










今天学习和介绍一个有用的工具,来自TOM大神的show_space,其实这就是一个存储过程,用他可以统计一些段的用度,非常方便,网上流传着不同的版本。
首先我们看下原版的脚本,https://asktom.oracle.com/pls/apex/f?p=100:11:0::::P11_QUESTION_ID:5350053031470
create or replace
procedure show_space
( p_segname in varchar2,
p_owner in varchar2 default user,
p_type in varchar2 default 'TABLE',
p_partition in varchar2 default NULL )
authid current_user
as
l_free_blks number;
l_total_blocks number;
l_total_bytes number;
l_unused_blocks number;
l_unused_bytes number;
l_LastUsedExtFileId number;
l_LastUsedExtBlockId number;
l_LAST_USED_BLOCK number;
procedure p( p_label in varchar2, p_num in number )
is
begin
dbms_output.put_line( rpad(p_label,40,'.') ||
p_num );
end;
begin
for x in ( select tablespace_name
from dba_tablespaces
where tablespace_name = ( select tablespace_name
from dba_segments
where segment_type = p_type
and segment_name = p_segname
and SEGMENT_SPACE_MANAGEMENT <> 'AUTO' )
)
loop
dbms_space.free_blocks
( segment_owner => p_owner,
segment_name => p_segname,
segment_type => p_type,
partition_name => p_partition,
freelist_group_id => 0,
free_blks => l_free_blks );
end loop;
dbms_space.unused_space
( segment_owner => p_owner,
segment_name => p_segname,
segment_type => p_type,
partition_name => p_partition,
total_blocks => l_total_blocks,
total_bytes => l_total_bytes,
unused_blocks => l_unused_blocks,
unused_bytes => l_unused_bytes,
LAST_USED_EXTENT_FILE_ID => l_LastUsedExtFileId,
LAST_USED_EXTENT_BLOCK_ID => l_LastUsedExtBlockId,
LAST_USED_BLOCK => l_LAST_USED_BLOCK );
p( 'Free Blocks', l_free_blks );
p( 'Total Blocks', l_total_blocks );
p( 'Total Bytes', l_total_bytes );
p( 'Total MBytes', trunc(l_total_bytes/1024/1024) );
p( 'Unused Blocks', l_unused_blocks );
p( 'Unused Bytes', l_unused_bytes );
p( 'Last Used Ext FileId', l_LastUsedExtFileId );
p( 'Last Used Ext BlockId', l_LastUsedExtBlockId );
p( 'Last Used Block', l_LAST_USED_BLOCK );
end;/
从原版来看,根据dba_tablespaces、dba_segments检索出表空间的名称,使用dbms_space包的free_blocks和unused_space计算相应空间,格式化输出,其中有一点需要注意,就是只会统计SEGMENT_SPACE_MANAGEMENT <> 'AUTO'的表空间,即MANUAL手工管理的表空间。
这个脚本最开始是2002年针对9i版本发布的帖子,


