






==========本文采用谷歌翻译,请参照中英文学习===========
在本例中,我们将详细讨论Apache Hadoop分布式文件系统(HDFS),其组件和体系结构。 HDFS是Apache Hadoop生态系统的核心组件之一。
1.介绍
Apache Hadoop提供了一个分布式文件系统和一个框架,用于使用MapReduce范例转换大型数据集。 HDFS旨在在商用硬件上运行时可靠地存储非常大的数据集。它是容错的,并且提供对存储的数据的高吞吐量访问。虽然HDFS的接口在Unix文件系统之后被图案化,但它放松了一些POSIX要求以提高其目标解决的应用程序的性能,并提供对存储在文件系统中的数据的流式访问。
2. HDFS设计
以下是HDFS的属性,使其与其他文件系统不同,并使HDFS能够可靠地处理大量的数据。
2.1系统故障
HDFS被设计为在一组商品硬件上工作。系统故障被认为是规范。由于存在大量HDFS依赖的组件,考虑到这些组件具有不平凡的故障概率也将导致一个组件或其他组件始终失败。因此HDFS旨在检测故障并执行自动恢复以提供所需的性能是HDFS的核心属性之一。
2.2可以处理大量的数据
HDFS设计用于依赖于大量数据的应用程序。此数据也可以是千兆字节,太字节或PB。因此,HDFS被调整为支持这种大型数据集,并扩展到大型系统集群以存储此数据,而不会影响数据吞吐量。
2.3一致性模型
HDFS被调整以满足需要写入数据一次或最多只读取几次并且读取数据更多的应用程序。由于这些应用程序被假设为依赖于“一次读取多次读取”模型,它简化了数据一致性问题,并允许HDFS提供高吞吐量数据访问。
2.4可移植性
HDFS旨在跨异构硬件和软件平台移植。这使得HDFS的适应变得非常容易,并且它成为依赖于分布式大数据集的应用的选择的平台。
3.HDFS节点
HDFS NameNode和DataNode有两个主要组件。
3.1 NameNode
HDFS遵循主从架构,其中NameNode是充当主节点的节点。一个HDFS集群只包含一个NameNode。 NameNode的主要功能是管理文件系统命名空间,并控制对存储在HDFS集群中的文件的客户端认证。它还处理存储在不同DataNode中的数据的映射。
3.2 DataNode
DataNode是名称表示在集群中存储实际数据的节点。集群中有多个DataNode,通常DataNodes的数量与集群中硬件节点的节点相同。 DataNode服务于来自客户端的读取和写入请求,并且还处理与块的创建,块的删除和复制相关的数据块的操作。
4.HDFS架构
在本节中,我们将了解Hadoop分布式文件系统(HDFS)的基本架构。
4.1 NameNode和DataNode的工作
HDFS是块结构文件系统,这意味着所有单独的文件被分成具有固定块大小的小数据块。然后,这些块将存储在DataNode中的机器集群中。 NameNode处理诸如打开,关闭和重命名文件或目录的功能。如上所述的NameNode还处理集群中的数据的映射,这意味着NameNode跟踪哪个数据块存储在哪个DataNode上以及如何处理该数据的复制。
4.2 HDFS命名空间
HDFS命名空间定义了如何在集群中存储和访问数据。 HDFS支持文件和目录的传统分层组织。它还支持几乎所有需要的函数来处理命名空间操作,如创建或删除文件或目录,将文件/目录从一个地方移动到另一个地方等。
