







我决定翻译《计算机体系结构--量化研究方法》第四版附录F。原因在于向量处理器现在变得异常重要。可以说向量处理器是 GPU 的先驱。要从体系结构上理解 GPU,没有道理不先理解历史上的向量处理器。很多向量处理器里面用到的技术,在现在最先进的微处理器中又奇迹般地得到了重生。比如 Cray-1 里面的 T Register File 和 B Register File,和 Stream Processor 中的 Stream Register File (SRF)如出一辙。而现代面向通用计算的 GPU 中的Shared Memory 和 S Register File 以及 A Register File的设计初衷也有异曲同工之妙。当然另一个原因是我没有看到有关量化附录的翻译。
这个附录的作者是
Krste Asanović。他本人的Ph.D. Thesis
就是一个向量处理器的设计。据说随着 David Patterson 慢慢地不管事,现在他已经成为了了 ParLab 的实际领袖。我完全是抱着学习这个附录的心态来翻译的,任何质疑都可以在下面留言。
最后要说的一点,体系结构里最让人头疼的事莫过于五花八门的术语了,而如果要在中英文之间切换这些术语则更恶化这个现象。我的策略是两个。第一,如果有非常好非常成熟非常通用的中文翻译,我用中文--毕竟我是在翻译。但是即使这样我也会用括号表明英文术语。第二,有些术语本身有很大争议。比如 issue 和 dispatch,X86 和MIPS 对他们的使用完全相反。我于是准备采用另一个页面,来解释那些令人困惑到发指的术语,以免读者完全理解错误原文应有之义。另外,原文之中有一些我认为讲得不是特别清楚或者难以理解的地方我都以注释的形式给出我自己的理解。
---------------大家好,我是分割线---------------
我当然没有在发明向量处理器。现如今就我所知就已经有三种向量处理器存在了。他们是 IIIliac-IV, (CDC)Star,和 T1(ASC)。这三者都是向量处理器的先驱…作为先驱的一个问题是你总是要犯错误,而我绝对,绝对不想成为先驱。所以成为后来者的好处是你总是可以看到前人犯了什么错误。
Seymour Cray
1. 何出向量处理器?
在第 2 、 3 章我们看到了如何通过每个时钟周期发射多条指令和利用更深的执行单元流水线来开发指令级并行( ILP )以显著提高性能。(这个附录假定你已经完整阅读了第 2 、 3 章和附录 G 。另外,对向量处理器的内存系统的讨论需要你阅读附录 C 和第 5 章。)不幸的是,我们看到在挖掘更大程度的 ILP 的时候遇到了各种各样的困难。
随着我们增加指令发射的宽度和流水线的级数,我们同时也需要更多的不相关指令以保持流水线忙碌。这意味着可以同时 in flight 的指令数目的增长。对于一个动态调度的处理器而言,这意味着硬件资源比如指令窗口( instruction window ), ROB ,重命名寄存器
( renaming register file )也要相应增长以保持足够的能力去维护所有 in flight 的指令的信息。更糟的是每一个硬件单元的端口都要随着发射宽度的增长而增长。跟踪所有 in flight 的指令之间依赖性( dependency )的逻辑随着指令的数目以 2 次方的关系增长 。即使对于一个把更多的调度工作转移到了编译器上的静态调度的 VLIW 处理器而言,它仍然需要更多的寄存器,更多的寄存器端口,更多的 hazard interlock 逻辑(我们假定由硬件在指令发射的时候检测是否需要 interlock )来支持更多的 in flight 指令。这同样导致了电路规模和复杂度的 2 次方 增长[1]。如此快速的电路复杂度的增长使得设计一个能够控制大量 in flight 指令的处理器困难重重,而且这反过来实际上也限制了发射宽度和流水线深度。
向量处理器早在 ILP 处理器之前就已经成功商业化了。它采用了一种不同的策略来控制多个深度流水的功能部件。向量处理器提供了高层的对于向量 -- 线性数组 -- 的操作。一个典型的向量操作是两个 64 个浮点元素的向量相加得到一个新的 64 个元素的向量。这条向量指令等同于一整个循环,每一次迭代计算出一个元素的结果,更新循环变量,然后跳转回循环头部继续执行。
向量处理器有以下几个重要的特性使得它能够解决大多数上面提到的问题:
- 一条向量指令能够做很多事情--它等价于一整个循环。每条指令代表了数十上百条的操作,所以为了保持多个深度流水化的功能单元忙碌而需要的 instruction fetch 和 instruction decode 的带宽急剧减少了。
- 通过使用一条向量指令,编译器或者程序员显式地指出了在一个向量之中的各个元素之间的计算互相独立,所以硬件不需要检测一个向量内部的 data hazard。可以使用一组并行的功能单元或者一个非常深度流水的功能单元或者任何以上两种方式的组合来计算向量中的各个元素。
- 硬件只需要检测两条向量指令之间的 data hazard,而不是每个向量之中的元素之间的 hazard。这意味着所需的依赖检测逻辑的规模其实和标量处理器所需的大致相同,但是现在更多的(对于向量元素)操作可以同时 in flight。
- 向量指令的访存有固定可知的模式。如果一个向量的元素是相邻的,那么从一组高度 interleaved 的 memory bank 中取那个向量会效果非常好。相对于访问 cache 而言更高的访问主存的延迟被均摊了,因为一个向量访存操作是为向量中的所有元素发起的,而不只是一个元素。
- 因为一整个循环都被一条向量指令代替了,而这条向量指令的行为是可预期的,所以通常由循环分支而引起的 control hazard 现在不存在了。
