









反向传播backpropagation是递归(recursive)调用求导链式法则(chain rule)来求导的过程,对他的理解对于神经网络的应用很重要。
反向传播 backpropagation
反向传播在UFLDL中的介绍已经较为具体 (http://blog.csdn.net/bea_tree/article/details/51174776),这里仅作补充。
原文简要介绍了求导与链式求导的基本原理,这里不再赘述了,但是还是写一下关于简单的backpropagation的例子:
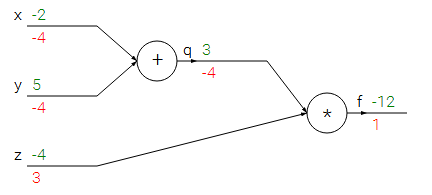
上图可以用下面的式子表示:
f=z×(x+y)
我们要做的事情是给定输入x,y,z的值(绿色),然后求其导数(红色)。
df/dz好求,df/dx和df/dy需要运用链式求导法则:df/dx=df/dq*dq/dx而df/dq=z,也就是在计算df/dx的时候用到了后面的df/dq,这就是backpropagation。
我们现在整理下上面的过程:
1. 正向传播 计算各个点的输出值
2. 计算局部导数如dq/dx
3. 利用chain rule 进行反向传播获得最终我们需要的导数
上述过程不需要考虑整个网络,只需要单独计算各个节点。
再次直观的对上图的公式进行理解:如果我们想要输出变大,那么该如何修改x,y,z三个值呢?在都改变很小的条件下,由于x,y导数为负,z导数为正,所以应该减小xy增大z。文中将线路中的每一个节点叫作gate。链式求导就是将各个Gates的导数相乘,但是并不是任何时候都要用相乘的形式,因为很多导数是可以事先算好记住的,比如sigmoid的导数:
σ(x)=11+e−x→dσ(x)dx=e−x(1+e−x)2=(1+e−x−11+e−x)(11+e−x)=(1−σ(x))σ(x)
以后只记住这个结果可以在以后的计算中省心省力。
技巧:有时候将正向传递打碎分段,分别进行可以比较容易的计算backpropagation。
另外这里对文中的“+=”说明下:“if a variable branches out to different parts of the circuit, then the gradients that flow back to it will add.”例如f=x+g(x)+h(x),那么df/dx=三部分对x的导数之和。
Patterns in backward flow
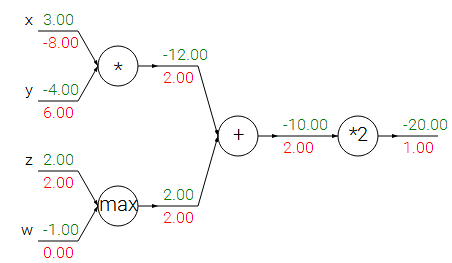
通过上图来说明下反向传播中各个gate的作用:
1. 加法门:加法门不会给他的输入带来改变,会将它输出的梯度直接传递过去;
2. max门:max中只有一个会有梯度,另外一个为0,会把他的输出的导数传递到较大的输入中;
3. 乘法门:某个输入的梯度等于输出的梯度与其他因子的乘积,比如x的梯度为-8=-4*2。
另外这里需要注意的是我们在分析乘法门的时候可以发现,若输入为w*x,如果我们的初始设置的x比较大,比如比我们之前设置的大1000倍,那么我们得到w的梯度就会非常大,大1000倍,也就是说如果我们输入的值太大就需要将学习速度(步长)调小。这也说明了预处理的重要性。
另外在实际运用中可以使用矩阵的乘法来进行backpropagation















 1601
1601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









