN ;
(1,1)点:因为其是在 y=x 的这条直线上,因此其相当于随机预测,即我预测一个个体为真还是假都是随机的。
因此我们可以发现如果一个模型的ROC曲线越靠近与左上角,那么该模型就越优,其泛化性能就越好,但是对于两个模型,我们如何判断哪个模型的泛化性能更优呢?这里我们有主要以下两种方法:
- 如果模型A的ROC曲线完全包住了模型B 的ROC曲线,那么我们就认为模型A要优于模型B;
- 如果两条曲线有交叉的话,我们就通过比较ROC与X,Y轴所围得曲线的面积来判断,面积越大,模型的性能就越优,这个面积我们称之为AUC(area under ROC curve)
由于我们的样本通常是有限的,因此所绘制出来的曲线并不是光滑的,而是像曲线b那样,因此我们可以通过以下公式来计算AUCAUC=12∑i=1m−1(xi−1−xi)⋅(yi+yi+1)
根据FPR以及TPR的定义我们有TPR=TPTP+FN=nP(Y=1)∫c−∞p(fp|Y=1)dfpnP(Y=1)∫c−∞p(fp|Y=1)dfp+nP(Y=1)∫∞cp(fp|Y=1)dfp=∫c−∞p(fp|Y=1)dfp∫c−∞p(fp|Y=1)dfp+∫∞cp(fp|Y=1)dfp
FPR=FPFP+TN=nP(Y=0)∫c−∞p(fp|Y=0)dfpnP(Y=0)∫c−∞p(fp|Y=0)dfp+nP(Y=0)∫∞cp(fp|Y=0)dfp=∫c−∞p(fp|Y=0)dfp∫c−∞p(fp|Y=0)dfp+∫∞cp(fp|Y=0)dfp
通过上面的公式运算,我们发现ROC曲线对于样本类别是否平衡并不敏感,即其并不受样本先验分布的影响,因此在实际工作中,更多的是用ROC/AUC来对模型的性能进行评价
代价曲线
在上面所描述的衡量模型性能的方法都是基于误分类同等代价来开展的,即我们把True预测为False与把False预测为True所导致的代价是同等的,但是在很多情况下其实并不是这样的,我们依然以癌症诊断为例,如果我们把一个患有癌症的患者预测为不患有与把不患有癌症的患者预测为患有明显其造成的损失是不同的,因此在这种情况下发我们是不可能以同等代价来进行预测。故这里引入了二分类代价矩阵
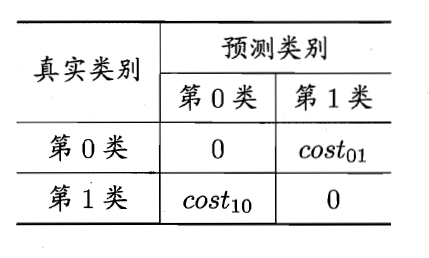
在这里我们给误分类赋予了一个代价指标。在非均等代价下,我们的目标就转化为最小化总体代价,那么代价敏感的错误率可以通过如下公式进行计算
由于在非均等代价下,ROC曲线并不能反映出模型的期望总体代价,因此引入了 代价曲线,其中横轴为正例概率代价,纵轴为归一化代价。正例概率代价计算方式为:
归一化代价计算方式为:
比较检验
前面介绍了各种性能度量方式,但是其度量的是模型在测试集下的测试误差的性能状况,虽然其可以近似代替泛化性能,但毕竟与真实的泛化性能有一定的距离,在这里我们介绍通过假设检验的方式,利用测试误差来预估泛化误差从而得到模型的泛化性能情况,即基于假设检验结果我们可以推断出若在测试集上观察到模型A比B好,那么A的泛化性能在统计意义上优于B的概率有多大
假设检验
假设检验就是数理统计中依据一定的假设条件,由样本推断总体的一种方法。其步骤如下所示:
1. 根据问题的需要对所研究的总体做某种假设,记为
H0
2. 选取合适的统计量,这个统计量的选取要使得在假设
H0
成立时,其分布是已知的(统计量我们可以视为样本的函数)
3. 由实测的样本计算出统计量的值,根据预先给定的显著性水平进行检验,做出拒绝或接受假设
H0
的判断
根据以上三步我们知道首先我们要对所研究的总体做出某种假设,在我们所研究的问题中就是对模型泛化错误率分布做出某种假设或猜想。通常,测试错误率与泛化误差率的差别很小,因此我们可以通过测试误差率来估计泛化误差率。我们知道泛化误差率为
ϵ
的模型在m个样本中被测得的测试错误率为
ϵ^
的概率为
我们可以看到该概率的格式满足二项分布,那么 ϵ 在取什么值的时候,概率P最大?让P对 ϵ 求导后我们可以发现当 ϵ=ϵ^ 的时候,概率值是最大的,二项分布示意图如下所示:
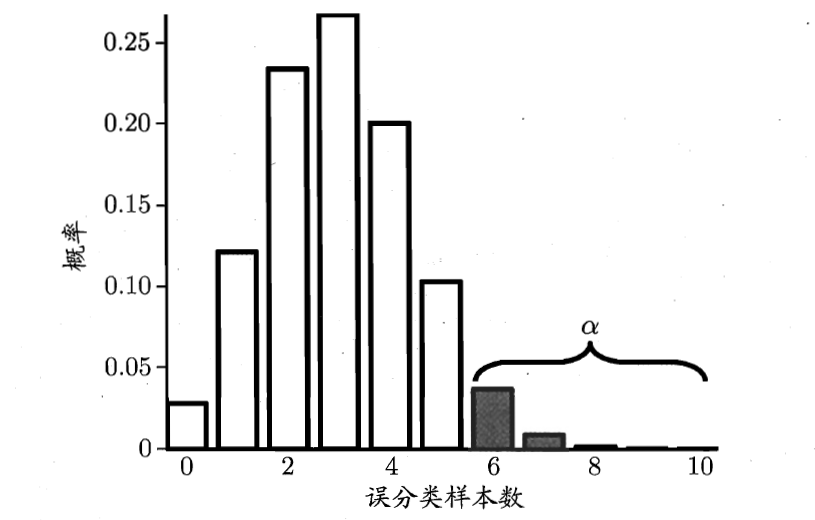
因此,我们可以假设泛化误差率 ϵ≤ϵ0 ,那么在 1−α 的概率内所能观测到的最大错误率可以通过下式计算得到:
即我们最多能够误分的样本数为上图阴影部分乘上其相应的概率,故当测试错误率 ϵ^≤ϵ0 时,在 α 的显著度下是接受的,即能够以 1−α 的置信度认为模型的泛化错误率不大于 ϵ0
大多数情况下,我们会使用多次留出或交叉验证法,因此我们会得到多组测试误差率,此时我们可以使用t检验的方式来进行泛化误差的评估。
即假定我们得到了k个测试误差率, ϵ^1,ϵ^1,...,ϵ^k ,则平均测试错误率 μ 和方差 σ2 为
由于这k个测试误差率可以看做泛化误差率 ϵ0 的独立采样,因此变量 τt=k√(μ−ϵ0)σ 服从自由度为k-1的t分布。对于假设 μ=ϵ0 和显著度 α ,我们可以计算出当前错误率均值为 ϵ0 时,在 1−α 概率内能观测到的最大错误率,即临界值。这样我们就可以对我们的假设做出拒绝或接受。














 1494
1494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









