







第三期百度计算广告学沙龙( http://wenku.baidu.com/course/view/1488bfd5b9f3f90f76c61b8d ) 介绍了内容匹配广告和展示广告相关技术。本博客记录观看内容匹配广告部分的一些笔记, 绝大多数为原slide内容,只做简单的整理。
背景
涉及四方:网民(Users) + 网站主 (Publishers) + 广告主(Advertisers) + 网盟 (AdNetwork/Matcher)
广告计费
计费方式
CPC 按点击收费
CPM 按展示收费
CPC+CPM 混合收费
广义二阶价格拍卖 (Generalized second price)
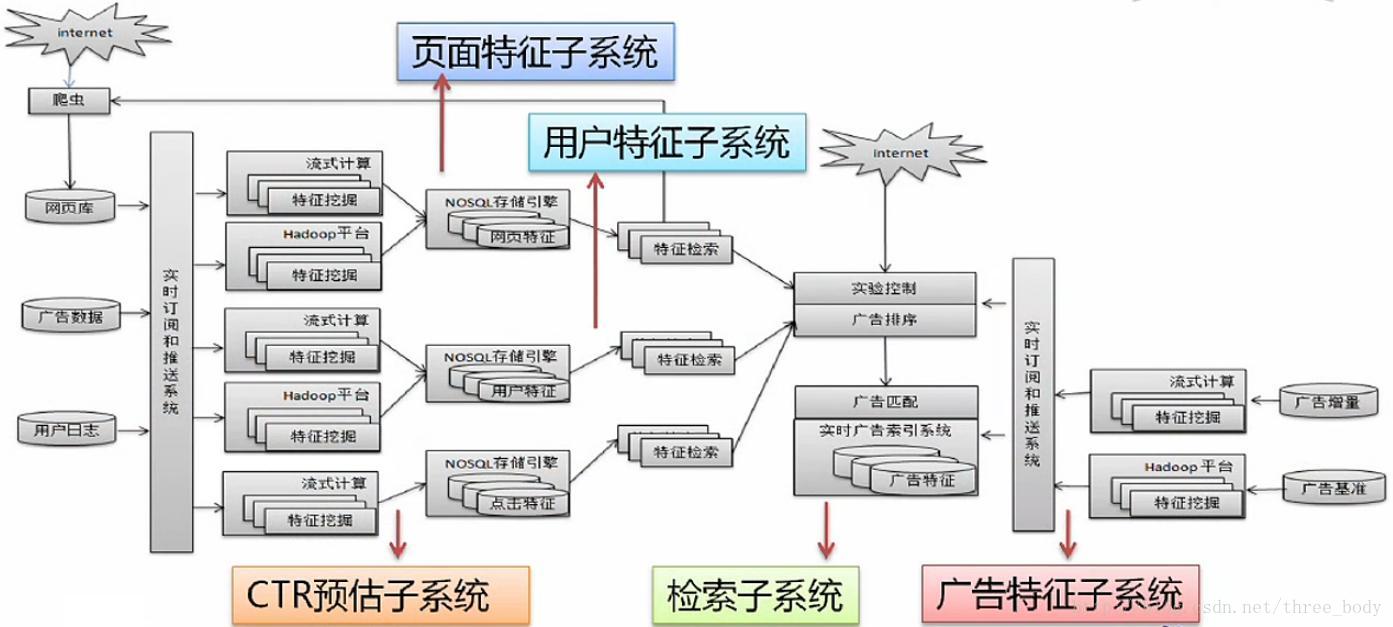
网盟广告检索系统
广告系统整体架构
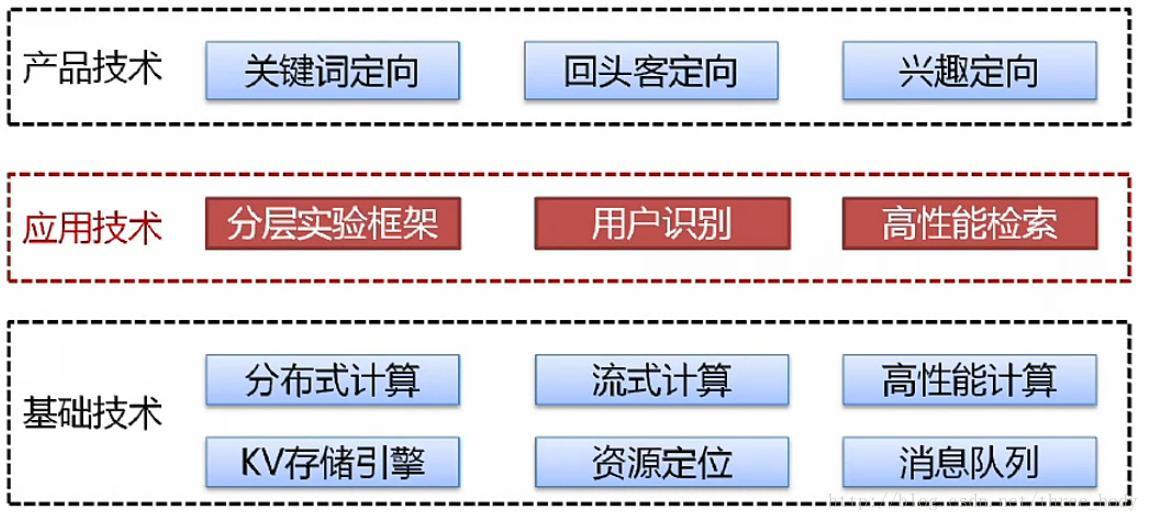
广告系统相关技术
应用技术 - 分层实验框架
AB-Test
用户实验/页面实验/随机实验
通过分层流量复用提高实验并发率
Reference: Overlapping Experiment Infrastructure: More, Better, Faster Experimentation (Google KDD 2010)
