







项目github地址:bitcarmanlee easy-algorithm-interview-and-practice
欢迎大家star,留言,一起学习进步
1.前言
一般提到特征值分解(eigenvalue decomposition)或者奇异值分解(singular value decomposition),大多数同学脑海里的第一反应就是一大堆矩阵以及数学计算方法。确实,学校学习阶段,不管是学线性代数或者矩阵分析,对于这部分内容,或者说绝大部分内容,老师一上来都是吧啦吧啦给你一堆定理推论或者公理,然后就是哗啦哗啦一堆公式出来,告诉你怎么计算。最后再讲个一两道例题,这个知识点就算讲完了。至于这些公式的来龙去脉,尤其是这些公式定理在实际中有什么用,能解决什么实际问题,老师很少有谈及。所以大家普遍反映对于线性代数矩阵分析这类课程,觉得特别枯燥。学完以后,即使考试过了会做题,随便再问几个为什么,基本也是一脸懵逼的状态。至少我当年的学习经历就是这样滴。
等出学校以后发现,实际上在学校学的这些内容,都是非常有用而且有明确的数学或者物理意义的。在学校的时候,老师一般都会告诉你这个很有用,但是给解释清楚的,确实很少。今天,我就按照自己的理解,试图给大家将特征值分解与SVD的来龙去脉解释清楚。如果有哪里不对或者理解有偏差,还请大家海涵并指出。
2.特征值、特征向量、特征值分解
特征值特征向量是贯穿整个线性代数与矩阵分析的主线之一。那么特征值特征向量除了课本上公式的描述以外,到底有什么实际意义呢?
在http://blog.csdn.net/bitcarmanlee/article/details/52067985一文中,为大家解释了一个核心观点:矩阵是线性空间里的变换的描述。在有了这个认识的基础上,咱们接着往下。
特征值的定义很简单:
A
x
=
λ
x
Ax = \lambda x
Ax=λx。其中
A
A
A为矩阵,
λ
\lambda
λ为特征值,
x
x
x为特征向量。不知道大家想过没有:为什么一个向量,跟一个数相乘的效果,与跟一个矩阵的效果相乘是一样的呢?
这得用到我们先前的结论:矩阵是线性空间里的变换的描述。矩阵
A
A
A与向量相乘,本质上对向量
x
x
x进行一次线性转换(旋转或拉伸),而该转换的效果为常数
c
c
c乘以向量
x
x
x(即只进行拉伸)。当我们求特征值与特征向量的时候,就是为了求矩阵
A
A
A能使哪些向量(特征向量)只发生拉伸,而拉伸的程度,自然就是特征值
λ
\lambda
λ了。
如果还有同学没有看懂,再引用wiki百科上的一个描述:
N
N
N 维非零向量
x
x
x 是
N
×
N
N×N
N×N 的矩阵
A
A
A 的特征向量,当且仅当下式成立:
A
x
=
λ
x
Ax = \lambda x
Ax=λx
其中
λ
\lambda
λ为一标量,称为
x
x
x对应的特征值。也称
x
x
x为特征值
λ
\lambda
λ对应的特征向量。也即特征向量被施以线性变换
A
A
A只会使向量伸长或缩短而其方向不被改变。
对于一个矩阵
A
A
A,有一组特征向量;再将这组向量进行正交化单位化,也就是我们学过的Schmidt正交化,就能得到一组正交单位向量。特征值分解,就是将矩阵
A
A
A分解为如下方式:
A
=
Q
Σ
Q
−
1
A = Q \Sigma Q^{-1}
A=QΣQ−1
这其中, Q Q Q是矩阵 A A A的特征向量组成的矩阵, Σ \Sigma Σ则是一个对角阵,对角线上的元素就是特征值。
为了描述更清楚,引用网络上的一部分描述:
对于一个矩阵
M
M
M:
M
=
[
3
0
0
1
]
M=\left [ \begin{matrix} 3 & 0 \\ 0 & 1 \\ \end{matrix} \right ]
M=[3001]
它对应的线性变换是下面的形式:
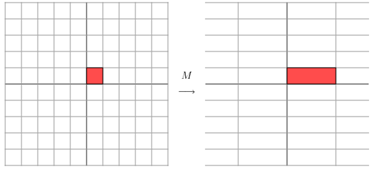
因为这个矩阵M乘以一个向量(x,y)的结果是:
[
3
0
0
1
]
[
x
y
]
=
[
3
x
y
]
\left [ \begin{matrix} 3 & 0 \\ 0 & 1 \\ \end{matrix} \right ] \left [ \begin{matrix} x \\ y \\ \end{matrix} \right ] = \left [ \begin{matrix} 3x \\ y \\ \end{matrix} \right ]
[3001][xy]=[3xy]
上面的矩阵是对称的,所以这个变换是一个对x,y轴的方向一个拉伸变换(每一个对角线上的元素将会对一个维度进行拉伸变换,当值>1时,是拉长,当值<1时时缩短),当矩阵不是对称的时候,假如说矩阵是下面的样子:
[
3
1
0
1
]
\left [ \begin{matrix} 3 & 1 \\ 0 & 1 \\ \end{matrix} \right ]
[3011]
它所描述的变换是下面的样子:
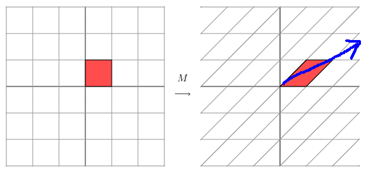
这其实是在平面上对一个轴进行的拉伸变换(如蓝色的箭头所示),在图中,蓝色的箭头是一个最主要的变化方向(变化方向可能有不止一个),如果我们想要描述好一个变换,那我们就描述好这个变换主要的变化方向就好了。反过头来看看之前特征值分解的式子,分解得到的Σ矩阵是一个对角阵,里面的特征值是由大到小排列的,这些特征值所对应的特征向量就是描述这个矩阵变化方向(从主要的变化到次要的变化排列)
当矩阵是高维的情况下,那么这个矩阵就是高维空间下的一个线性变换,这个线性变化可能没法通过图片来表示,但是可以想象,这个变换也同样有很多的变换方向,我们通过特征值分解得到的前N个特征向量,那么就对应了这个矩阵最主要的N个变化方向。我们利用这前N个变化方向,就可以近似这个矩阵(变换)。也就是之前说的:提取这个矩阵最重要的特征。总结一下,特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么,可以将每一个特征向量理解为一个线性的子空间,我们可以利用这些线性的子空间干很多的事情。不过,特征值分解也有很多的局限,比如说变换的矩阵必须是方阵。
以上的图片及内容来自LeftNotEasy的博客内容。感觉描述还是比较到位。
3.SVD分解
前面啰啰嗦嗦说了这么多基础,终于轮到咱们的主角:SVD登场了。
首先我们来看看奇异值的定义:对于一个矩阵
A
A
A,有:
(
A
T
A
)
ν
=
λ
ν
(A^TA) \nu = \lambda \nu
(ATA)ν=λν
那么向量
x
x
x就是
A
A
A的右奇异向量。并且:
奇异值:
σ
i
=
λ
i
\sigma_i = \sqrt{\lambda_i}
σi=λi
左奇异向量:
μ
i
=
1
σ
i
A
ν
i
\mu_i = \frac{1}{\sigma_i}A \nu_i
μi=σi1Aνi
咱们前面讲了那么多的特征值与特征值分解,而且特征值分解是一个提取矩阵特征很不错的方法。但是,特征值分解最大的问题是只能针对方阵,即 n ∗ n n*n n∗n的矩阵。而在实际应用场景中,大部分不是这种矩阵。举个最简单的例子,关系型数据库中的某一张表的数据存储结构就类似于一个二维矩阵,假设这个表有 m m m行,有 n n n个字段,那么这个表数据矩阵的规模就是 m ∗ n m*n m∗n。很明显,在绝大部分情况下, m m m与 n n n并不相等。如果对这个矩阵要进行特征提取,特征值分解的方法显然就行不通了。那么此时,就是SVD分解发挥威力的时候。
假设
A
A
A是一个
m
∗
n
m*n
m∗n阶矩阵,如此则存在一个分解使得
A
=
U
Σ
V
T
A=U \Sigma V^T
A=UΣVT
其中
U
U
U是
m
×
m
m×m
m×m阶酉矩阵;
Σ
\Sigma
Σ是
m
×
n
m×n
m×n阶非负实数对角矩阵;而
V
T
V^T
VT,即
V
V
V的共轭转置,是
n
×
n
n×n
n×n阶酉矩阵。这样的分解就称作
M
M
M的奇异值分解。
Σ
\Sigma
Σ对角线上的元素
Σ
i
\Sigma_i
Σi,
i
i
i即为
M
M
M的奇异值。而且一般来说,我们会将
Σ
\Sigma
Σ上的值按从大到小的顺序排列。
通过上面对SVD的简单描述,不难发现,SVD解决了特征值分解中只能针对方阵而没法对更一般矩阵进行分解的问题。所以在实际中,SVD的应用场景比特征值分解更为通用与广泛。
将将上面的SVD分解用一个图形象表示如下
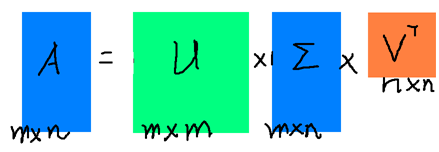
其中各矩阵的规模已经在上面描述过了。
截止到这里为止,很多同学会有疑问了:你这不吃饱了撑得。好好的一个矩阵 A A A,你这为毛要将他表示成三个矩阵。这三个矩阵的规模,一点也不比原来矩阵的规模小好么。而且还要做两次矩阵的乘法。要知道,矩阵乘法可是个复杂度为 O ( n 3 ) O(n^3) O(n3)的运算。
同志们别急,请接着往下看。
如果按照之前那种方式分解,肯定是没有任何好处的。矩阵规模大了,还要做乘法运算。关键是奇异值有个牛逼的性质:在大部分情况下,当我们把矩阵
Σ
\Sigma
Σ里的奇异值按从大到小的顺序呢排列以后,很容易就会发现,奇异值
σ
\sigma