直到2014年,还有人跟帖,足以见其影响力,

我们用实验来体会一下,创建测试表,

执行存储过程,
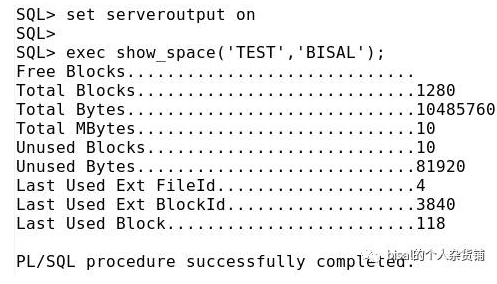
删除数据,
空间不会释放,
truncate数据,
此时表空间则被初始化,
我们看几个改良的版本,
(1) 惜分飞版本,
http://www.xifenfei.com/2011/09/tom%E7%9A%84show_space%E8%BF%87%E7%A8%8B%E4%BD%BF%E7%94%A8.html
create or replace procedure show_space
( p_segname_1 in varchar2,
p_owner_1 in varchar2 default user,
p_type_1 in varchar2 default 'TABLE',
p_space in varchar2 default 'AUTO',
p_analyzed in varchar2 default 'Y'
)
as
p_segname varchar2(100);
p_type varchar2(10);
p_owner varchar2(30);
l_unformatted_blocks number;
l_unformatted_bytes number;
l_fs1_blocks number;
l_fs1_bytes number;
l_fs2_blocks number;
l_fs2_bytes number;
l_fs3_blocks number;
l_fs3_bytes number;
l_fs4_blocks number;
l_fs4_bytes number;
l_full_blocks number;
l_full_bytes number;
l_free_blks number;
l_total_blocks number;
l_total_bytes number;
l_unused_blocks number;
l_unused_bytes number;
l_LastUsedExtFileId number;
l_LastUsedExtBlockId number;
l_LAST_USED_BLOCK number;
procedure p( p_label in varchar2, p_num in number )
is
begin
dbms_output.put_line( rpad(p_label,40,'.') ||
p_num );
end;
begin
p_segname := upper(p_segname_1); -- rainy changed
p_owner := upper(p_owner_1);
p_type := p_type_1;
if (p_type_1 = 'i' or p_type_1 = 'I') then --rainy changed
p_type := 'INDEX';
end if;
if (p_type_1 = 't' or p_type_1 = 'T') then --rainy changed
p_type := 'TABLE';
end if;
if (p_type_1 = 'c' or p_type_1 = 'C') then --rainy changed
p_type := 'CLUSTER';
end if;
dbms_space.unused_space
( segment_owner => p_owner,
segment_name => p_segname,
segment_type => p_type,
total_blocks => l_total_blocks,
total_bytes => l_total_bytes,
unused_blocks => l_unused_blocks,
unused_bytes => l_unused_bytes,
LAST_USED_EXTENT_FILE_ID => l_LastUsedExtFileId,
LAST_USED_EXTENT_BLOCK_ID => l_LastUsedExtBlockId,
LAST_USED_BLOCK => l_LAST_USED_BLOCK );
if p_space = 'MANUAL' or (p_space <> 'auto' and p_space <> 'AUTO') then
dbms_space.free_blocks
( segment_owner => p_owner,
segment_name => p_segname,
segment_type => p_type,
freelist_group_id => 0,
free_blks => l_free_blks );
p( 'Free Blocks', l_free_blks );
end if;
p( 'Total Blocks', l_total_blocks );
p( 'Total Bytes', l_total_bytes );
p( 'Unused Blocks', l_unused_blocks );
p( 'Unused Bytes', l_unused_bytes );
p( 'Last Used Ext FileId', l_LastUsedExtFileId );
p( 'Last Used Ext BlockId', l_LastUsedExtBlockId );
p( 'Last Used Block', l_LAST_USED_BLOCK );
/*IF the segment is analyzed */
if p_analyzed = 'Y' then
dbms_space.space_usage(segment_owner => p_owner ,
segment_name => p_segname ,
segment_type => p_type ,
unformatted_blocks => l_unformatted_blocks ,
unformatted_bytes => l_unformatted_bytes,
fs1_blocks => l_fs1_blocks,
fs1_bytes => l_fs1_bytes ,
fs2_blocks => l_fs2_blocks,
fs2_bytes => l_fs2_bytes,
fs3_blocks => l_fs3_blocks ,
fs3_bytes => l_fs3_bytes,
fs4_blocks => l_fs4_blocks,
fs4_bytes => l_fs4_bytes,
full_blocks => l_full_blocks,
full_bytes => l_full_bytes);
dbms_output.put_line(rpad(' ',50,'*'));
dbms_output.put_line('The segment is analyzed');
p( '0% -- 25% free space blocks', l_fs1_blocks);
p( '0% -- 25% free space bytes', l_fs1_bytes);
p( '25% -- 50% free space blocks', l_fs2_blocks);
p( '25% -- 50% free space bytes', l_fs2_bytes);
p( '50% -- 75% free space blocks', l_fs3_blocks);
p( '50% -- 75% free space bytes', l_fs3_bytes);
p( '75% -- 100% free space blocks', l_fs4_blocks);
p( '75% -- 100% free space bytes', l_fs4_bytes);
p( 'Unused Blocks', l_unformatted_blocks );
p( 'Unused Bytes', l_unformatted_bytes );
p( 'Total Blocks', l_full_blocks);
p( 'Total bytes', l_full_bytes);
end if;
end;
/
其特点就是,可以接受AUTO类型管理的表空间,可以接受I、T、C作为索引、堆表和聚簇表的简写,如果段已被分析,则回显中会包含空闲空间块百分比,更直观展示表的使用情况,
(2) Dave版本
http://blog.csdn.net/tianlesoftware/article/details/8151129
CREATE OR REPLACE PROCEDURE show_space (
p_segname_1 IN VARCHAR2,
p_type_1 IN VARCHAR2 DEFAULT 'TABLE',
p_space IN VARCHAR2 DEFAULT'MANUAL',
p_analyzed IN VARCHAR2 DEFAULT 'N',
p_partition_1 IN VARCHAR2 DEFAULTNULL,