应用技术 - 用户识别
浏览器插件/客户端软件/HTTP Cookie/Flash Cookie/本地用户数据(如everCookie)/IP+UA/登陆帐号
用户识别技术新动向 - CookieMatching
应用技术 - 高性能检索
计算模型
触发策略->过滤策略->初选策略->精选策略 (广告量减少, 计算量增加)
网络模型

同步模型, 半异步模型, 全异步模型
慢Query对系统吞吐量影响
产生原因: 攻击行为, 实验引入, 服务bug, 网络抖动, 机器异常
监控处理: 比例波动检测以确定原因;自我保护,超过阈值则终端; Cache结果; 简化算法牺牲效果, 直接丢弃
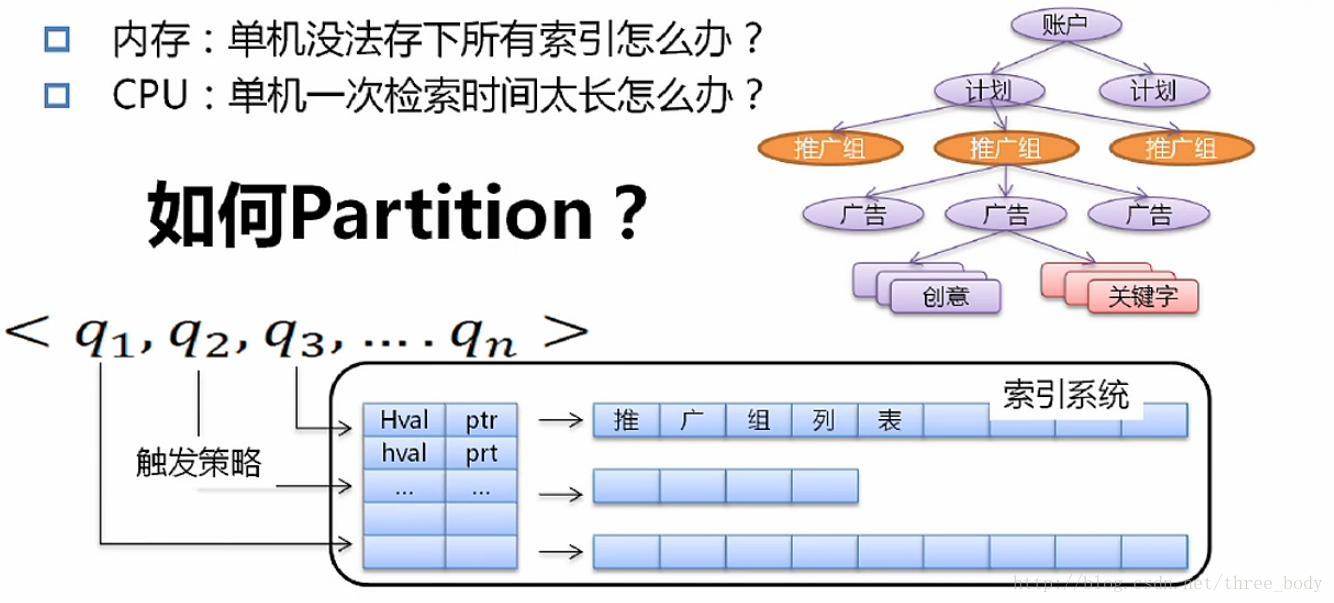
索引模型
广告库的逻辑结构
帐户->计划->推广组->广告
技术要求
实时性更新: 1s内生效, 高并发读写
高查询性能: 查询qps达到每秒100万 - 1000万
技术方案需要
无锁的并发模型
全内存的数据模型
无锁的并发模型
COW(Copy on Write) 读写分离
延迟销毁
索引扩展
划分: 数据均匀, 计算均匀, 计算重复, 数据重复,带宽增长