正如我们在第3节讨论的,NameNode是维护HDFS文件系统命名空间的组件。在NameNode中维护对数据的任何操作,如创建或删除文件,移动文件或目录。
4.3数据复制
由于HDFS旨在将大量数据可靠,安全地存储在一组商品硬件上。由于这个硬件容易发生故障,HDFS需要以一种方式处理数据,以便在一个或多个系统发生硬件故障时可以轻松地检索数据。 HDFS使用数据复制作为提供容错功能的策略。使用HDFS的应用程序可以根据要求配置复制因子以及数据的块大小。
现在问题出现如何确定复制,如果所有副本都在集群中的单个机架中,并且整个机架发生故障,该怎么办。 HDFS尝试维护机架感知复制策略,这实际上需要大量的调整和体验。一个简单但非最佳的策略是将块的每个副本放置在独特的机架上,以便在整个机架故障的情况下。至少复制块在另一个机架中是安全的。
在大多数生产系统中,使用复制因子三。在这些情况下。 HDFS使用略有不同版本的独特机架策略。它通常将一个副本放置在本地机架中的节点上,另一个副本位于完全不同的远程机架上的节点上,第三个副本位于远程机架上的不同节点上。此策略通过在两个不同的机架上写入而不是三个机架来切换机架间传送时间,从而提高写入速度。这提供了在节点故障的情况下以及在机架故障的情况下的备份。此策略在不影响数据可靠性的情况下提高写入性能。
4.4故障
Hadoop分布式文件系统(HDFS)的主要目标和目标是即使在出现故障时也能可靠地访问数据。由于故障比商业硬件集群更常见,而HDFS需要一个策略来处理故障。三种常见类型的故障是:
- NameNode故障
- DataNode故障
- 网络分区
集群中的每个DataNode都向NameNode发送周期性消息,此消息称为心跳。这个心跳向NameNode传达了特定的DataNode工作正常,并且是活的。现在在DataNode失败的情况下,从DataNode到NameNode不会有心跳。类似地,在网络分区的情况下,DataNode的子集可以松开其到NameNode的连接并且停止发送心跳。一旦NameNode停止从特定的DataNode或一组DataNode中获取心跳,就声明这些节点已经死了,然后开始检查损坏的过程,包括检查死亡DataNode中的所有块是否仍然有足够的副本,如果不是,则它启动进程以创建重复副本,以获得在应用程序中配置的最小数量的副本。
NameNode故障更严重,因为NameNode系统是完整HDFS集群的唯一单点故障。如果NameNode系统失败,整个集群是无用的,需要手动干预,需要设置另一个NameNode。
4.5数据可访问性
现在为了允许应用程序访问存储在HDFS集群中的数据,它提供了一个Java API供应用程序使用。如果需要使用C语言,则还通过Java API提供C语言包装器。
除了Java和C API,HDFS还提供了一个选项,通过Web端口通过Web浏览器访问HDFS数据,可以在HDFS的设置中配置。
第三个辅助选项是使用文件系统shell。 HDFS还提供了一个名为FS Shell的命令行界面,让用户与HDFS中的数据进行交互。此命令行界面的语法类似于Linux shell命令。例如:
#To make a new directory
hadoop fs -mkdir /user1/project1