因为这些原因,向量操作对于同样数目的数据进行操作的时候比相应的一系列标量指令要快得多,所以设计者们如果发现他们的应用程序会经常进行向量操作的话会在设计中包含有向量单元。
向量处理器尤其对于大规模的科学工程计算特别有效,包括汽车碰撞模拟和天气预报。这些应用程序通常需要一台超级计算机跑上几打个小时来处理 Gigabyte 级别的数据。高速的标量处理器依赖于 cache 来减少访问主存的延迟,但是大规模长时间运行的科学计算程序通常有很大规模的工作集,并且通常局部性非常低,这导致 memory hierarchy 的性能非常糟糕。所以标量处理器会提供旁路 cache 的机制如果软件发现访存的局部性很差。但是使得主存饱和需要硬件跟踪数百上千条的 in flight 的标量访存操作,而这在标量处理器 ISA 中已被证实开销是非常大的。相反,向量 ISA 可以只使用一条向量指令就可以发起对于一整个向量中元素的访存操作,所以非常简单的逻辑就可以提供很高的带宽[2]。
当这个附录上一次在 2001 年写的时候,诡异的向量超级计算机已经慢慢地从超级计算机领域中淡出了,取而代之的是超标量处理器。但是在 2002 年,日本造出了当时世界上最快的超级计算机, the Earth Simulator 。它是为创造一个“虚拟星球”来分析和预测世界环境和气候变化而设计的。它比之前最快的超级计算机还要快 5 倍,并且比身后的 12 个超级计算机加起来还要快。这在高性能计算领域引起了一阵骚乱,特别是在美国。美国人被如此之快地就丢失如此具有战略意义的高性能计算阵地而感到震惊。 The Earth Simulator 比那些与之竞争的机器有更少的处理器,但是每一个节点都是一个单芯片的向量微处理器。它对于很多具有重要意义的超级计算代码都有非常高的性能 -- 原因就像之前提到的。 The Earth Simulator 以及 Cray 发布的新一代向量处理器的影响力导致了对于向量处理器的重新关注和重视。
---------------大家好,我是分割线---------------
[1] 为什么是 2 次方请看原书第三章第二小节。简单来讲,这就是一个排列组合的问题。
[2] 这段话的意思简单来讲就是通常高级的标量处理器里面的内存系统是非常复杂的,需要 MSHR 这样的结构以及很复杂的访存调度算法甚至编译器的优化来提高访存效率,充分利用内存接口本就不高的带宽。而对于向量机而言,由于访问模式规则,非常简单的内存系统的设计配搭上一条向量指令就足以使得内存带宽饱和。
2. 向量处理器基本体系结构
一个向量处理器通常由一个普通的流水化的标量单元加上一个向量单元组成。在这个向量单元里的所有功能部件都有几个时钟周期的延迟。这使得能够使用较短的时钟周期,并且与复杂的需要深度流水化来避免数据 hazard 的向量运算兼容。大多数的向量处理器所允许的向量运算包括浮点运算,整型运算或者逻辑运算。这里我们重点关注浮点运算。标量单元基本上和我们在第二章和第三章里面讨论过的高级的流水线化的 CPU 里面的没区别。并且实际上商用的向量处理器里面都同时包含了乱序的标量单元(NEC SX/5)和 VLIW 的标量单元
(Fujitsu VPP5000)。
向量处理器主要有两种类型:向量-寄存器(vector-register)处理器和内存-内存(memory-memory)处理器。在 vector-register 类的处理器中,所有的向量操作--除了 load 和 store--都是在向量寄存器(vector register)里面进行的。这类的处理器就和我们在标量处理器里面谈过的 load-store 体系结构相对应。在80 年代后期发布的几乎所有向量计算机都采用了这个结构,这其中包括 Cray Research 的处理器
(Cray-1,Cray-2,X-MP,YMP,C90,T90,SV1 和 X1),日本的超级计算机(从NEC SX/2 到 SX/8,Fujitsu VP200 到 VPP5000,以及Hitachi S820 和 S-8300)以及迷你超级计算机(从 Convex C-1 到 C-4)。在 memory-memory 类的向量处理器中,所有的向量运算都是从内存到内存的。第一个向量处理器就是这种类型,CDC 系列的亦是如此。从现在开始让我们把注意力放在 vector-register 类的处理器上我们会。在这个附录的最后(第10小节),我们会简单地讨论一下为什么 memory-memory 类的处理器没有 vector-register 类的处理器那么成功。
我们讨论的 vector-register 类的处理器主要由图 F.1 中的部件组成。这个基本上类似 Cray-1 的处理器是我们整章的讨论基础。我们把它叫 VMIPS--它的标量单元就是 MIPS,而向量单元则是 MIPS 的扩展。本小节余下部分将讨论 VMIPS 和其他处理器有何相关。

图F.1 VMIPS 的基本结构。这个处理器有一个类似 MIPS 的标量单元。另外还有8 个包含 64 个元素的向量寄存器,并且所有的功能部件都是向量运算单元。定义了包括算术运算和访存在内的特别的向量指令。在这张图里面我们包括了逻辑运算和整型运算的部件,这些部件在标准的向量处理器里面其实也是存在的。但是除了后面的练习题之外我们不会讨论这两个部件。标量寄存器及和向量寄存器都有大量的读写端口以支持同时多个向量操作。这些端口通过一组crossbar (图中灰色所示)和向量功能部件的输入输出相连。在第四小节中,我们会再加上 chaining 的部分,它需要更强的互联能力。
VMIPS的主要组成部分是:
