









Android控件架构
本文是读了《Android 群英传》第三章--Android体控件架构与自定义空间详解--之后的读书笔记,感谢作者,在此特别推荐此书。
Android里每一个界面都来来自于Window类,该类是一个抽象类,提供了绘制窗口的一组通用API。可以将之理解为一个载体,各种View在这个载体上显示。如图所示:

Window类有两个实现类,PhoneWindow和MidWindow,通常情况下Android的Window类都是用PhoneWindow来实现的。在PhoneWindow类内部包含了一个DecorView对象,该DectorView对象是所有应用窗口(Activity界面)的根View,封装了一些窗口操作的通用方法,将整个屏幕要显示的具体内容呈现在PhoneWindow上。DectorView将屏幕分为两个部分,TileView(即标题栏)和ContentView(即内容栏),比如Activity里的setContentView就是设置该Activity的显示界面。
用一个经典例子说明下就是Window类相当于一幅画(抽象概念,什么画我们未知) ,PhoneWindow为一副齐白石先生的山水画(具体概念,我们知道了是谁的、什么性质的画),DecorView则为该山水画的具体内容(有山、有水、有树,各种界面)。
Android中一个控件都会在界面里占用一块可绘制的矩形区域,可分为两类,ViewGroup类和View类。其中,View是所有UI组件的基类,而ViewGroup是容纳这些组件的容器,其本身也是View的子类。从控件上说,ViewGroup控件可以包含作为叶子节点的View,也可以包含作为更低层次的子ViewGroup控件,整个界面上形成了一个树形结构,如下所示:
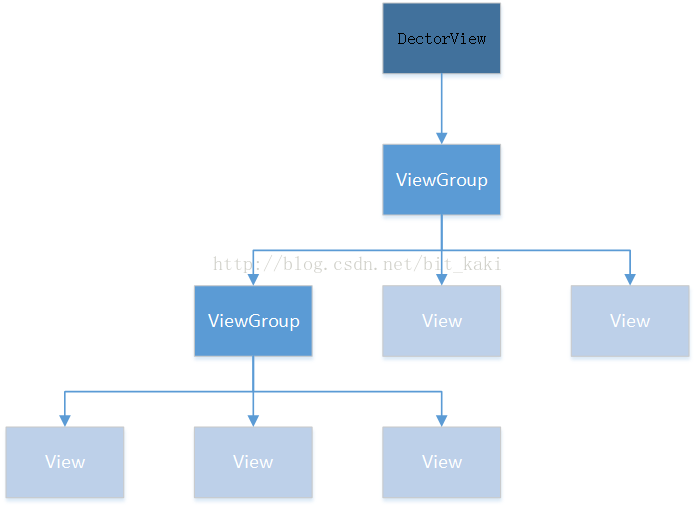
之前说到的DectorView就是一个ViewGroup,Android的通过这个树形结构从上往下通过递归的方式控制着每个子控件的测量和绘制,并传递交互事件。














 355
355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