σ减小的速度特别快。在很多时候,前10%甚至前1%的奇异值的和就占了全部奇异值和的99%以上。换句话说,大部分奇异值都很小,基本没什么卵用。。。既然这样,那我们就可以用前面r个奇异值来对这个矩阵做近似。于是,SVD也可以这么写:
A
m
×
n
≈
U
m
×
r
Σ
r
×
r
V
r
×
n
A_{m \times n} \approx U_{m \times r} \Sigma_{r \times r} V_{r \times n}
Am×n≈Um×rΣr×rVr×n
其中,
r
≪
m
r \ll m
r≪m,
r
≪
n
r \ll n
r≪n。如果用另外一幅图描述这个过程,如下图:
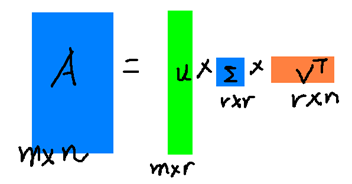
看了上面这幅图,同学们是不是就恍然大悟:原来的那个大矩阵 A A A,原来可以用右边的那三个小矩阵来表示。当然如果 r r r越大,跟原来的矩阵相似度就越高。如果 r = n r=n r=n,那得到的就是原来的矩阵 A A A。但是这样存储与计算的成本就越高。所以,实际在使用SVD的时候,需要我们根据不同的业务场景与需求还有资源情况,合理选择 r r r的大小。本质而言,就是在计算精度与空间时间成本之间做个折中。
4.SVD分解的应用
SVD在实际中应用非常广泛,每个应用场景再单写一篇文章都没有问题。这里我们先不做过多的展开,先举两个最重要的方面。为了方便后面的描述,先把SVD的近似表达式再拎出来
A
m
×
n
≈
U
m
×
r
Σ
r
×
r
V
r
×
n
A_{m \times n} \approx U_{m \times r} \Sigma_{r \times r} V_{r \times n}
Am×n≈Um×rΣr×rVr×n
1.降维
通过上面的式子很容易看出,原来矩阵 A A A的特征有 n n n维。而经过SVD分解之后,完全可以用前 r r r个非零奇异值对应的奇异向量表示矩阵 A A A的主要特征。这样,就天然起到了降维的作用。
2.压缩
还是看上面的式子,再结合第三部分的图,也很容易看出,经过SVD分解以后,要表示原来的大矩阵 A A A,我们只需要存 U U U, Σ \Sigma Σ, V V V三个较小的矩阵的即可。而这三个较小矩阵的规模,加起来也远远小于原有矩阵 A A A。这样,就天然起到了压缩的作用。
5.spark中SVD分解的计算方法
因为SVD是如此的基础与重要,所以在任何一个机器学习的库里,都实现了SVD的相关算法,spark里面自然也不例外。
spark里SVD是在MLlib包里的Dimensionality Reduction里(spark版本1.6,以下所有api与代码都是基于此版本)。文档里有SVD原理的简单描述。原理前面我们已经讲过,就不在重复了。重点看看里面的Performance:
We assume
n
n
n is smaller than
m
m
m.The singular values and the right singular vectors are derived from the eigenvalues and the eigenvectors of the Gramian matrix
A
T
A
A^TA
ATA.The matrix storing the left singular vectors
U
U
U,is computed via matrix multiplication as
U
=
A
(
V
S
−
1
)
U = A(VS^{-1})
U=A(VS−1), if requested by the user via the computeU parameter. The actual method to use is determined automatically based on the computational cost:
If n n n is small ( n n n<100) or k k k is large compared with n n n( k > n / 2 k>n/2 k>n/2),we compute the Gramian matrix first and then compute its top eigenvalues and eigenvectors locally on the driver. This requires a single pass with O ( n 2 ) O(n^2) O(n2) storage on each executor and on the driver, and O ( n 2 k ) O(n^2k) O(n2k) time on the driver.