向量寄存器(Vector registers):每个向量寄存器都是一个定长的bank,能够容纳一个向量。VMIPS有 8 个向量寄存器,每个寄存器能够容纳 64 个向量元素。每个寄存器至少有两个读端口和一个写端口。这能够保证需要不同向量寄存器的多个向量运算能够互相同步进行[1](我们并不考虑由于寄存器端口短缺而引起的问题。在实际的机器中,这会导致 structural hazard)。总共 16 个读端口和 8 个写端口通过一对 crossbar 和功能部件的输入输出相连(我们在这里简化了对于 vector-register 类的处理器的寄存器文件的描述。真实的机器里会利用在一条向量指令里规则的访问模式来简化寄存器文件的电路设计[Asanovic 1998]。比如 Cray-1 就能够设计使得每个寄存器只需要一个端口)。
向量功能部件(Vector functional units):每个部件都是完全流水化的,并且每一个新的时钟周期可以开始对于一个新向量元素的操作。另外还需要一个控制部件来检测 hazard,包括功能部件的冲突(structural hazards)和寄存器访问的冲突(data hazards)[2]。如图F.1 所示,VMIPS 有五个功能部件。为了简化讨论,我们将只讨论浮点运算单元。取决于不同的设计,标量运算可能使用向量功能部件,或者有单独的一组功能部件。我们这里假设功能部件是共享的,并且,再一次忽略任何可能的冲突。
向量访存单元(Vector load-store unit):这是一个能够 load 和 store一个向量到主存的单元。VMIPS 中的 load 和 store 操作是完全流水化的,因此在一开始的延迟之后,寄存器和内存之间的带宽可以达到每一个时钟周期一个 word。这个单元通常也处理标量访存工作。
一组标量寄存器(scalar registers):标量寄存器能为标量功能部件提供输入数据[3],并且也能为内存访问单元提供地址。这些其实就是MIPS中常见的 32 个通用寄存器和 32 个浮点寄存器。标量数据从标量寄存器中读出,然后锁存到向量单元的一个输入之中。

图F.2 几个 vector-register 类型的体系结构的特征。如果某个机器是多处理器(multiprocessor),上面只列出一个处理器的数据。有几个机器采用了不同频率的标量和向量单元,上面的频率数据是向量单元的。Fujitsu的机器的向量寄存器是可配置的:8K 个 64-bit 的 entry [4]是可以变化的(比如在 VP200 里面,可以从 8 个寄存器,每个包含 1K 和元素到 256 个寄存器,每个包含 32 个元素)。NEC 的机器有 8 个前段的向量寄存器和算术运算单元相连,还有 32-64 个后端寄存器连接内存和前段寄存器。Add 流水线进行加法和减法操作。Hitachi S810/820 里面的 multiply/divide-add 单元先进行一个浮点的乘法或者除法运算紧跟着一个加法或者减法操作(multiply-add 单元先进行一个浮点的乘法运算紧跟着一个加法或者减法操作)。注意大多数的处理器使用向量浮点单元来进行向量整型运算,还有一些处理器使用相同的功能单元来进行向量和标量操作。每个 vector load-store 单元能够执行一个独立的,可以相互重叠的 load 或者 store操作。Lane 的数目,就像第四小节中提到的,是每个功能部件中并行流水线的数目。比如,NEC SX/5 的乘法部件可以在一个时钟周期之中完成 16 个乘法运算[5]。有些机器可以把一个 64-bit 的 lane 分离成 2 个 32-bit 的 lane以提高那些对精度要求不高的程序的性能。Cray SV1 和 Cray X1 可以把有 2 个lane 的 4 个 CPU组合成好像一个有 8 个 lane 的 CPU。Cray把它叫做 Multi-Streaming Processor(MSP)。
在 VMIPS 中,向量指令采用和 MIPS 指令相同的名字,只是多了加了“V”。这样的话,ADDV.D 就是一个把两个双精度的向量相加的操作。向量指令的输入或者是一对向量寄存器(ADDV.D)或者是一个向量寄存器和一个标量及存取(ADDVS.D)。后者的标量输入被所有的向量元素视为输入--ADDVS.D 会把标量寄存器的内容加到向量寄存器的每一个元素上。标量值在指令发射时被拷贝多份到功能部件。大多数的向量操作都有一个向量目标寄存器(vector destination register),也有一些操作的结果是被存储到标量寄存器里的。LV 和 SV 代表向量 load 和向量 store操作。他们 load 或者 store 一整个双精度的向量。一个操作数是一个要被 load 或者 store 的向量寄存器里,另一个是一个 MIPS 的通用寄存器,保存该向量在内存中的起始地址。图 F.3 列出了 VMIPS 的向量指令。除了向量寄存器之外,我们还需要两个特殊用途的寄存器:向量长度寄存器(vector-length register)和向量掩码寄存器(vector-mask register)。我们分别在第三和第四小节会谈到这两个寄存器和他们的用途。
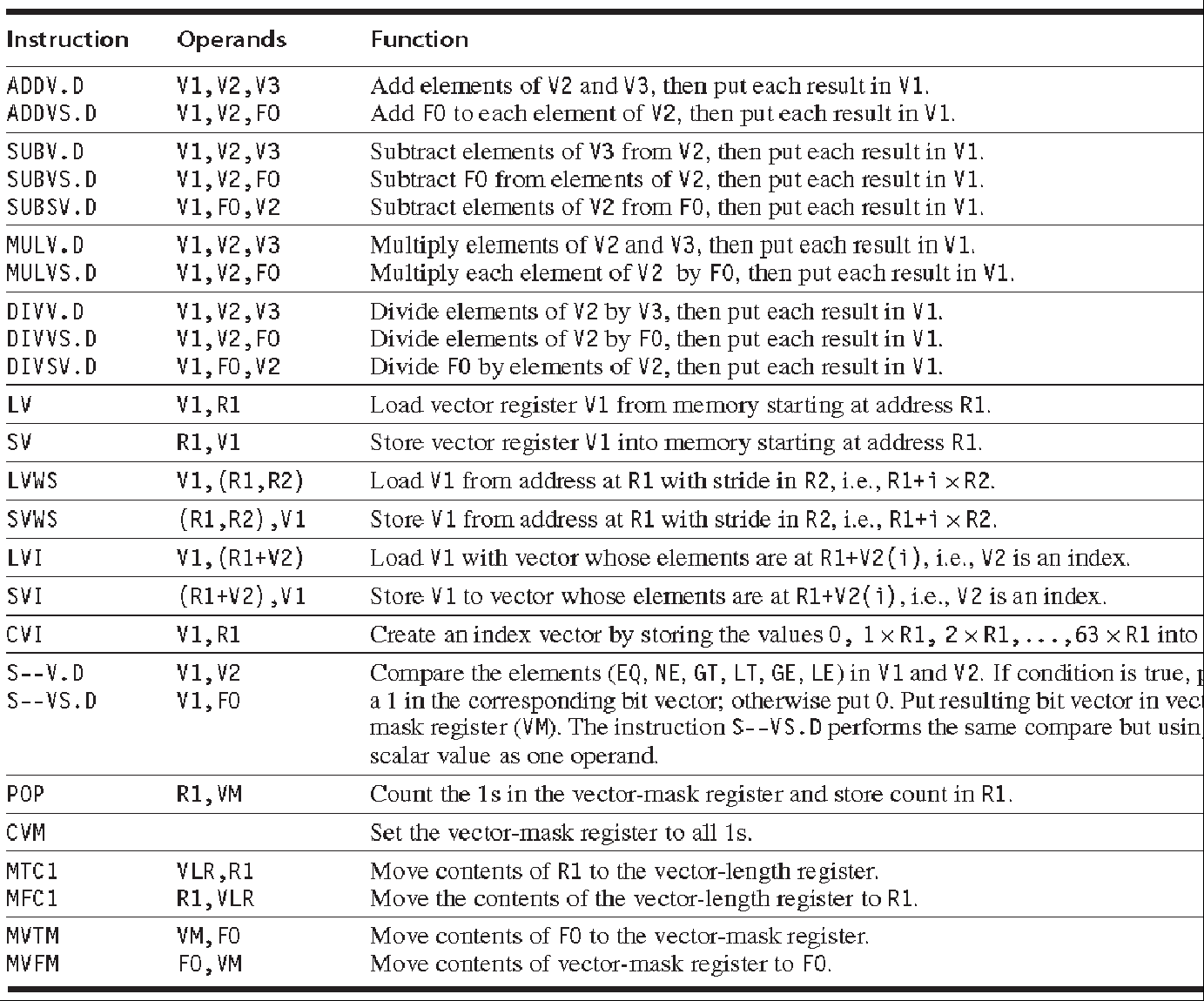
图F.3 VMIPS 的向量指令。这里只列出了双精度的指令。除了向量寄存器之外,还有两个特殊寄存器,VLR(在第三节谈到)和 VM(在第四节谈到)。假定这些特殊寄存器都在 MIPS 的 coprocessor 1 中,也即和 FPU 寄存器在同一空间中。有 stride 的操作会在第三小节提到。新建索引和索引化的访存操作会在第四节里提到。
---------------大家好,我是分割线---------------
[1] 在后面我们会看到 convoy 这个概念。一个 convoy 表示一组可以同时执行的向量指令。他们可能访问不同的寄存器,我们必须提供足够多的端口以保证不会发生端口短缺。
[2] 这里的寄存器访问的冲突不是指端口短缺引起的冲突。而是由于对于数据依赖不正当的处理而引起的对寄存器错误访问。
[3] 想一下什么情况下向量运算需要标量数据?什么情况下向量运算的结果需要写到标量寄存器里面?
