









字符串匹配 -- KMP算法
参考资料
1 数据结构( C 语言版)
概述
在前面的文章
朴素字符串匹配、
Rabin-Karp算法中,对有关字符串匹配问题做了相关的介绍。其中
朴素字符串匹配效率较差,其时间复杂度为 O ( ( n - m + 1 ) m ) ,当问题规模较大时,该算法的劣势会变得更加明显;
Rabin-Karp算法需要一个预处理,其时间为 O ( m ) ,匹配的最坏时间复杂度为 O ( ( n - m + 1 ) m ) ,但在平均情况和实际情况下,其效果还是不错的,所以应用还是很广的。
事实上还有一种字符串匹配算法 -- KMP算法 ( 有人将此算法戏称为看mao片算法,呵呵!!无力吐槽了都!! ),其效率更高。该算法也需要对模式进行预处理,其时间复杂度为 O ( m ),匹配的时间复杂度为 O ( n ) 。该算法是由Knuth、Morris、Pratt三人设计的线性时间字符串匹配算法。在此不得不佩服这三位大牛,该算法设计的实在巧妙,代码简短精巧,为了把这个算法看懂还要反复思考琢磨,花了我不少时间。
算法思想
KMP算法与以往的字符串匹配算法不同的一点是:每当一趟匹配过程中出现比较不匹配时,不需要对字符串进行回溯,而是利用已经得到的“部分匹配”的结果将模式向右滑动尽可能远的一段距离后,继续进行比较。
该算法一个最重要的就是对模式进行预处理,也就是通过预处理得到一个数组 next[ ] ,该数组用来说明档模式中第 j 个字符与主串中相应字符“失配”之后,在模式中需要重新和主串中该字符进行比较的字符的位置。下面将给出求 next 数组的方法。
KMP算法的匹配过程
有一个字符串 str = "acabaabaabcac " ,模式 p = "abaabcac" 。模式 p 的 next 数组已得到,如下图

