







1. 基本概念
1.1 数据挖掘:
(1) 数据挖掘是从存放在数据集中的大量数据中挖掘出有趣知识的过程。
(2) 又称数据中知识发现(Knowledge Discovery Databases)或知识发现,它是从一个大量数据中抽取挖掘出未知的、有价值的模式和规律等知识的非平凡过程,它与数据仓库有着密切的联系。
(3) 广义的数据挖掘是指知识发现的全过程;狭义的数据挖掘是指统计分析、机器学习等发现数据模式的智能方法,即偏重于模型和算法。
(4) 数据库查询系统和专家系统不是数据挖掘。在小规模数据上的统计分析和机器学习过程也不应算作数据挖掘。
1.2 机器学习:
(1) 对于某类任务T和性能度量P,如果一个计算机程序在T上以P衡量的性能随着经验E而自我完善,那么这个计算机程序被称为在从经验E学习。
(2) 机器学习是知识发现的一种方法,是指一个系统通过执行某种过程而改进它处理某一问题的能力。
1.3 数据挖掘的对象:
(1) 关系型数据库、事务型数据库、面向对象数据库
(2) 数据仓库/多为数据库
(3) 空间数据(如地图信息)
(4) 工程数据(如建筑、集成电路的信息)
(5) 文本和多媒体数据(如文本、图像、音频、视频数据)
(6) 时间相关的数据(如历史数据或股票交换数据)
(7) 万维网(如半结构化的HTML,结构化的XML以及其他网络信息)
1.4 数据挖掘的步骤:
(1) 数据清理(消除噪声或不一致数据,补缺);
(2) 数据集成(多种数据源可以组合在一起);
(3) 数据选择(从数据库中提取相关的数据);
(4) 数据交换(变换成适合挖掘的形式);
(5) 数据挖掘(使用智能方法提起数据模式);
(6) 模式评估(识别提供知识的真正有趣模式);
(7) 知识表示(可视化和知识表示技术);
1.5 支持数据挖掘的关键技术:
(1) 数据库/数据仓库/OLAP
(2) 数学/统计(回归分析:多元回归、自回归;判别分析:Bayes判别、Fisher判别、非参数判别;主成分分析、相关性分析;模糊集;粗糙集;)
(3) 机器学习(聚类分析;关联规则;决策树;范例推理;贝叶斯网络;神经网络;支撑向量机;遗传算法)
(4) 可视化:将数据、知识和规则转化为图表表现的形式。
1.6 数据仓库:
(1) 数据仓库是一个面向主题的、集成的、随时间变化的、非易失性数据的集合,用于支持管理人员的决策。
(2) 数据仓库是一种多个异种数据源在单个站点以统一的模式组织的存储,以支持管理决策。数据仓库技术包括数据清理、数据集成和联机分析处理(OLAP)。
(3) 数据仓库的逻辑结构是多维数据库。数据仓库的实际物理结构可以是关系数据存储或多维数据方(Cube)。
(4) 数据方是由纬度(Dimension)和度量(Measure)定义的一种数据集,度量存放在由维度索引的数据方单元中。维度对应于模式中的属性组,度量对应于与主题相关的事实数据。数据方的物化是指预计算并存储全部或部分单元中的度量。
1.7 数据仓库的模型:
(1) 星型模式:最常见模型;其中数据仓库包括一个大的(包括大批数据、不含冗余)中心表(事实表);一组小的附属表(维表),每维一个。
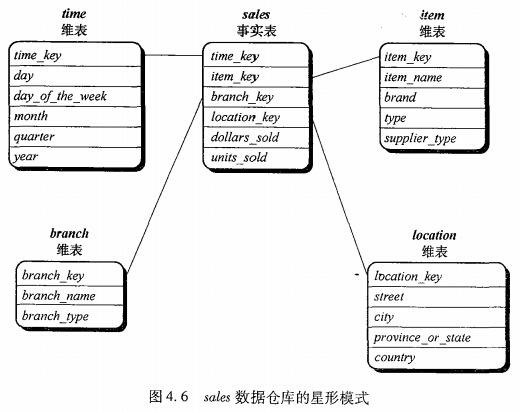
(2) 雪花模式:星型模式的变种,其中某些维表是规范化的,因而把数据进一步分解到附加的表中。

