







本文主要内容来自于《Hadoop权威指南》英文版中的Spark章节,可以说是个人的翻译版本,涵盖了主要的Spark概念。如果想获得更好地阅读体验,可以访问这里.
安装Spark
首先从spark官网下载稳定的二进制分发版本,注意与你安装的Hadoop版本相匹配:
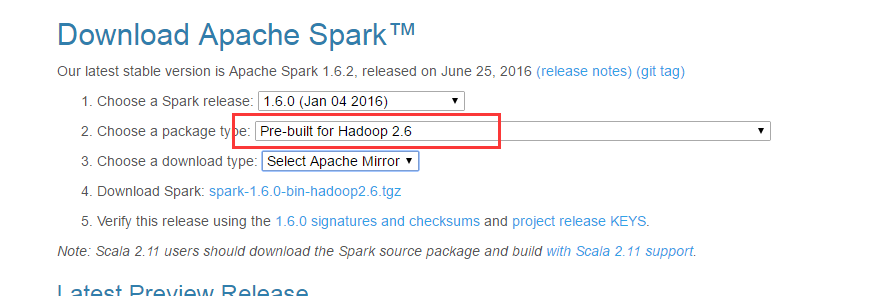
wget http://archive.apache.org/dist/spark/spark-1.6.0/spark-1.6.0-bin-hadoop2.6.tgz解压:
tar xzf spark-x.y.z-bin-distro.tgz为了方便运行,将bin目录添加到PATH中:
export SPARK_HOME=/home/spark/
export PATH=$PATH:$SPARK_HOME/bin完毕。
简单例子
Spark提供了交互式的Spark-shell,这是入门的好起点。spark-shell是基于Scala REPL的交互式工具。启动shell:
spark-shell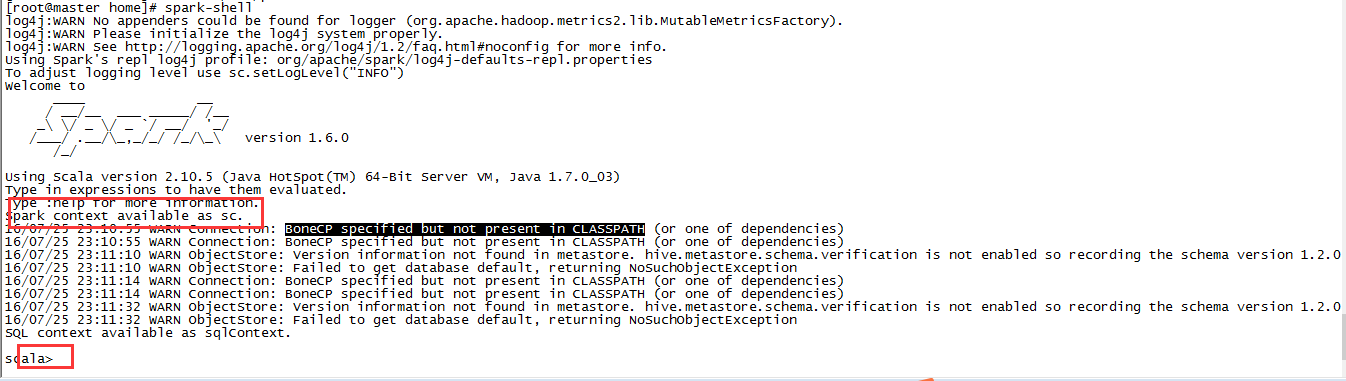
从输出中我们可以看到,shell创建了一个Scala变量,存放的是SparkContext的实例。我们使用sc加载一个文本文件:
val lines = sc.textFile("input/ncdc/sample.txt") 
lines变量引用的是一个RDD对象(Resilient Distributed Dataset)。RDD是Spark最核心的抽象,它是一个(通过分区,partitioned)分布在集群多台机器上的只读对象集合。
在一个典型的Spark应用程序中,一个或者多个RDD被载入作为输入,经过一系列的转化(transformation)之后变成目标RDD集合,然后一个动作(action)作用于这些RDD上,例如计算结果或者保存到持久化介质中。
RDD中的resilient是指:当一个RDD分区(partition)丢失之后,Spark会自动从其原始的RDD重新计算。加载RDD或者在RDD上调用transformation时,并没有触发真正的处理过程,Spark只是创建执行的计划。只有当action作用域RDD时,才会触发真正的数据处理,例如执行foreach().
