








 超级会员免费看
超级会员免费看

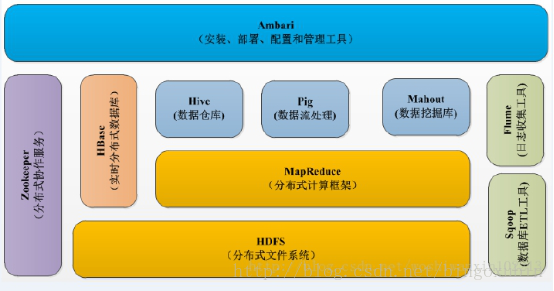
 本文介绍了MapReduce在大数据处理中的应用场景及其操作步骤。MapReduce是Hadoop的重要组成部分,用于解决大数据的计算问题。文章通过实例解释了Map和Reduce的概念,并详细描述了MapReduce的工作流程,包括数据划分、Map操作、Reduce操作以及整个计算过程。
本文介绍了MapReduce在大数据处理中的应用场景及其操作步骤。MapReduce是Hadoop的重要组成部分,用于解决大数据的计算问题。文章通过实例解释了Map和Reduce的概念,并详细描述了MapReduce的工作流程,包括数据划分、Map操作、Reduce操作以及整个计算过程。
本文介绍了MapReduce在大数据处理中的应用场景及其操作步骤。MapReduce是Hadoop的重要组成部分,用于解决大数据的计算问题。文章通过实例解释了Map和Reduce的概念,并详细描述了MapReduce的工作流程,包括数据划分、Map操作、Reduce操作以及整个计算过程。
本文介绍了MapReduce在大数据处理中的应用场景及其操作步骤。MapReduce是Hadoop的重要组成部分,用于解决大数据的计算问题。文章通过实例解释了Map和Reduce的概念,并详细描述了MapReduce的工作流程,包括数据划分、Map操作、Reduce操作以及整个计算过程。

 订阅专栏 解锁全文
订阅专栏 解锁全文

















08-17
 421
421
421
04-19
382
382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











