







1.聚集定义:聚集是对信息立方体中的数据按照指定的一个子集进行数据汇总,汇总的数据存在不同的独立的事实表。一个基本事实表可以设置多个聚集事实表。
2. 创建聚集:
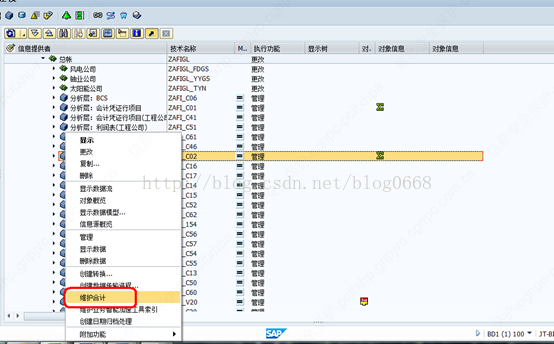
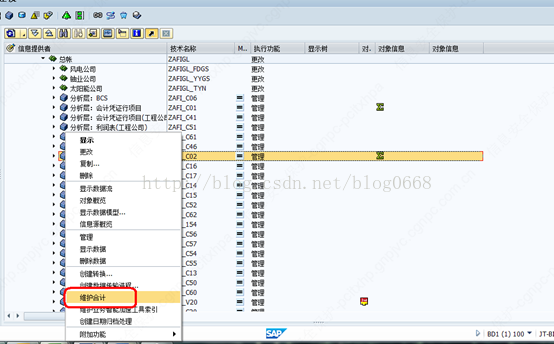
(1)右击需要维护聚集的CUBE,选择维护合计,如下图
(2)选择特性:从左边CUBE维度中选择所需要的特性或属性拖到右边,输入聚集的描述。可以设置特性/属性的类型(F或*),默认情况下是*
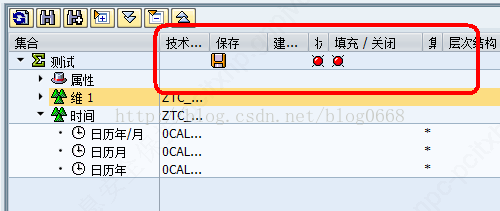
字段维护好之后的聚集状态如下,技术名称为空
(3)保存
点击保存按钮,保存后聚集状态如下
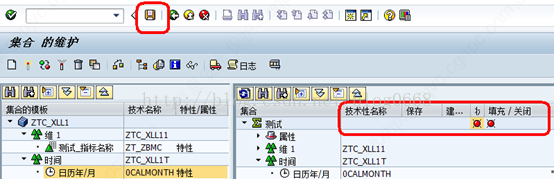
(4)激活/填充

上图第一个按钮:激活与填充,点击后,聚集的技术名称产生,同时“状态”由红色变成绿色。激活后,会出现如下选择框,选择填充方式(立即执行还是定义后台作业)。全部执行完毕后,“填充/关闭”状态由红色变成绿色,同时“记录”条目下显示聚集中数据条数。
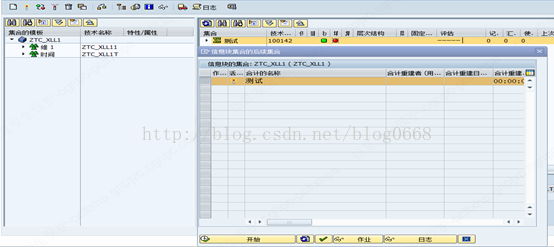
上图第二个按钮:查询的填充/关闭,关闭后query不能从聚集中读取数据。
上图第三个按钮:撤销激活,聚集的技术名称消失,同时“状态”和“填充/关闭”变成红色状态,聚集处于非活动状态。
3. 使用处理链初次填充数据到聚集
(1)聚集传输目标系统后是激活未填充状态。

