









这章节好难......要吐了....好几个知识点没弄明白,用法基本了解了,作用机制甚至参数调用规则还不是很理解
只能先写笔记了
上过stackoverflow或者segmentfault的时候,看到你在发表文章或者回答答案的时候,输入的同时,下面会有同步生成的效果
这样的预览框,实际上是支持MarkDown语法的,啥叫Markdown语法百度了下,基本上就是用很简单的符号,生成文本效果
这个章节中需要用到以下包
• PageDown:使用 JavaScript实现的客户端 Markdown 到 HTML 的转换程序。
• Flask-PageDown:为 Flask包装的 PageDown,把 PageDown集成到 Flask-WTF 表单中。
• Markdown:使用 Python实现的服务器端 Markdown到 HTML 的转换程序。
• Bleach:使用Python 实现的 HTML 清理器。
Flask-PageDown 扩展定义了一个PageDownField 类,这个类和WTForms 中的TextAreaField
接口一致。使用PageDownField 字段之前,先要初始化扩展
from flask.ext.pagedown import PageDown
#...
pagedown=PageDown()
#...
def create_app(config_name):
#...
pagedown.init_app(app)对于这样的需求,首页上面的文本输入框势必需要修改一下模板了,如下,将原来的TextAreaField修改成PageDownField
app/main/forms.py
from flask.ext.pagedown.fields import PageDownField
#...
class PostForm(Form):
body = PageDownField("What's on your mind?", validators=[Required()])
submit = SubmitField('Submit')Markdown 预览使用PageDown 库生成,因此要在模板中修改。Flask-PageDown 简化了这个过程,提供了一个模板宏,从CDN 中加载所需文件
上面这句后半段完全不知道说的是什么......忽略了,继续下面的
根据上面的信息,需要在app/index.html内引入pagedown这个扩展,跟前几章提到过的moment一样,他属于扩展功能,所以,引入需要用如下格式
{% block scripts %}
{{ super() }}
{{ pagedown.include_pagedown() }}
{% endblock %}
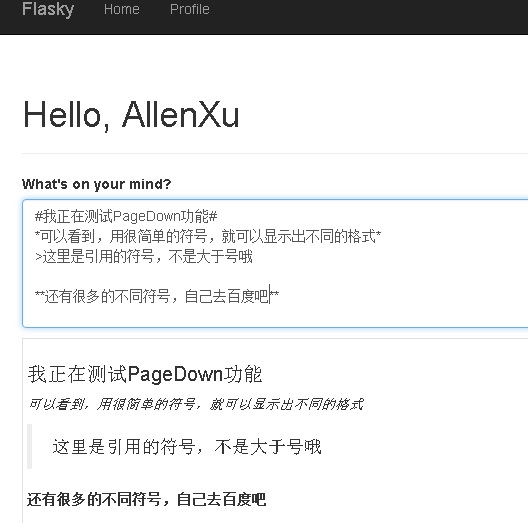
效果图如下,这样一遍输入,就能一遍看到预览了,这个在stackoverflow上面就是这么用的,感觉非常方便
------------------------------------------------------------------------------------------------------------------------------------------------------------------------
接着就要讲到最难弄的部分了,当你在文本框编辑好内容以后,你按了submit以后,他会将文本发送到服务器,然后服务器处理后,在po出来,显示在下面的列表
这个过程,里面就经历了很多步骤
提交表单后,POST 请求只会发送纯Markdown 文本,页面中显示的HTML 预览会被丢掉。和表单一起发送生成的HTML 预览有安全隐患,因为攻击者轻易就能修改HTML 代码,让其和Markdown 源不匹配,然后再提交表单。安全起见,只提交Markdown 源文本,在服务器上使用Markdown(使用Python 编写的Markdown 到HTML 转换程序)将其转换成HTML。得到HTML 后,再使用Bleach 进行清理,确保其中只包含几个允许使用的HTML 标签。把Markdown 格式的博客文章转换成HTML 的过程可以在_posts.html 模板中完成,但这么做效率不高,因为每次渲染页面时都要转换一次。为了避免重复工作,我们可在创建博客文章时做一次性转换。转换后的博客文章HTML 代码缓存在Post 模型的一个新字段中,在模板中可以直接调用。文章的Markdown 源文本还要保存在数据库中,以防需要编辑。
class Post(db.Model):
#...
body_html = db.Column(db.Text)
#...
<span style="white-space:pre"> </span>@staticmethod
def on_chenged_body(target,value,oldvalue,initiator):
allowed_tags=['a','abbr','acronym','b','blockquote','code',
'em','i','li','ol','pre','strong','ul',
'h1','h2','h3','p']
target.body_html = bleach.linkify(bleach.clean(
markdown(value,output_format='html'),tags = allowed_tags,strip=True))
db.event.listen(Post.body,'set',Post.on_chenged_body)字面上,value和oldvalue肯定是新值和老值,target指的是什么也没搞明白,感觉和下面的监听函数有关系
鉴定函数左边是监听的函数,就是看你输入进来的文本是什么,最右边的函数是调用上面的on_changed_body函数
而中间这个set也是有讲究的....这个set其实也拥有4个参数,和on_changed_body有的4个参数是一毛一样的,所以,我觉得set和上面静态方法的函数参数,是需要一一对应的.