整体索引系统框架
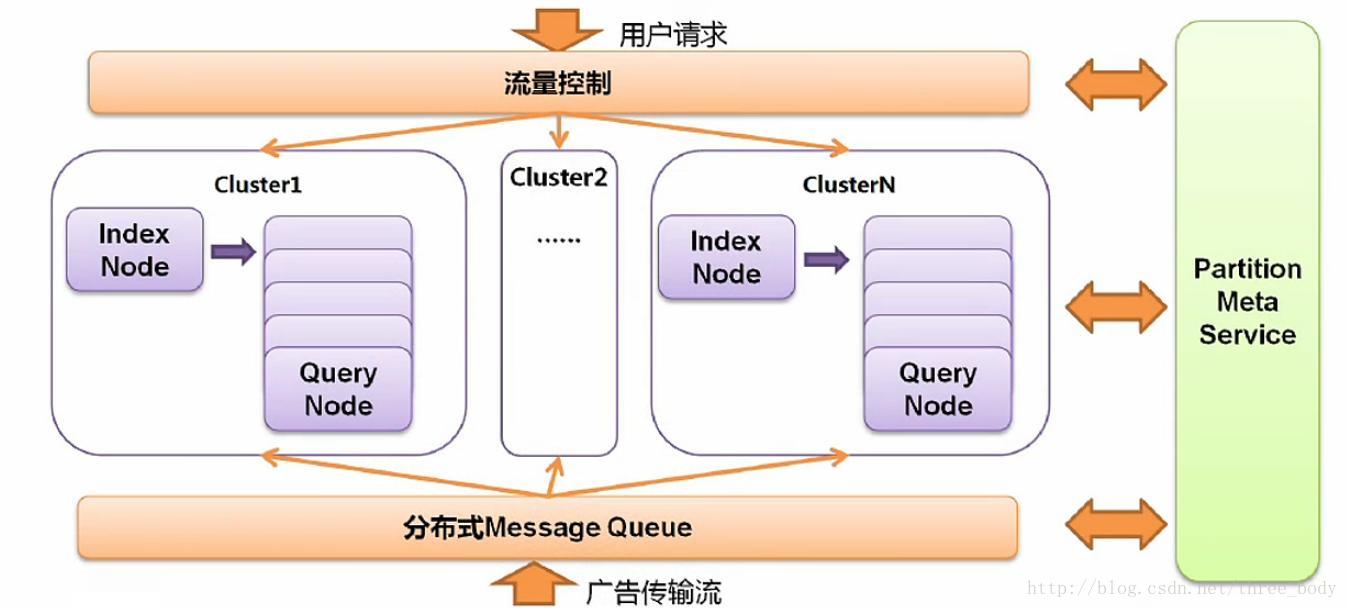
系统要求
高时效性; 高容错性 (实时检索服务, 特征存储服务, 数据推送服务); 高实验性; 高一致性; 高扩展性; 高可用性
网盟广告匹配算法
广告投放
按广告主表达方式分类
1. 关键词 (输入)
2. 标签(选择)
3. 规则(输入/选择)
按建模对象分类
1. 用户维度 - 以Cookie为建模对象
2. 流量维度 - 以当前URL为建模对象
其他分类维度
1. 时空维度:当前/历史,长期/短期,地域
2. 优化目标:品牌,展现,点击,转化
3. 数据来源:搜索、浏览
广告特点
1. 低点击率
2. 低margin
3. ROI难量化
4.用户体验难量化
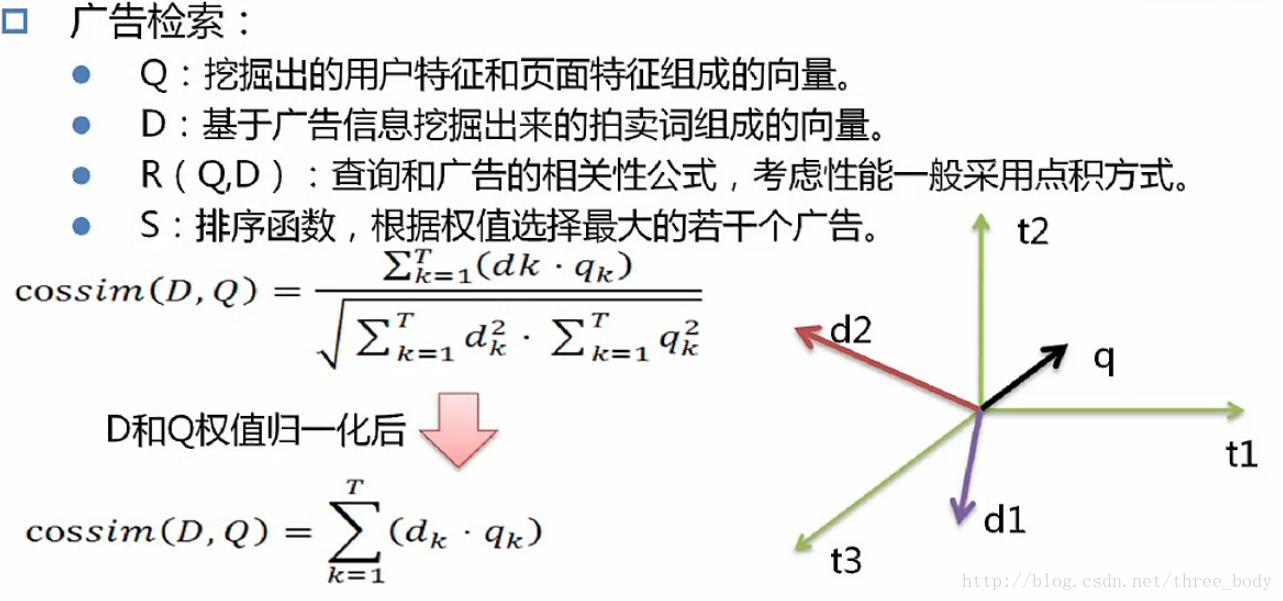
广告检索
广告检索漏斗模型
1. 片段触发; 2. 相关性排序; 3. 业务过滤; 4. CPM排序;5. 机制调整
效果与性能的折中
片段触发
片段来源: 1. 当前网页; 2. 用户历史行为
片段类型: 1. 关键词; 2. 用户/流量标签; 3. 规则模板
相关性排序