[4] 这里的 entry 指的是一个向量寄存器里面的一个元素。64-bit 是指每个元素是64-bit 长。
[5] 更精确地说,是完成16个来自不同向量的操作。
2.1 向量处理器如何工作:一个实例
要理解向量处理器的工作流程,最好的办法是研究一个向量循环(vector loop)如何在 VMIPS 上工作。让我们使用以下这个典型的向量问题,这个附录的其余部分也会使用它:
Y = a × X + Y
X 和 Y 都是向量,一开始就在内存之中;a 是一个标量。这就是所谓的 SAXPY 或者 DAXPY 循环。(SAXPY 表示
single-precision a×X plus Y;DAXPY 表示double-precision a×X plus Y。)Linpack 是由一组线性代数例程组成,其中进行高斯消元操作的例程被称为 Linpack Benckmark。这里的DAXPY 例程仅仅代表 Linpack Benchmark 的一小部分,但是其操作占了整个 benchmark 运行时间的绝大部分。
从现在开始,让我们假定向量寄存器的元素的个数,或者说其长度(64)等于我们所关心的向量操作的长度。(我们之后会放宽对此的限制)
————————————————————
例题:
给出 MIPS 和 VMIPS 上 DAXPY 循环的代码。假定 X 和 Y 的起始地址分别在 Rx 和 Ry。
解答 :以下是 MIPS 代码:
L.D
F0,a
;load scalar a
DADDIU R4,Rx,#512 ;last address to load
Loop: L.D F2,0(Rx) ;load X(i)
MUL.D F2,F2,F0 ;a × X(i)
L.D F4,0(Ry) ;load Y(i)
ADD.D F4,F4,F2 ;a × X(i) + Y(i)
S.D 0(Ry),F4 ;store into Y(i)
DADDIU Rx,Rx,#8 ;increment index to X
DADDIU Ry,Ry,#8 ;increment index to Y
DSUBU R20,R4,Rx ;compute bound
BNEZ R20,Loop ;check if done
以下是 VMIPS 的代码:
L.D F0,a ;load scalar a
LV V1,Rx ;load vector X
MULVS.D V2,V1,F0 ;vector-scalar multiply
LV V3,Ry ;load vector Y
ADDV.D V4,V2,V3 ;add
SV Ry,V4 ;store the result
这两个版本代码之间的比较颇有意思。最显著的区别是,向量处理器极大地减少了动态指令[1]的带宽需求,只需要执行 6 条指令--相对应于 MIPS 的600 条。这是因为向量指令可以同时操作于 64 个元素,并且那些几乎占了一个循环中一半代码的循环冗余指令[2]现在都不存在了。
————————————————————
另一个重要的区别是流水线
互锁(interlock)的频率。在直观的 MIPS 代码中,每个 ADD.D 都要等待 MUL.D,每个 S.D 都要等待 ADD.D。在向量处理器中,每个向量指令只在第一个元素的操作上停顿(stall),之后的元素可以顺利地流过流水线。因此,流水线停顿只在每个向量操作发生一次,而不是每个向量的元素都发生。在这个例子中,MIPS 上流水线停顿的频率大约是 VMIPS 上的64倍。流水线停顿在 MIPS 上可以使用软件流水(software pipeling)或者循环展开(loop unrolling)的技巧来避免(参照附录 G)。然而,巨大的指令带宽的需求仍然存在。
2.2 向量处理器执行时间
一串向量操作的执行时间主要取决于三个因素:每个向量操作的长度,向量操作之间的 structural hazard,以及 data dependency。给定了向量的长度和引发率(initiation rate)即一个向量单元消耗新的操作数产生新结果的速率,我们可以计算出单个向量指令的执行时间。所有的现代超级计算机都拥有由多个并行道(或者叫 lane)组成的向量功能单元。他们可以在每个时钟周期内产生两个或者多个结果,但是同时也会有多个没有完全流水化的功能单元。为了简化讨论,我们的 VMIPS 实现中包括一个 lane,单个操作的 initiation rate 为每个周期一个元素。这样的话,单个向量指令的执行时间大约和向量的长度相等。
为了简化对于向量执行及其执行时间的讨论,我们会使用
convoy
这个概念。它指一组可以在一个时钟周期中同时执行的向量指令。(虽然 convoy 是一个向量编译中的概念,但是其实并不存在一个统一标准的术语。因此,我们创造了
convoy
这个术语。)在一个 convoy 中的指令之间必须不能有任何的 structural或者data hazard (虽然我们会在后面放宽这个限制)。如果有 hazard 的存在,这些指令必须被串行化,放置到不同的 convoy 中执行。把向量指令放到一个
convoy 中就好比把标量指令放到一条 VLIW 指令中一样。为了让我们的分析简单化,我们假定一个 convoy 中的指令必须在其他任何指令,包括标量指令和下一个 convoy 中的向量指令,开始之前完成执行。我们会在第 4 小节中通过使用一种更宽松的,但是更复杂的指令发射机制从而放宽对此的限制。
和 convoy 相对应的是 chime 这个概念。它可以用来估计一系列由 convoy 组成的向量操作的性能。一个 chime 是执行一个 convoy 所需要的时间。一个 chime是对一个向量操作序列执行时间的估计。Chime 与向量长度无关。因此,一个由 m 和 convoy 组成的向量序列的执行时间为 m 个 chime。如果向量长度为 n 的话,总共的执行时间大致为 m × n 个时钟周期。用 chime 来做估算忽略了一些与特定处理器相关的开销,很多与向量长度相关。因此,利用 chime 来估算执行时间对于长向量操作比较适用。我们之后会采用 chime 而不是时钟周期来估计执行时间以显式地忽略那些开销。
如果我们知道一串向量操作的 convoy 数目,我们就能知道以 chime 表示的执行时间。用 chime 估算时一个被忽略的因素是对于在一个周期内触发(initiate)多条指令执行的限制。如果在一个时钟周期中只能触发一条指令(这正是在大多数向量处理器中的实际情况),只计算 chime 数其实低估了一个 convoy 的执行时间。但是因为通常向量的长度比一个 convoy 中向量指令的个数来得多得多,我们可以简单地认为一个 convoy 的执行时间就是一个 chime。
————————————————————
例题:给出下面代码的 convoy 形式,假定每一个向量功能单元只有一个拷贝。
LV V1,Rx ;load vector X
MULVS.D V2,V1,F0 ;vector-scalar multiply
LV V3,Ry ;load vector Y
ADDV.D V4,V2,V3 ;add
SV Ry,V4 ;store the result
这个向量程序要花多少 chime?每 FLOP(floating-point operation)
需要多少时钟周期,假定忽略向量指令发射的开销?