给大家翻译一下:假设
n
<
m
n<m
n<m。奇异值与右奇异向量通过计算格莱姆矩阵
A
T
A
A^TA
ATA的特征值特征向量可以得知。而存储左奇异向量的矩阵
U
U
U,是通过矩阵乘法运算
U
=
A
(
V
S
−
1
)
U=A(VS{-1})
U=A(VS−1)计算得出的。实际计算中,是根据计算的复杂程度自动决定的:
1.如果
n
n
n很小(
n
<
100
n<100
n<100),或者
k
k
k与
n
n
n相比比较大(
k
>
n
/
2
k > n/2
k>n/2),那么先计算格莱姆矩阵
A
T
A
A^TA
ATA,再在spark的driver本地上计算其特征值与特征向量。这种方法需要在每个executor上
O
(
n
2
)
O(n^2)
O(n2)的存储空间,driver上
O
(
n
2
)
O(n^2)
O(n2)的存储空间,以及
O
(
n
2
k
)
O(n^2k)
O(n2k)的时间复杂度。
2.如果不是上面的第一种情况,那么先用分布式的方法计算
(
A
T
A
)
ν
(A^TA)\nu
(ATA)ν在把结果传到ARPACK上用于后续再每个driver节点上计算
A
T
A
A^TA
ATA的前几个特征值与特征向量。这种方法需要
O
(
k
)
O(k)
O(k)的网络传输,每个executor上
O
(
n
)
O(n)
O(n)的存储,以及driver上的
O
(
n
k
)
O(nk)
O(nk)的存储。
6.spark SVD实战
前头这么多内容讲的都是理论。显然纯理论不是我们的风格, talk is cheap,show me the code。理论说得再美好,是骡子是马,总得拉出来遛遛。只有亲自看这代码run起来,心里才能踏实。
关于spark的安装,环境配置等问题,同学们参考之前的博客
http://blog.csdn.net/bitcarmanlee/article/details/51967323 spark集群搭建
http://blog.csdn.net/bitcarmanlee/article/details/52048976 spark本地开发环境搭建
然后直接上源码
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.mllib.linalg.{Matrix, SingularValueDecomposition, Vectors, Vector}
import org.apache.spark.mllib.linalg.distributed.RowMatrix
/**
* Created by lei.wang on 16/7/29.
*/
object SvdTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("SVD").setMaster("spark://your host:7077").setJars(List("your .jar file"))
val sc = new SparkContext(conf)
val data = Array(
Vectors.sparse(5,Seq((1,1.0),(3,7.0))),
Vectors.dense(2.0,0.0,3.0,4.0,5.0),
Vectors.dense(4.0,0.0,0.0,6.0,7.0))
val dataRDD = sc.parallelize(data,2)
val mat:RowMatrix = new RowMatrix(dataRDD)
val svd: SingularValueDecomposition[RowMatrix,Matrix] = mat.computeSVD(5,computeU = true)
val U:RowMatrix = svd.U //U矩阵
val s:Vector = svd.s //奇异值
val V:Matrix = svd.V //V矩阵
println(s)
}
}
这里头我们通过调用API将 r r r的值设为5,最后的输出结果中,奇异值就有5个:
...
The singular values is:
[13.029275535600473,5.368578733451684,2.5330498218813755,6.323166049206486E-8,2.0226934557075942E-8]
...
从结果很容易看出来,第一个奇异值最大,而且占了总和的将近70%。最后两个奇异值则很小,基本可以忽略不计。















 612
612











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