(2)可以选择使用处理链进行聚集的初次填充

(3)处理链程序变式设置如下,下图中程序SAP_AGGREGATES_ACTIVATE_FILL是SAP标准程序,适用于所有聚集的初次激活和填充。此处需要新建一个程序变式Z05VAR002,直接点击程序变式后边的笔新建即可
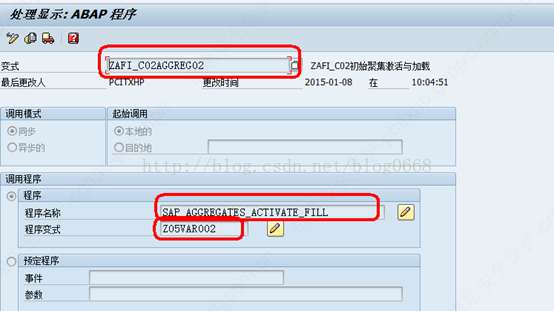
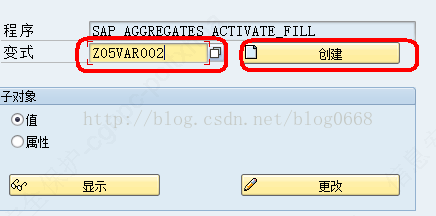
(4)程序变式创建
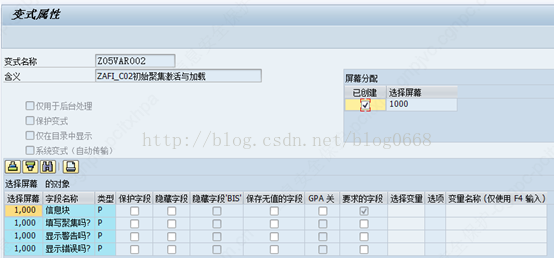
维护变式属性,维护好之后保存变式、处理链变式,最后激活处理链。
4. 非初次填充的数据加载
每次CUBE数据更新后,要将数据同步到聚集中,在处理链中的处理方式如下:
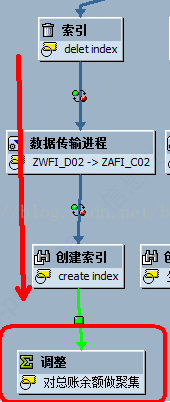
聚集加载数据变式维护如下:
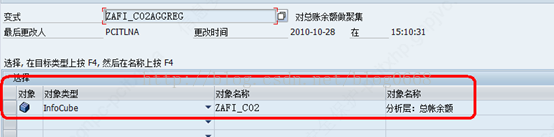
5. 通过T-CODE:RSRT检查query是否使用聚集的方法
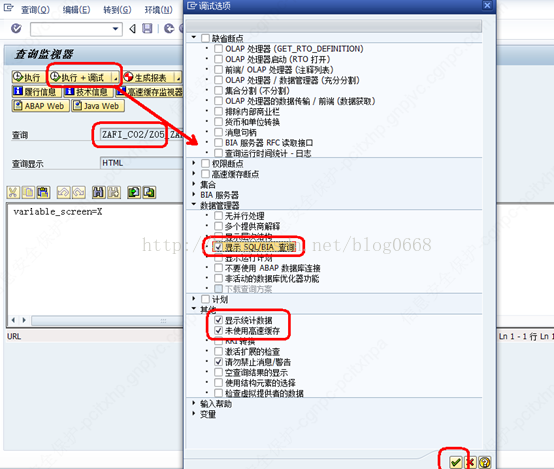
(1) 输入报表技术名称后,点击“执行+调试”按钮,勾选上图中的“显示SQL/BIA查询”,可以查看query运行的SQL语句,如下
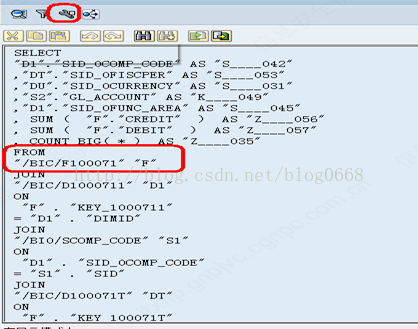
可以选择上面的扳手工具,对SQL语句进行测试
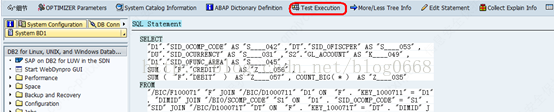
测试结果:
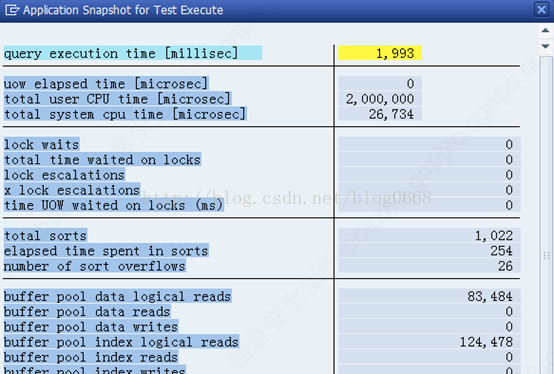
(1) 勾选“显示统计数据”可以查看报表各事件运行时间及是否使用了聚集
query运行时间统计:
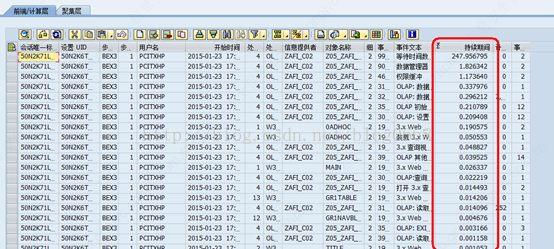
query聚集使用情况:

未使用聚集的query运行结果:















 3424
3424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