接着前面载入的数据,拿到lines之后,我们想要把每一行的字段进行切分:
val records = lines.map( _.split("\t"))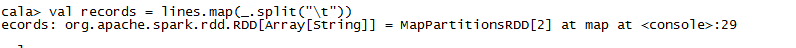
map方法将一个函数作用在RDD中的每一个元素上,这个例子中,split把每一行(RDD[String])转变成一个Scala的字符串数组(RDD[Array[String]])。
移除脏数据:
val filtered = records.filter( rec => (rec(1) !="9999" && rec(2).match("[01459]")))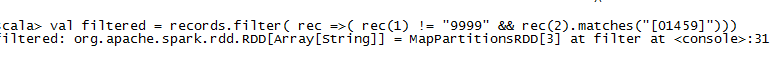
filer针对RDD中的每一个元素执行一个predicate判断,传入的是一个返回Boolean类型的函数,Scala中数组的访问访问是通过()操作。这里主要是过滤到脏数据。
为了找到每一年的最高温度,我们需要执行一个分组操作,Spark提供了reduceByKey的操作,但是只能应用在key-value类型的RDD(使用Scala的Tuple2来表示)上面,因此需要先做一次转换:
val tuples = filtered.map(rec => (rec(0).toInt,rec(1).toInt))
通过map操作来完成,将字符串素组转化为Int二元组,scala中调用方法时如果没有参数可以省略不写括号。转换之后我们就可以进行聚合操作:
val maxTemps = tuples.reduceByKey((a,b)=> Math.max(a,b))
reduceByKey接受一个函数,这个函数将一对值合并为一个值,然后不断应用在key对应的所有值上。假设1950这个key对应的记录有:
(1950,20) // 1
(1950,19) // 2
(1950,22) // 3reduceByKey操作会把max函数应用到1和2身上,即执行max(20,19),得到20,然后再把20跟第三条记录对比,得到最终的22. 我们把结果输出:
maxTemps.foreach(println(_))foreach是个action操作,针对RDD中的每个元素应用println(_)这个函数,这时候才会触发整个RDD链条执行计算,输出结果到控制台:
(1950,22)
(1949,111)我们也可以把计算结果保存到磁盘中:
maxTemps.saveAsTextFile("output")查看输出文件:
cat output/part-*Spark Applications,JObs,Stages , and Tasks
Spark中也有一些核心的概念。类似于MapReduce,Spark也有作业(job)的概念,但是更为通用一些,作业由任意的stage 有向无环图(DAG)组成,stage有点类似于MapReduce中的map或reduce阶段(phase)。
Spark运行时将Stage进一步被拆分为task,并在分布于集群上的RDD partitions并行运行。作业总是运行于Application的上下文中,这个上下文通过SparkContext来表示,用于组织相关的RDD和共享变量。一个Application可以并行或串行运行多个Job。Application提供了一种在同一个应用中共享数据集的机制,前面运行的作业可以将数据集缓存,后续的作业可以直接访问这些缓存的RDD。这与MapReduce中每个作业都需要从磁盘中读取输入数据是不同的。交互式的Spark会话如Spark-shell就是一个应用实例。
一个Scala应用程序
spark-shell提供了一种探索和学习Spark很好的方式,但是实际中经常需要将业务逻辑作为一个自包含的、完整的应用打包在一起,可以多次运行。下面是一个Scala应用的例子:
import org.apache.spark.SparkContext._
import org.apche.spark.{SparkContext,SparkConf}
object MaxxTemperature{
def main(agrs: Array[String]) {
val conf = new SparkConf().setAppName("Max Temperature")
val sc = new SparkContext(conf)
sc.textFile(agrs[0]))
.map(_.split("\t"))
.filter(rec => (rec(1) != "9999" && rec(2).match("[01459]")))
.map(rec => (rec(0).toInt , rec(1).toInt))
.reduceByKey( (a,b) => Math.max(a,b))
.saveAsTextFile(args(1))
}
}当作为一个独立的应用时,我们需要自己创建SparkContext,因为没有shell提供这个对象给我们。SparkConf用于配置应用的各个属性,这里我们只设置了应用名称。
Spark
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 486
486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