#List the content of the file
hadoop fs -ls /user1/project1
#Upload a file from local system to HDFS
hadoop fs -put Desktop/textfile.txt /user1/project1有关FS Shell命令的更多示例和说明,您可以查看文章Apache Hadoop FS命令示例
5.配置HDFS
HDFS的配置非常简单,设置HDFS集群不需要太多时间。 HDFS的所有配置文件默认都包含在Hadoop包中,可以直接配置。
注意:我们假设Hadoop软件包已经下载,解压缩并放置在所需的目录中。在本文中,我们将仅讨论HDFS所需的配置。有关如何设置Hadoop和Hadoop集群的详细文章。遵循以下教程:
5.1配置HDFS
HDFS使用一组默认存在于Hadoop配置目录中的XML文件进行配置。此配置目录存在于Hadoop文件夹的根目录中,并命名为conf。
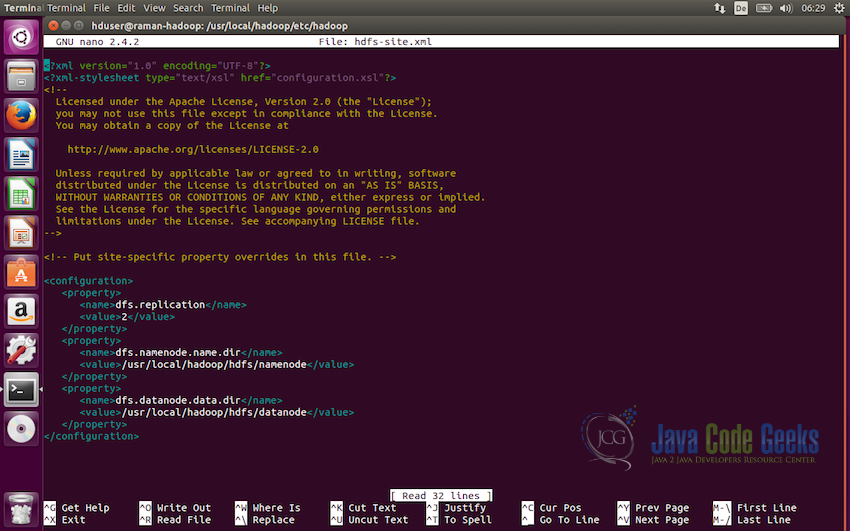
首先,我们将修改conf / hadoop-sites.xml文件,我们需要在这个文件中设置三个属性,即fs.default.name,dfs.data.dir,dfs.name.dir
要修改文件,请在编辑器中打开该文件,并添加以下代码行:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/hdfs/datanode</value>
</property>
</configuration>我们在这里设置的第一个配置是dfs.replication,它设置分布式文件系统要使用的复制因子。 在这种情况下,我们将其设置为两个。
下一个配置是定义NameNode路径,即dfs.namenode.name.dir,这里的值需要是存储namenode信息的目录。
我们需要设置的第三个和最后一个配置是定义DataNode的路径,即dfs.datanode.data.dir,它将定义到存储datanode信息的目录的路径。
注意:确保将创建namenode和datanode目录并且将存储数据的目录由将运行Hadoop的用户拥有。 使用户在目录中具有读写权限。
5.2格式化NameNode
现在下一步是格式化我们刚刚配置的NameNode。 以下命令用于格式化NameNode:
hdfs namenode -format此命令应该在控制台输出上没有任何错误的情况下执行。 如果它没有任何错误执行,我们很好在我们的Ubuntu系统上启动Apache Hadoop实例。
5.3启动HDFS
现在我们准备好启动Hadoop文件系统。 要启动HDFS,请使用以下命令运行start-dfs.sh文件:
/usr/local/hadoop/sbin/start-dfs.sh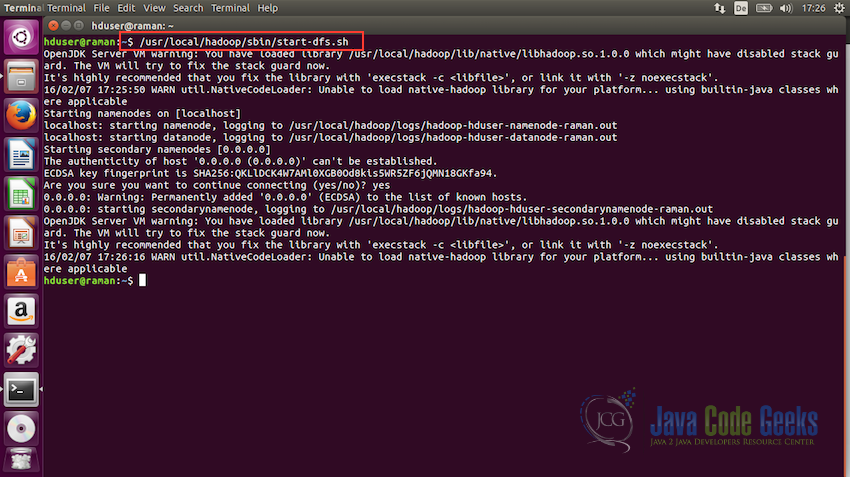
一旦这个脚本执行没有任何错误,HDFS将启动并运行。
6.使用Shell与HDFS交互
现在我们将看到一些需要使用shell与HDFS交互的命令。 在本节中,我们将只看到基本的介绍命令,并将只使用命令行界面。 与集群通信的命令存在于脚本bin / hadoop中。 此脚本使用Java虚拟机(JVM)加载Hadoop软件包,然后执行user命令。