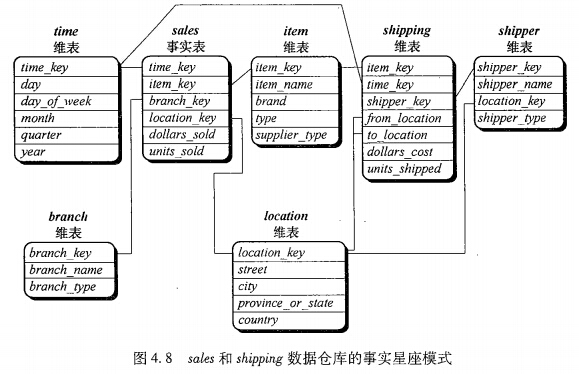
(3) 星系模式:多个事实表共享维表。这种模式可以看作星型模式集,因此称为星系模式,或事实星座。
1.8 典型的OLAP操作:
(1) OLAP是一种多维数据分析技术。包括汇总、合并和聚集等功能,以及从不同的角度观察信息的能力。
(2) 上卷:从某一纬度的更高概念层次观察数据方,获得更概要的数据。它通过沿维的概念分层向上或维归约来实现。
(3) 下钻:下钻是上卷的逆操作。它从某一维度的更低概念层次观察数据方,获得更详细的数据。下钻可以通过沿维的概念分层向下或引入新的维来实现。
(4) 切片和切块:切片操作在给定的数据方的选择一个维的部分属性,获得一个较小的子数据方。切块操作通过对选择两个或多个维的部分属性,获得一个较小的子数据方。
(5) 转轴:是一种改变数据方二维展现形式的操作。它将数据方的二维展现中的某些维度由行改为列,或由列改为行。

2. 数据准备
现实世界的数据是不完整的(有些感兴趣的属性缺少属性值,或仅包含聚集数据),含噪声的(包含错误,或存在偏离期望的异常值),不一致的(例如,用于商品分类的部门编码存在差异)。
需要数据清理、数据集成、数据选择、数据变换等技术对数据进行处理。
2.1 维归约/特征提取
2.1-1 决策树归约
(1) 决策树归约构造一个类似于流程图的结构:其每个非叶子节点表示一个属性上的测试,每个分支对应于测试的一个输出;每个叶子结点表示一个决策类。
(2) 在每个结点,算法选择“当前对分类最有帮助”的属性,出现在树中的属性形成归约后的属性子集。
2.1.2 粗糙集归约
(1) 粗糙集
3. 数据挖掘算法
数据挖掘算法按挖掘目的可分为:
- (1) 概念描述(总结,对比等)
- (2) 关联规则分析
- (3) 分类与预测(信息自动分类,信息过滤,图像识别等)
- (4) 聚类分析
- (5) 异常分析(入侵检测,金融安全等)
- (6) 趋势、演化分析(回归,序列模式挖掘)
按训练方式,机器学习可分为:
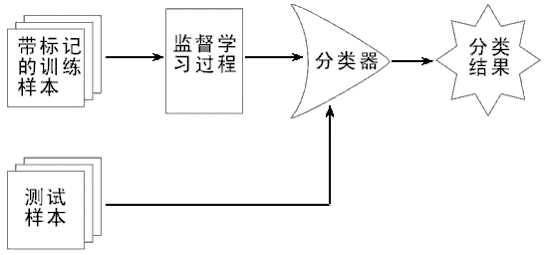
有监督学习:有训练样本,通过学习获得训练样本包含的知识,并用其作为判断测试样本的类别的依据。
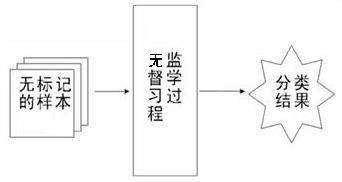
无监督学习:无训练样本,仅根据测试样本在特征空间分布情况判断其类别。
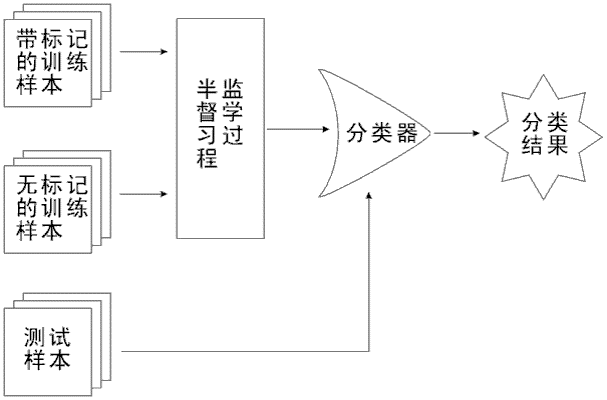
半监督学习:有少量训练样本,以从训练样本获得的知识为基础,结合测试样本的分布情况逐步修正已有知识,并判断测试样本的类别。
强化学习:没有训练样本,但有对每一步是否更接近目标的奖惩措施。
3.1 关联规则挖掘
关联规则挖掘:发现大量数据中项集之间有趣的关联或相关联系。
设 I = {
i1,i2,...,im
} 是项的集合。设任务相关的数据
D
是数据库事务的集合,其中每个事务














 5117
5117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