得到模式 P 的 next 数组之后,就可以对字符串进行匹配了。
匹配过程
我们用两个指针i和j分别指向 str 和 P 。在匹配之前,我们需要知道 next 大概要完成什么样的工作。我们根据模式 P 的特点,
1 字符串 str 与模式 P 进行匹配,str[ 1 ] != P[ 1 ] ,失配。此时我来做些说明。对于一般情况,当失配的时候,str[ i ] ! = P[ j ],说明 str[ i - j .. i-1] = P[ 0 .. j-1 ] 。
此时,字符串 str 不动,查找模式 P 的 next 数组。next[ 1 ] = 0 ,于是模式从 P[ next [ 1 ] ] 开始与str[ 1 ] 进行比较。
2 此时从 P[ next [ 1 ] ] 也就是 P [ 0 ] 开始与str[ 1 ] 进行比较,失配,此时j = next[ 0] = -1 ,i 和 j 同时都加1,即 i = 2 ,j = 0 ,分别从 str [ 2 ] 和 P [0 ] 开始比较
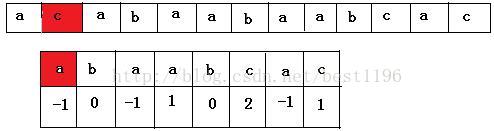
3 当从 str [ 2 ] 和 P [0 ] 开始比较,一直匹配直到 i = 7 和 j = 5 时失配。此时查找 next[ 5 ] = 2 ,说明 模式 P 在 0~1 与3~ 4 的字符串相等。同时 str[ 3] ~ str[4] = str[6] ~ str[7] 。P [ 0 ] ~ P [ 1 ] 等于 str [ 3 ] ~ str [ 4 ] ,也等于 str [ 6 ] ~ str[ 7 ] ,所以模式在比较的时候 str[ 6 ] ~ str[ 7 ] 就不需要比较了,直接从 j = next[5] = 2 处与 str[ 7 ] 进行比较即可。
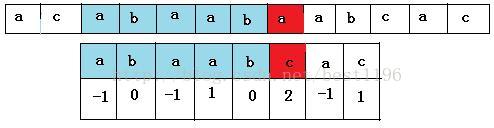
4 匹配成功!!
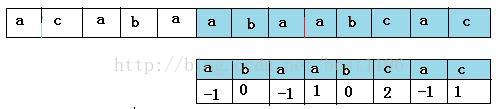
next数组
从上面的匹配过程中,可以看到模式右移是根据 next [ j ] 来决定应该要右移多少。那么next数组是怎么得到的呢。
我们看一下求next数组的代码
void get_next( const char* s , int len , int *next)
{
int i = 0;
next[0] = -1;
int j = -1;
while(i < len-1)
{
if( j == -1 || s[i] == s[j]) //j=-1:模式开始位置 ;当s[i] = s[j] :模式将继续往前
{
++i;
++j;
if( s[i] != s[j]) //不相等,则到此结束
next[i] = j;
else
next[i] = next[j];
}
else //当
j = next[j];
}
}根据该代码,我们可以大致得到以下步骤
1 初始化。 i = 0 , j = -1 next[ 0 ] = -1
2 执行循环。
3 满足 j == -1 或 s[ i ] = s[ j ] 时,i ,j 同时加1 ,之后判断s[ i ] 是否 s[ j ] 。若不等,则next [ i ] = j ;否则 next [ i ] = next [ j ]
4 若不满足 j == -1 或 s[ i ] = s[ j ] ,则 j 回溯,j = next [ j ]
next 求解过程
1 模式p = "abaabcac" 。初始化: i = 0 , j = -1 , next [ 0 ] = -1
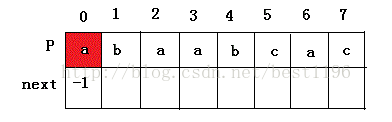
2 j == -1 ,++i ,++j 则 i= 1,j = 0。P[1] != P[0] 于是 next [1 ] = 0
3 P[1] != P[0] ,执行else 语句,j = next [ 0] = -1 。此时 i = 1 ,j = -1,进入循环之后,i = 2,j= 0 。P[2 ] = P[ 0 ] ,所以 next [ 2 ] = next [ 0] = -1
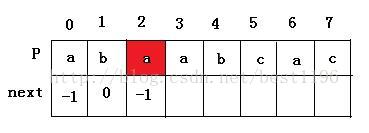
4 此时i = 2 , j = 0。进入循环,P[2 ] = P[ 0 ],i = 3,j = 1,P[ 3 ] != P [ 1 ] ,next[3] = 1。
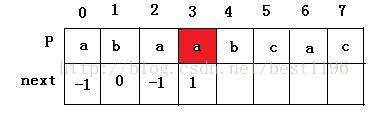
5 此时 i = 3 , j = 1。进入循环,P[ 3 ] != P [ 1 ] ,于是执行else 语句,j = next [1 ] = 0。再次比较 P[ 3 ] = P [ 0 ] ,于是 i = 4 , j = 1。P[ 4 ] = P [ 1 ] ,next [ 4 ] = next [ 1 ] = 0
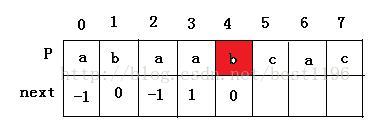
6 此时 i = 4 , j = 1,进入循环,P[ 4 ] = P [ 1 ] ,i= 5,j = 2 ,P[ 5 ] != P [ 2 ] ,next [ 5 ] = 2
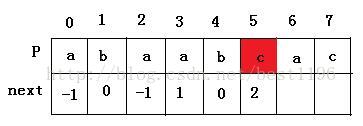
7 此时 i = 5 , j = 2 ,进入循环,P[ 5 ] != P [ 2 ] ,执行else 语句,j = next [2 ] = -1。于是i = 6 , j = 0。P[ 6 ] = P [ 0 ] ,则next [ 6 ] = next[0] = -1
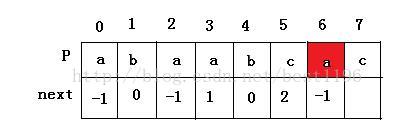
8 此时 i = 6, j = 0,进入循环,P[ 6 ] = P [ 0 ] ,i = 7 , j = 1 。P[ 7 ] != P [ 1 ] ,于是 next [ 7 ] = j = 1.
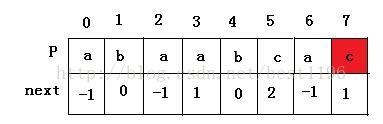
到此,整个求解 next 数组完成了。
KMP代码实现
#include <iostream>
using namespace std;
void get_next( const char* s , int len , int *next)
{
int i = 0;
next[0] = -1;
int j = -1;
while(i < len-1)
{
if( j == -1 || s[i] == s[j]) //j=-1:模式开始位置 s[i] = s[j] :模式将继续往前
{
++i;
++j;
if( s[i] != s[j])
next[i] = j;
else
next[i] = next[j];
}
else //当
j = next[j];
}
}
int kmp( const char* s, int slen, const char* p, int plen, const int* next, int pos)
{
int i = pos;
int j = 0;
while( i < slen && j < plen)
{
if( j == -1 || s[i] == p[j]) // s[i] == p[j] : 匹配则继续向前,s和p同时向前 j=-1表示从模式开头进行匹配
{
++i;
++j;
}
else //不匹配则模式回溯
j = next[j];
}
if( j >= plen)
return i-plen;
else
return -1;
}
int main()
{
char *str = "acabaabaabcacaabc";
char *p = "abaabcac";
int next[8] ={0};
get_next(p,8,next);
int pos = kmp(str,17,p,8,next,0);
cout << "pos:" << pos << endl;
for(int i = 0 ; i < 8 ; i++)
cout << next[i] << ' ' ;
cout << endl;
return 0;
}
转载该文章请注明作者和出处 ,请勿用于任何商业用途














 625
625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