解答:第一个 convoy 由第一个 LV 指令占据。 MULVS.D 和第一个 LV 相关,因此不能放在一个 convoy 中。第二个 LV 指令可以和 MULVS.D 在同一个 convoy中。ADDV.D 和第二个 LV 也有相关性,所以必须放在第三个 convoy 中。最后 SV依赖于 ADDV.D,所以必须进到下面一个 convoy 里。于是就有下面的 convoy 形式:
1. LV
2. MULVS.D LV
3. ADDV.D
4. SV
这个序列需要 4 个 convoy,因此需要花 4 个 chime的时间。
因为这个序列花 4个 chime,并且每个结果需要 2 个浮点操作,因此每一个 FLOP 要花 2 个时钟周期
(忽略任何向量指令发射开销)[3]。注意虽然我们允许 MULVS.D 和 LV 在convoy 2 中同时执行,大多数的向量机器需要2 个时钟周期去触发(initiate)这两条指令。
————————————————————
利用 chime 做估计对于长向量而言是合理的。比如,对于一个 64 个元素的向量而言,上例需要花费 4 个 chime,所以一共需要花费大约 256 个时钟周期。相比而言,在 2 个时钟周期里面发射一个 convoy 的开销就显得微不足道了。
另一个开销比上述的发射限制来得更为重要和显著。Chime 模型忽略的最大的开销是所谓的向量“启动”(start-up)时间。启动时间来源于执行向量指令的流水线延迟,并且由流水线深度主要决定。启动时间增加了执行一个 convoy 所需的实际执行时间,使之超过一个 chime。因为我们假定 convoy 之间互相不重叠,启动时间因此也延长了后续 convoy 的执行。当然因为后续的 convoy 和当前的 convoy 本身就有结构或者数据上的 hazard,不重叠的假定是合理的。完成一个 convoy 所需的时间实际上等于向量的长度加上其启动时间。如果向量的长度是无限的,启动时间的开销可以被均摊;但是有限长度的向量则会暴露启动延时,如下例所示。
————————————————————
例题:假定各功能部件的启动时间如图 F.4 所示。
给出每个 convoy 可以开始的时间以及总共需要的周期数。这个时间和单纯使用chime 的估计对于向量长度为 64 而言有和区别?
解答:图 F.5 给出了基于 convoy 的解答,假定向量的长度是 n。一个很恼人的问题是我们到底认为何时向量操作序列才算结束?这决定了 SV 的启动时间到底算还是不算。我们假定 SV 之后的指令不能进入其同一个 convoy,并且不同的convoy 不能互相重叠执行。那么总共的执行时间则需要计算到最后一个 convoy的最后一个向量指令结束。这仅仅是一个估算,最后一个向量指令的启动时间有时候可见,有时候不可见。为了简化讨论,我们始终计算它。
对于向量长度为 64 的实例而言,平均每出一个结果需要 4 + (42 / 64) = 4.65 个时钟周期,然而需要的 chime 数只是4。考虑了启动开销之后执行时间大约有 1.16倍的增加。
————————————————————

图 F.4 启动开销
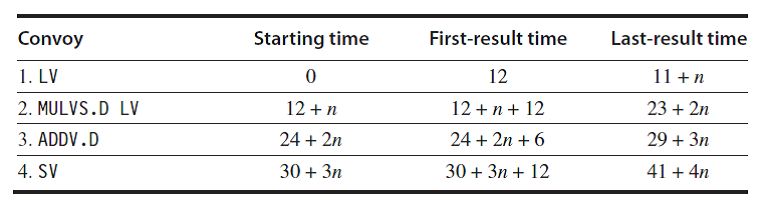
图 F.5 convoy 1 至 4 的开始时间以及给出第一个及最后一个结果的时间。 向量的长度是 n 。

图 F.6 VMIPS 的启动开销导致的性能惩罚。 这是 VMIPS 的向量操作的启动延迟导致的性能惩罚,以时钟周期数形式给出。
为了简化讨论,我们使用 chime 作为执行时间的估计,仅仅在我们需要详细的性能数据以展现某些优化技巧时才考虑启动时间。对于长向量而言,启动时间的开销并不大。在本附录稍后章节,我们将讨论如何降低启动开销。
一条指令的启动时间来源于执行该指令的功能单元的流水线的深度。如果我们想保持触发率(initiation rate)在每一个时钟周期给出一个结果,那么:
流水线深度 = [总共需要的执行时间 / 时钟周期长度
比如,如果一个操作需要花10个时钟周期,那么它必须被划分为 10 级流水进行操作才能保持触发率为平均一个时钟周期。流水线的深度取决于操作的复杂度和处理器的时钟周期长度。功能单元的流水线的深度变化很大--从 2 到 20 都不是不常见的--虽然大多数常用的单元都是 4~8 级流水。
对于 VMIPS 而言,我们采用和 Cray-1 一样的流水线深度,虽然在更多的现代处理器中延迟有所增加,特别是 load。所以的功能单元都是完全流水的。就如图F.6 所示,浮点加法的流水线的深度是 6 个时钟周期,浮点乘法的深度是 7 个时钟周期。在 VMIPS 上,就如同大多数的向量处理器,互相独立的使用不同的功能单元向量操作可以在一个 convoy 中发射。
---------------大家好,我是分割线---------------
[1] 这里所谓的动态指令是指在运行时实际执行的指令。在 MIPS 中,由于循环的存在,每一次迭代都需要重新取指。
[2] 所谓的循环冗余指令是为了维护循环的控制流而必须的指令,包括自减循环索引,判断是否达到循环边界,跳转等等。这些指令在向量处理器的代码中是不存在的--因为根本就没有循环的存在。
[3] 假定向量长度是 n,一共进行了 2 × n 个浮点操作(每个向量元素需要 2 个浮点操作),花了 4 × n 个时钟周期(假定每个 chime 的周期数等于向量长度),可以得到每 FLOP 需要 2 个时钟周期。或者可以更简单地来考虑:执行完所有的指令需要 4 个 chime,其实等效于每一个向量元素需要 4 个时钟周期来执行完其自身需要的操作。
2.3 向量处理器 Load-Store 单元及内存系统
向量处理器中 Load-Store 单元的行为远比算术功能部件复杂得多。Load 的启动时间(start-up)指的是把第一个 word 从内存中取到寄存器里花的时间。如果向量中剩下的部分可以没有停顿地从内存中给出,那么其触发率(initiation rate)就等于新的 word 被取出或者存进去的速率。不同于较为简单的功能部件,LS 单元的触发率不一定是 1 个时钟周期,因为 memory bank 的停顿会降低有效吞吐率。
通常来讲,LS
单元的启动时间带来的性能惩罚比算术功能部件要高--在某些处理器上超过 100 个时钟周期。对于 VMIPS 而言,我们假定启动时间是 12 个时钟周期,和 Cray-1 一样。图 F.6 总结了 VMIPS 向量操作的启动延迟。
为了维持触发率为每个周期取出或者存储 1 个 word,内存系统必须有能力给出或者接受那么多的数据。这通常可以由把访存操作分散到独立的 memory bank中实现。就像我们将在下一小节中会看到的,拥有很多的 bank 对于存取或者储存一行或者一列数据这样的向量访存操作很有效。
大多数的向量处理器基于以下三个原因采用 memory bank 而不是简单的interleaving [1]:
1.