6.1创建目录
用法:
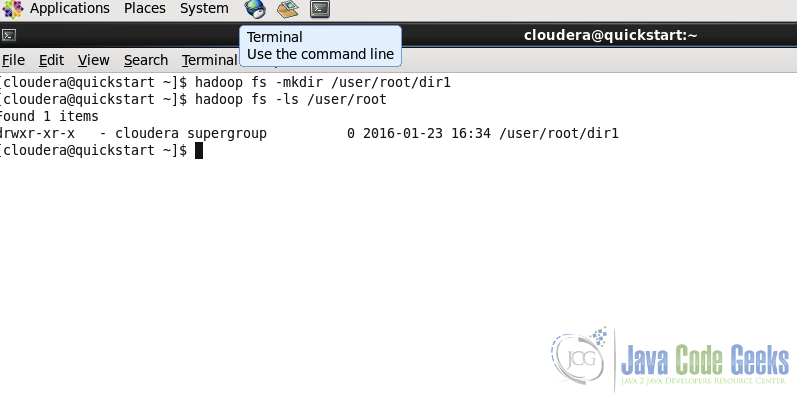
hadoop fs -mkdir 示例:
hadoop fs -mkdir /user/root/dir1第二行中的命令用于列出特定路径的内容。 我们将在下一小节中看到此命令。 我们可以在截图中看到dir1被创建
6.2列出目录的内容
用法:
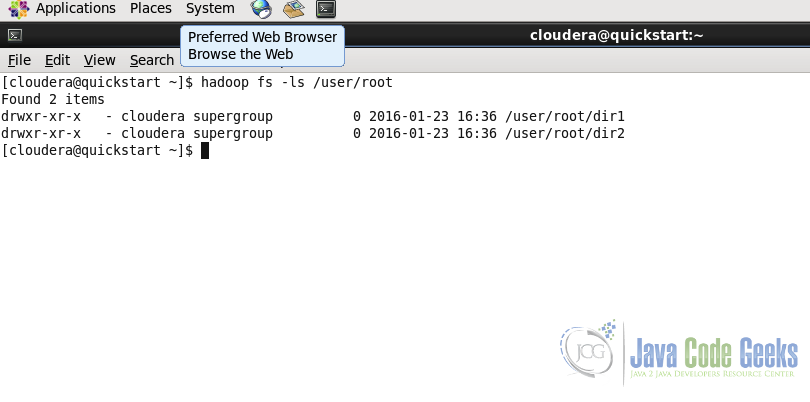
hadoop fs -ls 示例:
hadoop fs -ls /user/root/
6.3在HDFS中上传文件
命令用于将一个或多个文件从本地系统复制到Hadoop文件系统。
用法:
hadoop fs -put ...
hadoop fs -put Desktop/testfile.txt /user/root/dir1/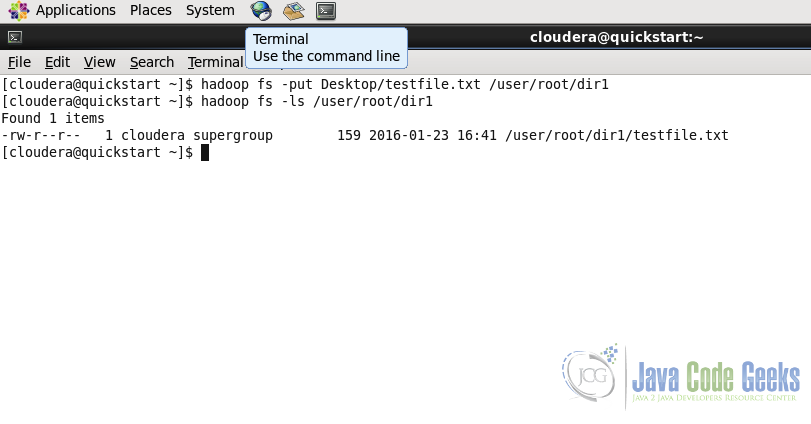
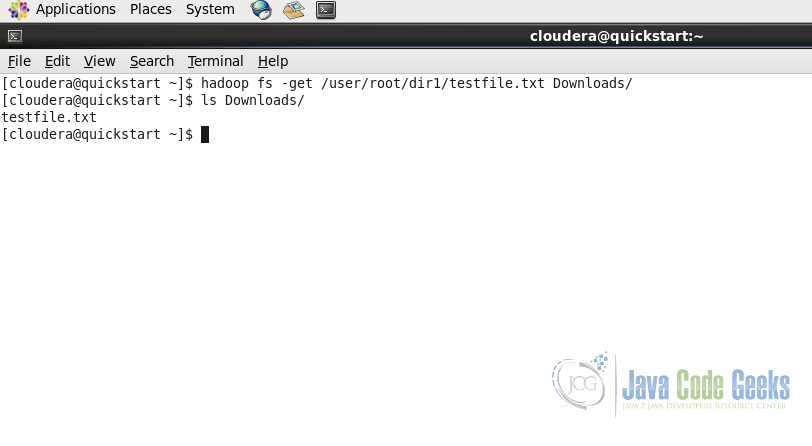
6.4从HDFS下载文件
将文件从HDFS下载到本地文件系统。
用法:
hadoop fs -get 示例:
hadoop fs -get /user/root/dir1/testfile.txt Downloads/与put命令一样,get命令从Hadoop文件系统获取或下载文件到Downloads文件夹中的本地文件系统。
注意:有关文件系统命令和其他重要命令的详细信息,请参阅Apache Hadoop FS命令示例文章,或者您可以在Apache Hadoop网站上的文档中检查shell命令的完整文档:文件系统命令 和HDFS命令指南
7.使用MapReduce与HDFS交互
正如我们讨论的,HDFS是Hadoop和MapReduce的基本组件。 Hadoop MapReduce作业从HDFS获取数据,并将最终结果数据存储在HDFS中。
Hadoop还提供了一个Java API,通过它我们可以在Java应用程序中执行HDFS功能。 在本节中,我们将看到如何在java代码中使用Java API。
package com.javacodegeeks.examples.HDFSJavaApi;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.Path;
/**
* Example application to show how the HDFS file system Java API works
*
* @Author Raman Jhajj
*/
public class App
{
public static final String filename ="dummy.txt";
public static final String message = "This is the dummy text for test the write to file operation of HDFS";
public static void main( String[] args ) throws IOException
{
//Get the file system instance