p_owner_1 IN VARCHAR2 DEFAULT USER)
AUTHID CURRENT_USER
AS
p_segname VARCHAR2 (100);
p_type VARCHAR2 (30);
p_owner VARCHAR2 (30);
p_partition VARCHAR2 (50);
l_unformatted_blocks NUMBER;
l_unformatted_bytes NUMBER;
l_fs1_blocks NUMBER;
l_fs1_bytes NUMBER;
l_fs2_blocks NUMBER;
l_fs2_bytes NUMBER;
l_fs3_blocks NUMBER;
l_fs3_bytes NUMBER;
l_fs4_blocks NUMBER;
l_fs4_bytes NUMBER;
l_full_blocks NUMBER;
l_full_bytes NUMBER;
l_free_blks NUMBER;
l_total_blocks NUMBER;
l_total_bytes NUMBER;
l_unused_blocks NUMBER;
l_unused_bytes NUMBER;
l_LastUsedExtFileId NUMBER;
l_LastUsedExtBlockId NUMBER;
l_LAST_USED_BLOCK NUMBER;
PROCEDURE p (p_label IN VARCHAR2,p_num IN NUMBER)
IS
BEGIN
DBMS_OUTPUT.put_line (RPAD(p_label, 40, '.') || p_num);
END;
BEGIN
p_segname := UPPER (p_segname_1);
p_owner := UPPER (p_owner_1);
p_type := p_type_1;
p_partition := UPPER(p_partition_1);
IF (p_type_1 = 'i' OR p_type_1 ='I')
THEN
p_type := 'INDEX';
END IF;
IF (p_type_1 = 't' OR p_type_1 ='T')
THEN
p_type := 'TABLE';
END IF;
IF (p_type_1 = 'tp' OR p_type_1 ='TP')
THEN
p_type := 'TABLE PARTITION';
END IF;
IF (p_type_1 = 'ip' OR p_type_1 = 'IP')
THEN
p_type := 'INDEX PARTITION';
END IF;
IF (p_type_1 = 'c' OR p_type_1 ='C')
THEN
p_type := 'CLUSTER';
END IF;
DBMS_SPACE.UNUSED_SPACE (
segment_owner => p_owner,
segment_name => p_segname,
segment_type => p_type,
partition_name => p_partition,
total_blocks => l_total_blocks,
total_bytes => l_total_bytes,
unused_blocks => l_unused_blocks,
unused_bytes => l_unused_bytes,
LAST_USED_EXTENT_FILE_ID => l_LastUsedExtFileId,
LAST_USED_EXTENT_BLOCK_ID => l_LastUsedExtBlockId,
LAST_USED_BLOCK => l_LAST_USED_BLOCK);
IF p_space = 'MANUAL' OR (p_space<> 'auto' AND p_space <> 'AUTO')
THEN
DBMS_SPACE.FREE_BLOCKS (segment_owner => p_owner,
segment_name =>p_segname,
segment_type => p_type,
partition_name =>p_partition,
freelist_group_id => 0,
free_blks =>l_free_blks);
p ('Free Blocks', l_free_blks);
END IF;
p ('Total Blocks',l_total_blocks);
p ('Total Bytes', l_total_bytes);
p ('Unused Blocks',l_unused_blocks);
p ('Unused Bytes',l_unused_bytes);
p ('Last Used Ext FileId',l_LastUsedExtFileId);
p ('Last Used Ext BlockId', l_LastUsedExtBlockId);
p ('Last Used Block',l_LAST_USED_BLOCK);
/*IF the segment is analyzed */
IF p_analyzed = 'Y'
THEN
DBMS_SPACE.SPACE_USAGE(segment_owner => p_owner,
segment_name => p_segname,
segment_type => p_type,
partition_name =>p_partition,
unformatted_blocks => l_unformatted_blocks,
unformatted_bytes =>l_unformatted_bytes,
fs1_blocks =>l_fs1_blocks,
fs1_bytes =>l_fs1_bytes,
fs2_blocks =>l_fs2_blocks,
fs2_bytes => l_fs2_bytes,
fs3_blocks =>l_fs3_blocks,
fs3_bytes =>l_fs3_bytes,
fs4_blocks =>l_fs4_blocks,
fs4_bytes => l_fs4_bytes,
full_blocks =>l_full_blocks,
full_bytes =>l_full_bytes);
DBMS_OUTPUT.put_line (RPAD ('', 50, '*'));
DBMS_OUTPUT.put_line ('Thesegment is analyzed');
p ('0% -- 25% free spaceblocks', l_fs1_blocks);
p ('0% -- 25% free spacebytes', l_fs1_bytes);
p ('25% -- 50% free spaceblocks', l_fs2_blocks);
p ('25% -- 50% free spacebytes', l_fs2_bytes);
p ('50% -- 75% free spaceblocks', l_fs3_blocks);
p ('50% -- 75% free spacebytes', l_fs3_bytes);
p ('75% -- 100% free spaceblocks', l_fs4_blocks);
p ('75% -- 100% free spacebytes', l_fs4_bytes);
p ('Unused Blocks', l_unformatted_blocks);
p ('Unused Bytes',l_unformatted_bytes);
p ('Total Blocks',l_full_blocks);
p ('Total bytes',l_full_bytes);
END IF;
END;
/
这个版本是(1)的基础上支持了分区,以及接受IP和TP作为索引分区和表分区的简写。
另外,以下文章中有类似show_space的改良版,但逻辑原理基本一致,可以根据自己的需求,选择适合自己的一个版本,
http://blog.csdn.net/indexman/article/details/47207987
http://blog.csdn.net/huang_xw/article/details/7015349
总结:
1. show_space这个存储过程可以方便我们统计表/索引/聚簇表等段的使用情况,不用写一些SQL来实现此目标。
2. show_space有不同版本,有的支持分区,有的支持各种不同段的简写,有的支持细粒度的统计,根据自己的需求,选择一款适合自己的版本,了解其中的实现原理,将工具的设计思想,据为己用,触类旁通,甚至可以进行一些改造。
如果您觉得此篇文章对您有帮助,欢迎关注微信公众号:bisal的个人杂货铺,您的支持是对我最大的鼓励!共同学习,共同进步:)














 240
240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