衡量匹配度: 1. Term Match; 2. Topic Match; 3. Category Match
相关性排序
综合考虑各个匹配度的回归模型
1. 人工语料标注
2. 模型训练
3. 随着语料规模的增加, 更多离散特征
4. 人工辅助规则(行业矩阵)
业务过滤
地域过滤,时间过滤,预算过滤,IP过滤,站点过滤,创意优选
CPM排序
eCPM排序
eCPM = bid * Q
price_i = (bid_(i+1) * Q_(i+1)) / Q_i
机制调整
过展现控制
Hidden Cost
广告对用户/站点体验的伤害
对排名CPM调整 CPM = (Bid - HC) * Q
对计费进行调整 Price = CPM(next) / Q + HC
页面特征提取
基础特征提取
页面结构特征
Refer Query提词
站点频道提词
流量质量划分
页面主题分类
Term赋权
统计维度:基本的TF*IDF赋权方式
结构维度:网页结构角度,主要是Term的位置
语义维度:从语义角度理解网页,利用篇章主题校验
广告库维度:关键词的购买信息
用户特征提取
历史Query特征
拍卖词包含匹配算法
切词/专名边界校验
语义相关性校验
Query分类
历史浏览特征
网页关键词提取
网页分类特征
历史广告点击
历史浏览页面模板
用户分类特征
特征提取
Query关键词
Query分类
站点
页面标题,目录,主要区域
页面分类
广告点击,广告分类
频次,组合,时间衰减
规则模型
特征挖掘
人工评估
决策树
机器学习模型
语料净化(先验语料,广告点击语料)
特征选择
模型构建(分类模型,lookalike,推荐模型)
效果评估
时效性
用户体验
用户体验
单调性(连续展现)
醒目度(多媒体多广告位)
敏感性(涉及敏感行业关键词)
用户反馈
兴趣
广告
Session特征分析 (连续用户行为)
关键词提取修正:如:魔兽宝宝->宝宝
意图识别: 购买/维修/查询
语义扩展
广告特征提取
拍卖词特征
结构分析
Term赋权
创意特征
文本创意 - 飘红, 关键词,长度
多媒体创意 - 颜色,形状,大小,语义
到达页特征
网页分析
页面主题
转化页/咨询页
广告特征应用
广告分类 - 行业,敏感,欺诈
不相关提词挖掘
相关性匹配
广告CTR预估问题
CTR预估要解决的问题
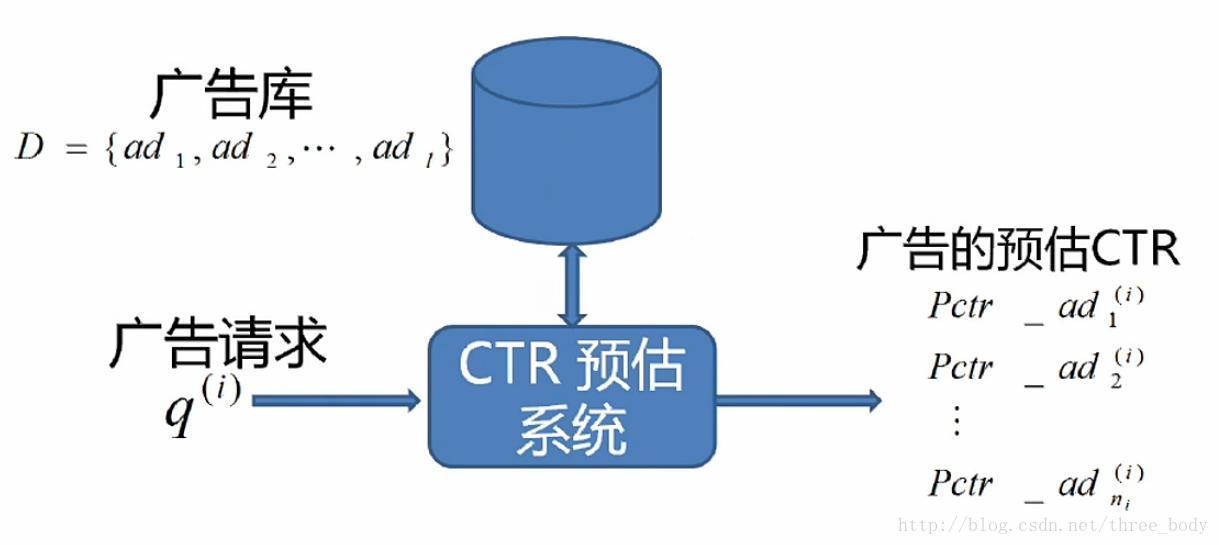
CTR预估问题的挑战
挑战1 - 数据
海量数据
训练样本:每天上亿级别的访问量
特征类型复杂:广告,用户,流量,季节,节假日等
