




 本文介绍了使用Python进行网络爬虫,模拟登录正方教务系统,避开验证码,通过分析HTTP请求和响应,抓取并解析成绩的过程。涉及Cookie处理、 Referer头的使用及正则表达式解析。
本文介绍了使用Python进行网络爬虫,模拟登录正方教务系统,避开验证码,通过分析HTTP请求和响应,抓取并解析成绩的过程。涉及Cookie处理、 Referer头的使用及正则表达式解析。
最近由于某些需要,开始入门Python网络爬虫,想通过一个Python程序来访问正方教务管理系统并且抓取到期末的成绩,由于我并没有深入了解过过其他的编程语言,所以,也比较不出Python和其他语言(如JAVA/PHP)的优缺点,只是因为我会Python,废话不多说,开工。
首先说一下,我们学校教务系统的网址是http://222.24.19.201,我想到的流程是,登入教务系统,然后访问查成绩的网址,将历年成绩抓取下来,这是一个很直观的流程,在程序中要做的就是1.登录, 2.访问 , 3.抓取,4.解析。当然,在这之前,首先要解决一个问题: 验证码。
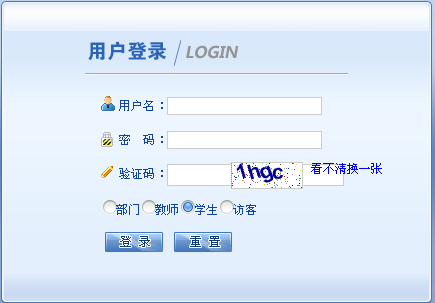
就是这样,验证码!我想到的第一个问题是OCR,可这个对我来说有点太复杂了,有其他的方法嘛,仔细观察,

我们登录要提交的验证码,帐号密码其实是提交到了http://222.24.19.201/default2.aspx
,可是这并没有什么用,还是验证码,等等,注意到了default后面的2,那岂不是还有0,1,3,4…,抱着试一试的态度,尝试了一下,知道找到http://222.24.19.201/default6.aspx,终于看到了预期的结果。
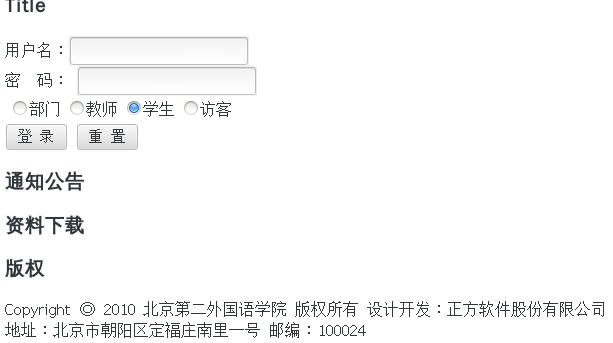
居然是北京第二外国语学院,贵圈真乱!由于我清楚222.24.19.201是邮电学院的IP,所以,我就在用户名和密码上填入了自己的用户名和密码,果不其然,登进去了,所以决定了,就从这个网址下手。
接下来,就得看浏览器都干了些什么,我用的查看浏览器行为的是一款叫做HttpFox的扩展程序,如果你用的是Windows, 那么Fiddler也是一个不错的选择,这是这款程序的外观
当浏览器访问新的网页的时候,这个程序会跟踪追踪浏览器的行为(POST & GET 不了解的请自行百度)所以我们先来尝试访问一下
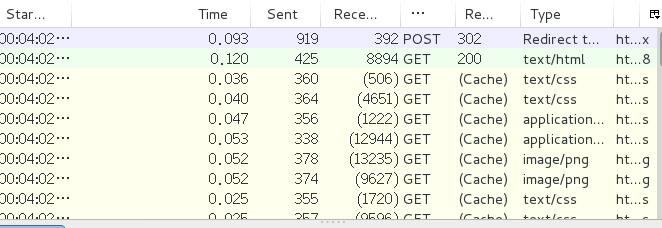
看到了POST, 我想知道我们向浏览器都提交了什么,点击POST, 查看POST DATA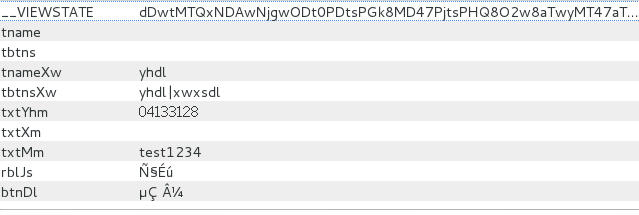
东西真多,我们需要将这些东西通过程序提交给服务器,值的说的是,乱码的一个是”学生” 一个是”登录”, 由于,教务系统的网站所用的编码是gb2312, 而它用utf-8的方式打开,所以,就乱了。。还有一个第一项—__VIEWSTATE这是asp.net框架特有的一个东西,详细用法自行百度,这里一定要加入(P.S 不要尝试登录朕的教务系统,这只是测试密码).
关于登录,我们必须要谈的一个话题是Cookie, 这不只是饼干,还是指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密),所以我们要做的第一件事就是获取这个网站的Cookie。Python提供了一个模块叫做cookielib,我们要构建一个cookie的处理器来存储访问网站所得的cookie
import urllib2
import cookielib
loginURL = 'http://222.24.19.201/default6.aspx' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1903
1903


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