大多数的向量处理器支持一个周期内进行多个 load 或者 store 操作,并且memory bank 的时钟周期通常是 CPU 时钟周期的几倍长。为了支持多个同时的访存操作,内存系统需要多个 memory bank,并且要有能力独立地控制访问每个 bank 的地址。
2.
就像我们在下一小节会看到的那样,很多向量处理器需要支持地址不连续的访存操作。在这样的情况下,需要独立的 bank 寻址,而不是简单的interleaving。
3.
很多向量计算机支持多个处理器共享一个内存系统,所以每个处理器会产生自己各自的独立的地址流。
总而言之,以上特性导致了向量处理器中大量的独立的 memory bank,就像下面的例子所示。
_____________________________________________________
例题:Cray T90 的 CPU 时钟周期是 2.167 ns,在最大的配置情况下
(Cray T932)有 32 个处理器,每个处理器可以在一个时钟周期产生 4 个 load 操作和 2 个store操作。CPU 的时钟周期是 2.167 ns,但是内存系统使用的 SRAM 的时钟周期是 15 ns。计算最少需要的 memory bank 数目以使得所有的 CPU 能够获得满内存带宽。
解答:每个时钟周期最大可能的访存数目是 192 (32 个 CPU,每个产生 6 个访存请求)。每个 SRAM bank 相当于 15 / 2.167 = 6.92 个CPU 时钟周期,进位到 7。所与我们最最少需要 192 × 7 = 1344 个 memory bank!
Cray T932 实际上有 1024 个 memory bank,所以它不能满足所有 CPU 同时的带宽要求。后继的
内存系统升级使用了 15 ns 的异步 SRAM 以及流水化的可以减半内存时钟周期的同步 SRAM ,从而提供足够的带宽。
_____________________________________________________
所需的访存速率和每个 bank 的访存时间决定了需要多少个 memory bank 以避免stall。下一个例子展示了这些时序的东西在向量处理器里是如何相互联系的。
_____________________________________________________
例题:假定我们想取出从地址 136 开始的 64 个向量元素,每一次访存操作耗时6 个时钟周期。需要多少个 memory bank 以支持平均每一个时钟周期一次 fetch操作?访问 bank 的地址分别是什么?各向量元素分别是在什么时刻到达 CPU?
解答:每次访存 6 个时钟周期意味着至少需要 6 个bank,因为我们希望 bank 数是 2 的幂,因为选择 8 个bank。图 F.7 展示了对于一个 8 bank,访存延迟为 6 个周期的内存系统进行开始几次访存的情形 [2]。
_____________________________________________________
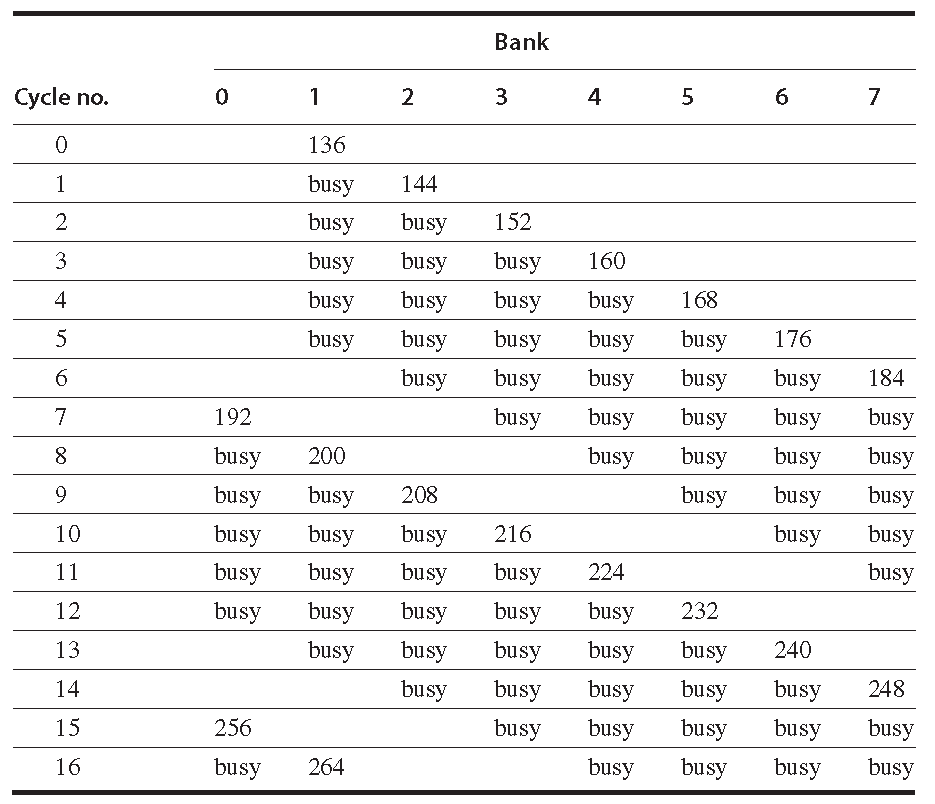
图 F.7 内存地址以bank 编号以及每个访存开始的时间。
每个 memory bank 在每个访存开始的时候锁存访存地址,然后用 6 个周期给出一个数据返回 CPU。注意 CPU 没法保持所有 8 个 bank 都处于忙碌状态,因为它在一个周期只能给出一个地址或者接受一个数据。
实际的 memory bank 的时序被分离成两个不同的部分:访存延迟(access latency)和 bank 周期时间(bank cycle time)或者 bank 忙碌时间(bank busy time)。访存延迟是指从地址到达 bank 开始直到 bank 给出一个数据的时间。忙碌时间指的是一个 bank 被一个访存请求占据而忙碌的时间。Access latency 是算在从内存中取出一个向量的启动开销里面的(总共的 memory latency 还包括穿越流水化的互联网络以从 CPU 传输地址和数据到 memory bank)。Bank 忙碌时间决定了一个内存系统的有效带宽因为处理器直到 bank 忙碌时间过去了才能发射到相同的 bank的第二个访存请求。
对于前例中使用的简单的非流水化的 SRAM bank而言,访存延迟和忙碌时间几乎是一样的。对于流水化的 SRAM 而言,访存延迟则大于忙碌时间因为一个元素的访存只会占据 memory bank 流水线的一级。对于 DRAM 的 bank 而言,访存延迟通常比忙碌时间短,因为 DRAM 在一次破坏性读取之后需要额外的时间来恢复被读出的值。对于一个支持多个向量访存同时进行或者非顺序访问的内存系统而言,所需的 memory bank 的数目应该比最低的要求来得多;否则则会发生 memory bank 冲突
(memory bank conflict)。我们会在下一节中详细讨论这个问题。
---------------大家好,我是分割线---------------
[1] 简单的 interleaving 可能指的是在同一个 memory bank 内部多个 memory chip之间地址的 interleaving。
[2] 注意每个向量元素都是 64 位,也即 8 byte。
3. 两个实际问题:向量长度和跨度
本小节解决两个来源于实际程序的问题:如果一个程序中向量的长度不是 64 的话我们怎么办?我们怎么处理在内存中不相邻的向量元素?让我们首先来考虑一下向量长度的问题。
3.1 向量长度控制
Vector-register 类的处理器有一个天然向量长度值,其取决于每个向量寄存器可容纳的元素个数。这个长度,对于 VMIPS 而言是 64,不太可能正好等于实际程序中的真实向量长度。另外,实际程序中的向量长度通常知道编译时才会知道。实际上,一段简单的代码都可能需要不同的向量长度。比如,考虑以下代码:
do 10 i = 1, n
10 Y(i) = a * X(i) + Y(i)
所有的向量操作的长度都取决于
n,而 n 知道运行时才知道!n 甚至可能是一个包含上面代码的函数的参数,因此在执行的过程中其值会变化。
解决这个问题的方法是引入一个向量长度寄存器(vector-length register,VLR)。VLR 控制了任何向量操作的长度,包括向量 L/S 操作。但是VLR 的值不能比向量寄存器的长度更大。只要实际的向量长度不超过由处理器自己定义的最大向量长度(maximum vector length,MVL),VLR 就可以解决我们的问题。