点击率偏低
噪音数据多
问题:海量数据,高维特征,类别极端不平衡,噪音大
挑战2 - 时效性
CTR随时间改变 - 季节,兴趣
bad case快速下线 新广告, 新网站迭代调优
方法
在线算法
移动时间窗口的Batch算法
挑战3 - Exploration
CTR预估决定未来训练样本中的广告
Exploration/Exploitation trade-off
长期收益 vs 短期收益
从机器学习角度看CTR预估问题
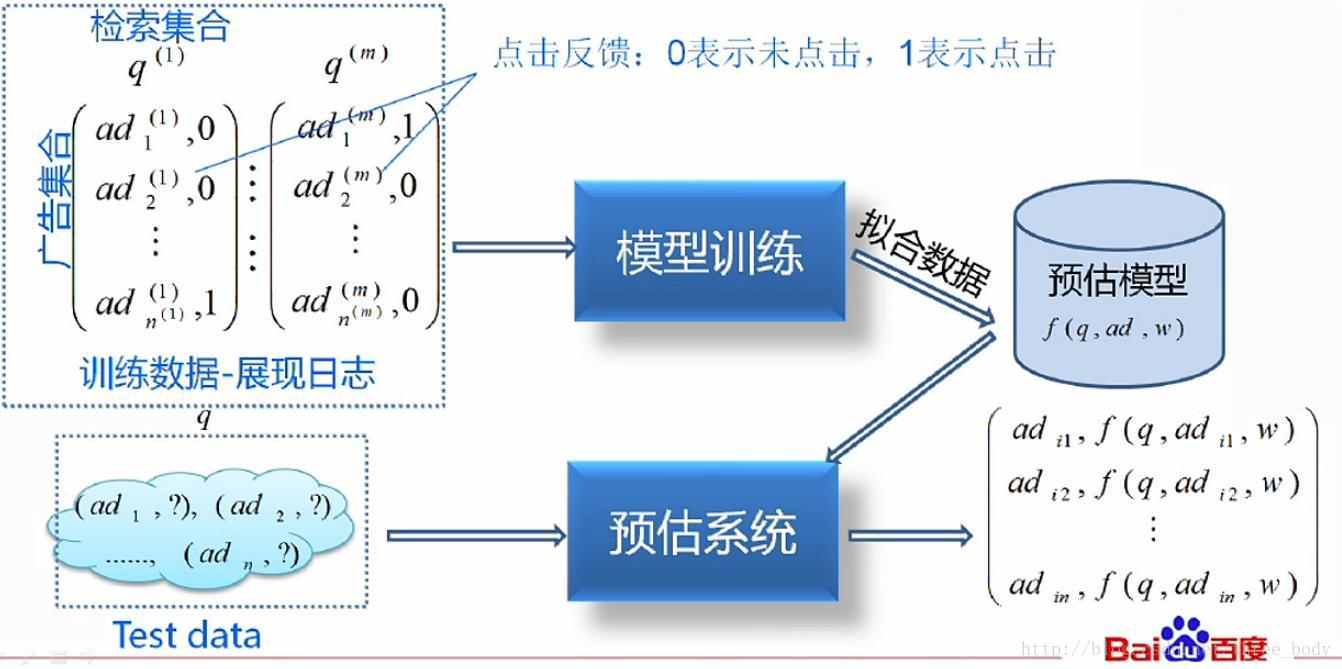
CTR预估问题的训练流程
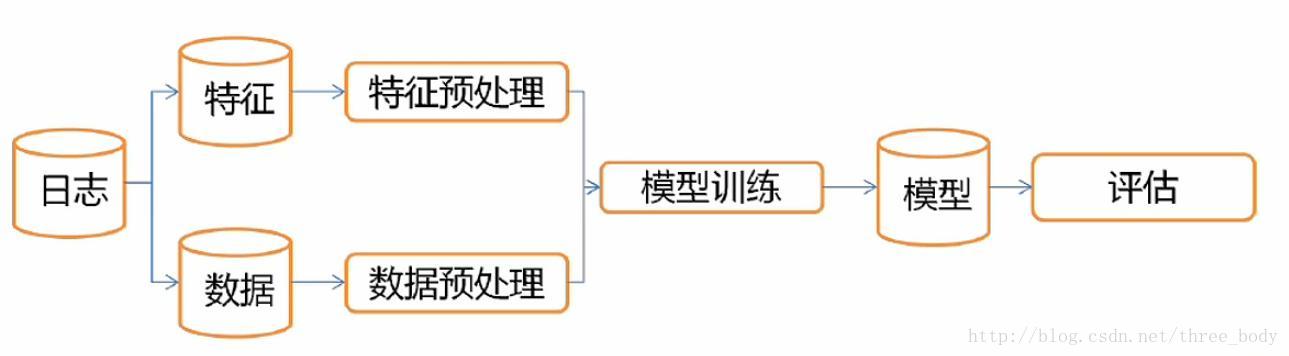
CTR预估问题的机器学习算法
特征
1. 主要特征
用户,流量广告
2. 特征类型
类别型特征 categorical features
连续值特征
3. 特征表示
使用one-hot编码
使用特征外积表示特征组合
特征维数表示类别个数和,特征个数海量
特征选择
1. Filter类
单特征AUC, 单特征AUC上界, gini指数,信息熵,点击直方图
2. Wrapper类
AUC, AUC上界,MAE, WMAE, 似然Loss, 预估CTR均值,预估CTR方差