这些只是我个人理解,还是要细细看源码,源码地址如下,先放着吧,反正功能是暂且搞清楚了。
http://docs.sqlalchemy.org/en/latest/orm/events.html
on_changed_body 函数注册在body 字段上,是SQLAlchemy“set”事件的监听程序,这意味着只要这个类实例的body 字段设了新值,函数就会自动被调用。on_changed_body 函数把body 字段中的文本渲染成HTML 格式,结果保存在body_html 中,自动且高效地完成Markdown 文本到HTML 的转换。真正的转换过程分三步完成。首先,markdown() 函数初步把Markdown 文本转换成HTML。然后,把得到的结果和允许使用的HTML 标签列表传给clean() 函数。clean() 函数删除所有不在白名单中的标签。转换的最后一步由linkify() 函数完成,这个函数由Bleach 提供,把纯文本中的URL 转换成适当的<a> 链接。最后一步是很有必要的,因为Markdown规范没有为自动生成链接提供官方支持。PageDown 以扩展的形式实现了这个功能,因此在服务器上要调用linkify() 函数。
最后,app/templates/_posts.html,这个宏文件还需要修改
...
<div class = "post-body">
{% if post.body_html %}
{{ post.body_html| safe}}
{% else %}
{{ post.body }}
{% endif %}
</div>
...
这里又挖了个坑啊,|safe查了半天没查出个所以然来......先放一下吧
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
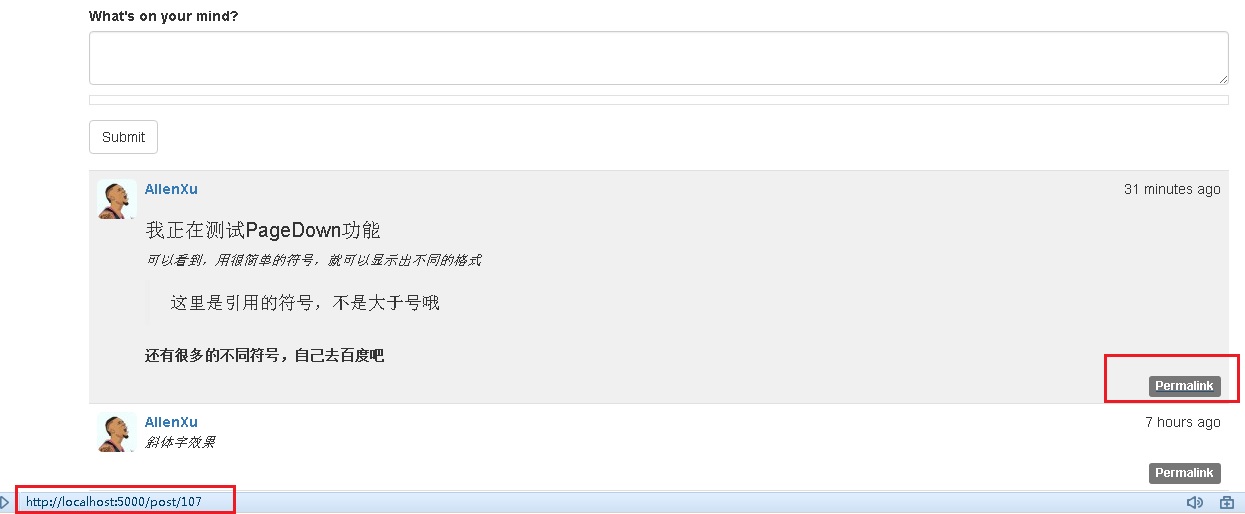
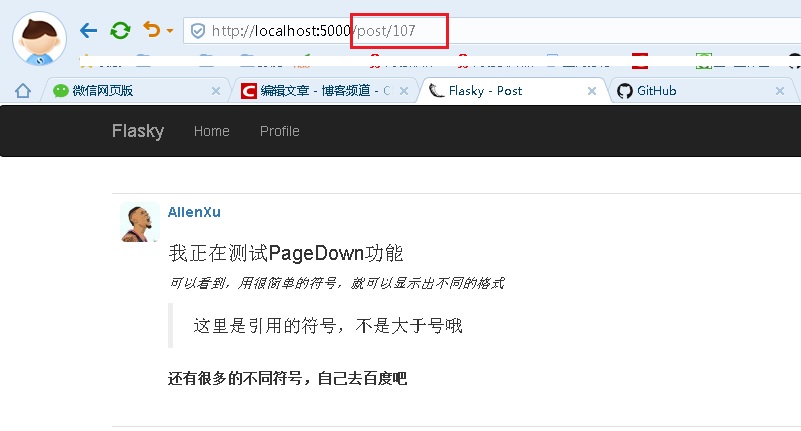
接着讲一个很普遍的功能,就是某篇文章的固定url,通过这个url我们就可以把这个文章分享给其他朋友了
对于固定url的文章,我们肯定要生成一个对应的路由函数
@main.route('/post/<int:id>')
def post(id):
<span style="white-space:pre"> </span>post = Post.query.get_or_404(id)
<span style="white-space:pre"> </span>return render_template('post.html', posts=[post])这里注意一点,书上也着重说明了一点,就是posts=[post]
书上是这么说的:post.html 模板接收一个列表作为参数,这个列表就是要渲染的文章。这里必须要传入列表,因为只有这样,index.html 和user.html 引用的_posts.html 模板才能在这个页面中使用。
什么意思呢?你往回过去可以发现,前面在模板中传入的posts,都是通过Post.query.xxxxxx.all()提取出来的,也就是说,本身就是一个列表形式,可以被迭代。
但是!!!这里根据id号分配出来的文章,他只是一个单独的文章,Post.query.get_or_404(id),所以你必须让他list化,才可以被后续的for post in posts迭代!!!
相对应的,在app/templates/_posts.html这个管理所有文章列表的宏里面,我们需要在每篇文章的页脚位置,增加这个文章单独页面显示的功能键.
<div class = "post-body">
{% if post.body_html %}
{{ post.body_html| safe }}
{% else %}
{{ post.body }}
{% endif %}
</div>
<div class = "post-footer">
<a href = "{{url_for('.post',id=post.id)}}">
<span class="label label-default">Permalink</span>
</a>
</div>














 254
254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