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(configuration);
Path filenamePath = new Path(filename);
try {
if(fs.exists(filenamePath)) {
//Delete Example
fs.delete(filenamePath, true);
}
//Write example
FSDataOutputStream out = fs.create(filenamePath);
out.writeUTF(message);
out.close();
//Read example
FSDataInputStream in = fs.open(filenamePath);
String messageIn = in.readUTF();
System.out.println(messageIn);
in.close();
//Rename the file
if(fs.exists(filenamePath)) {
Path renameFilenamePath = new Path("renamed_" + filename);
fs.rename(filenamePath, renameFilenamePath);
}
} catch(IOException ex) {
System.out.println("Error: " + ex.getMessage());
}
}
}
上面的代码创建一个名为dummy.txt的文件,将虚拟消息写入此文件。
- 行号24-25用Configuration对象创建一个抽象的FileSystem对象。在这种情况下配置对象使用默认参数,因为我们没有定义任何参数。
- 行号 30-33检查文件是否已经存在于HDFS中,如果它存在,它尝试删除该文件。本示例向我们介绍了文件系统中可用的两种方法exists()和delete()
- 行号35-38将文件写入提供的路径上的HDFS,然后在文件中写入虚拟消息。这将介绍另一种如何在HDFS中写入文件的方法。
- 行号 40-44读取我们刚才在前面代码行中写的文件,并将该文件的内容写在控制台上。这个代码示例不提供很多有用的工作,它只是设计来获得基本的了解如何读取和写入文件在HDFS使用Java API的工作原理。
- 行号 47-50检查文件是否存在于HDFS中,如果存在,将文件从dummy.txt重命名为renamed_dummy.txt
要进一步阅读,您可以检查HDFS API JavaDoc on HDFS API JavaDoc
8.结论
这使我们得出这篇文章的结论。我们从设计开始讨论了Hadoop分布式文件系统(HDFS)的基础知识,然后了解了HDFS架构。然后我们看到了如何配置和启动HDFS节点,最后我们讨论了如何使用shell命令行和HDFS Java API与运行的HDFS集群交互。我希望这给出了关于HDFS及其构建块的基本解释。
9.下载代码
在此示例中,下载包含用于了解HDFS Java API的代码的Eclipse项目。
下载
您可以在这里下载此示例的完整源代码:HDFSJavaApi














 163
163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