如果在编译的时候不知道 n 的值,它有可能比 MVL 大。为了解决这个问题,我们引入strip mining 技术。Strip mining 实际上是一个代码生成的技术,它使得每个向量操作都由一系列长度不超过 MVL 的向量子操作完成。我们可以对一个循环采用类似循环展开技术(参考附录 G)的方法进行 strip-mining:生成一个可以反复迭代的循环来处理长度为 MVL 的向量操作和另一个处理剩下部分的循环,后一循环的长度一定比 MVL 小。实际情况中,编译器通常只会生成一个参数化的循环来动态地处理长度的变化以包含上述两种情况。下面给出了 Stripe-mined 的版本的 DAXPY 程序,以 FORTRAN 语言(大多数科学计算程序的主要语言)写成,C 语言风格给出注释:
low = 1
VL = (n mod MVL) /*find the odd-size piece*/
do 1 j = 0, (n / MVL) /*outer loop*/
do 10 i = low, low + VL - 1 /*runs for length VL*/
Y(i) = a * X(i) + Y(i) /*main operation*/
10 continue
low = low + VL /*start of next vector*/
VL = MVL /*reset the length to max*/
1 continue
n / MVL 这一项代表了截取的整数部分(FORTRAN 就是这么干的)并且在整个程序中都要用到。以上循环的效果是把一个向量分成几段,然后由内循环来处理。第一段的长度是 (n mod MVL),而所有之后的段长度都是 MVL。参考图 F.8的图例。
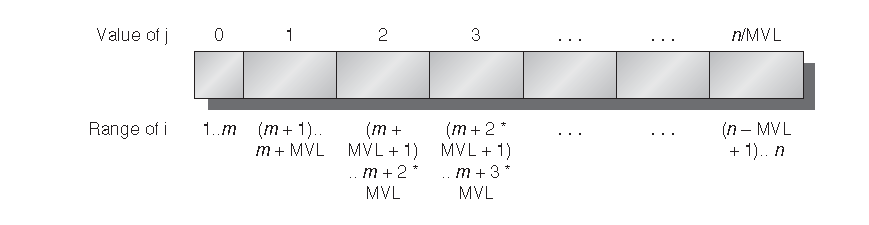
图 F.8 以 strip-mining 技术处理任意长度的向量操作。除了第一段以外所有的分段的长度都是 MVL以充分利用向量处理器的能力。在本图中,变量 m 代替了(n mod MVL)。
上述代码中的内层循环被向量化成长度为 VL,其值等于 (n mod MVL) 或者MVL。VLR 必须被设置两次--每次 VL 被赋值的地方。在多个向量操作并行执行的情况下,硬件必须在向量操作发射时把 VLR 的值拷贝多份到不同的向量功能部件处,以应对 VLR 可能在后续的向量操作中改变的情形。
有些向量指令集已经可以支持不同的 MVL。比如 IBM 370 系列大型机的向量扩展支持从8 到 512 之间的任何 MVL。它提供了一条 load vector count and update(VLVCU)指令来控制 strip-mined 的循环。VLVCU 指令用一个标量操作数来指出期望的向量长度。VLR 被设置成期望的向量长度和MVL 中较小的一个,并且这个值要被从一个标量寄存器里面减去从而设置条件码以指示循环是否结束。通过这种方式,目标代码不需要做任何改变就可可以在两种不同的实现之间迁移,并且充分利用可能的最大向量长度。
除了启动延迟外,我们还需要考虑 strip-mining 带来的开销。假定任何 convoy都不能和其他的指令重叠执行的话,由重新启动向量序列以及设置 VLR 带来的strip-mining 开销增加了实际的启动开销。如果这个额外开销对于一个 convoy而言是 10 个周期的话,那么每 64 个向量元素的开销增加了 10 个周期,或者说每个元素 0.15 个周期。
决定一个由一系列 convoy 组成的 strip-mining 循环执行时间的有两个重要因素:
1. 一个循环中 convoy 的个数。它决定了 chime 的个数。我们使用 Tchime 来表示以 chime 表示的执行时间。
2. 执行 convoy 序列的开销。包括执行每个分段中标量代码的开销 Tloop 以及每个 convoy 的启动时间 Tstart。
在第一次建立向量序列的时候可能还会有一些固定的开销。在最近的向量处理器中,这种开销已经很小了,所以我们忽略之。
我们用 Tn 来代表一个向量操作序列作用于一个长度为 n 的向量上的总共运行时间:
Tn = [n / MVL] × (Tloop + Tstart) + n × Tchime
Tloop,Tstart 和 Tchime 的值都是和编译器还有处理器相关的。基于对于 Cray-1的很多测试的结果,我们选择 15 作为 Tloop 的值。乍一看,你可能认为这个值很小。每个循环的额外开销包括设置向量的起始地址和跨度(stride),自增循环计数器,然后执行循环分支指令。织机上,这些标量指令可以全部或者部分地和向量指令重叠,最小化这些额外开销。Tloop 的值当然取决于循环的结构,但是它们之间的依赖性相比向量代码和Tstart 以及 Tchime 的值之间的联系而言就比较小了。
_____________________________________________________
例题:在 VMIPS 上 A= B × s 的执行时间是多少?其中 s 是一个标量,A 和 B 的长度为 200。
解答:假设 A 和 B 的起始地址被初始化在 Ra 和 Rb 中,s 在 Fs 中。另外回忆一下,在 MIPS (因此VMIPS)中,R0 中的值永远是 0.因为 (200 mod 64) = 8,strip-mined 之后的循环的第一次迭代会执行于长度为 8 的向量上,之后的迭代作用于长度为 64 的向量。每个向量的下一个分段的起始地址是向量长度的 8 倍。因为向量长度或者是 8,或者是 64,我们在第一个分段之后把地址寄存器的值加 8× 8 = 64 而对于后面的几个分段则加上 8 × 64 = 512。每个向量的总字节数是 8× 200 = 1600。我们通过比较起始地址加上 1600 和下一个向量分段的起始地址来确定循环是否应该结束。以下是实际的代码:
DADDUI R2,R0,#1600 ;total # bytes in vector
DADDU R2,R2,Ra ;address of the end of A vector
DADDUI R1,R0,#8 ;loads length of 1st segment
MTC1 VLR,R1 ;load vector length in VLR
DADDUI R1,R0,#64 ;length in bytes of 1st segment
DADDUI R3,R0,#64 ;vector length of other segments
LV V1,Rb ;load B
MULVS.D V2,V1,Fs ;vector * scalar
SV Ra,V2 ;store A
DADDU Ra,Ra,R1 ;address of next segment of A
DADDU Rb,Rb,R1 ;address of next segment of B
DADDUI R1,R0,#512 ;load byte offset next segment
MTC1 VLR,R3 ;set length to 64 elements
DSUBU R4,R2,Ra ;at the end of A?