3. embedding类
L1正则化 Grafting分 Foba分
数据
数据来源
展现日志,点击日志, 用户搜索日志等
数据处理
日志拼接,不全日志删除
数据净化
异常数据过滤 (去除噪音, 比如作弊数据)
不可见日志删除
模型
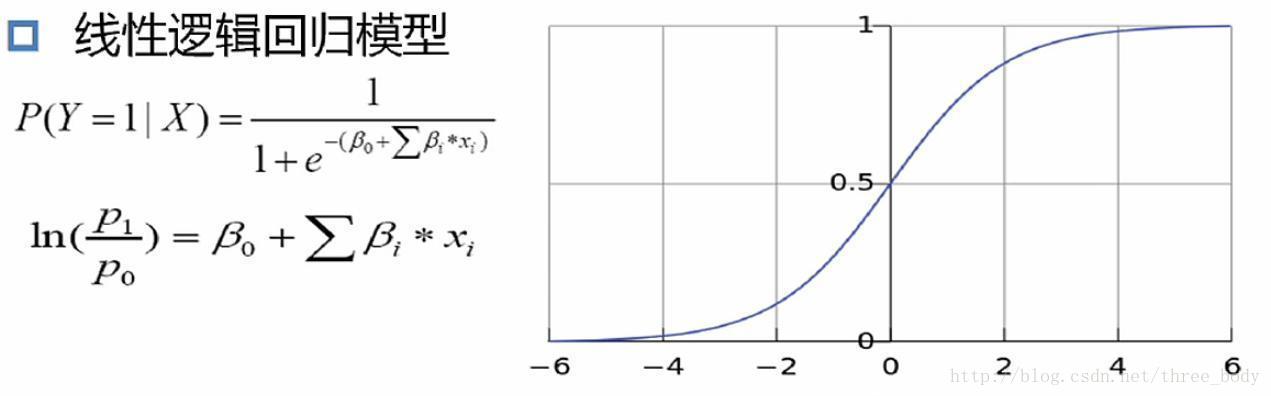
线性逻辑回归模型
参数估计
最大似然
基于拟牛顿迭代计算
模型训练
分布式并行计算
MPI (Message Passing Interface) 基于进程通信的计算模型, 适合模型训练
Hadoop: 基于Map-Reduce超大数据量并发计算, 适合数据预处理
模型更新
每过一定周期,重新训练模型
模型在线实时更新
评估系统
线上评估
通过流量对比,观察收入各项指标的影响,包括CTR, CPM, ACP, 到达, 二跳
线下评估
类别不平衡
模型排序能力: AUC
模型拟合能力: 对数拟然
大规模分布式机器学习算法
特征编码及选择
数据净化
大规模分布式训练
线上线下效果评估














 7834
7834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