BNEZ R4,Loop ;if not, go back
这个循环中的三条向量指令互相依赖,因为必须进入到三个 convoy 中,因此Tchime = 3.让我们使用我们的基本公式:
Tn = [n / MVL] × (Tloop + Tstart) + n × Tchime
T200 = 4 × (15 + Tstart) + 200 × 3
T200 = 60 + (4 × Tstart) + 600 = 660 + (4 × Tstart)
Tstart 的值是以下几项的和:
- load 指令的启动时间 12 个时钟周期
- multiply 指令的 7 个周期的启动时间
- store 指令的 12 个周期的启动时间
因此,Tstart 的值由下式给出:
Tstart = 12 + 7 + 12 = 31
所以,总共的执行时间为:
T200 = 660 + 4 ×31 = 784
每个元素的平均执行时间为 784 / 200 = 3.9,而利用 chime 做的估算则为 3。在第4 小节,我们会更激进一些--允许不同的 convoy 的执行相互重叠。
_____________________________________________________
图 F.9 给出了对于前面的例子(A= B × s)平均每个元素的执行开销随着向量长度的变化。chime 的模型给出的结果是平均每个元素的 3 个时钟周期,不过前述的两个额外开销来源给每个元素增加了 0.9 个时钟周期。
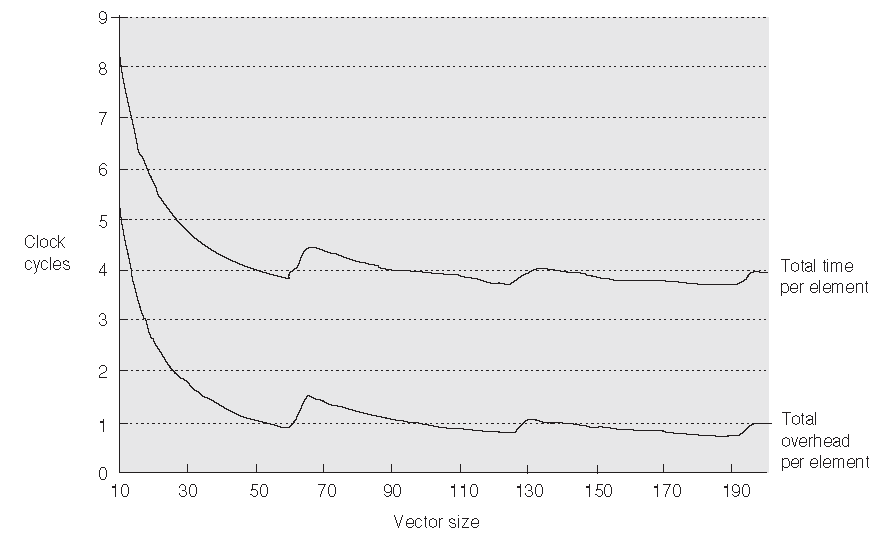
图 F.9 每个元素的平均执行时间和每个元素的平均额外开销随向量长度的变化。 对于短向量而言,启动时间超过了总共时间的一半,但是对于长向量而言,这个比例减少到了三分之一。在向量长度穿过 64 的倍数的时候会有一个跳变,因为这产生了一个新的循环迭代和一组新的向量指令的执行。这些操作给 Tn 增加了 Tloop + Tstart 。
接下来的几节会介绍几个减少这些额外开销的技术。我们会看到如何利用一个被称为 chaining 的方法来减少 convoy 的数目从而减少 chime 的数目。每个循环的开销 Tloop 可以通过进一步重叠向量和标量的执行,允许一个循环中的标量的执行和前一个循环的向量指令的执行的完成,来降低。最后,向量的启动延迟可以通过一个允许不同 convoy 中的向量指令的重叠执行而消除。
3.2 向量跨度
本节的第二个要解决的问题是,一个向量中相邻的元素在内存中的位置不一定是顺序的。考虑以下直观的矩阵相乘的代码:
do 10 i = 1, 100
do 10 j = 1, 100
A(i, j) = 0.0
do 10 k = 1, 100
10 A(i, j) = A(i, j) + B(i, k) * C(k, j)
在标号为 10 的这条语句这里,我们可以向量化 B 的一整行和 C 的一整列的相乘,并且以 k 作为下标对内层循环采取 strip-mine 技术。
要能这么干的话,我们必须考虑 B 中相邻的元素和 C 中相邻元素是如何被寻址的。当在内存中为一个数组开辟空间时,它是线性化的,并且必须以或者 row-major 或者 column-major 为准排布数据。这样的线性化意味着一行或者一列的元素在内存中是不相邻的。比如,如果上述循环代码是用 FORTRAN 语言写的,也即是以 column-major 的方式排布数据,那么在内层循环中 B 的相邻元素互相之间将有 8(每个元素的字节大小)倍于行长度的距离,总共是 800 字节。在第五章,我们看到了 blocking 的技术可以用以增加在基于 cache 的系统的局部性。对于向量处理器而言,它没有 cache,我们需要另一种技术来取出那些在内存中不相邻的元素。
我们称把分开两个要被收集(gather)到一个寄存器里的两个元素的距离为跨度(stride)。在这个例子中,用 column-major 的数据排布方式意味着矩阵 C 的stride 为1,或者说 1 个双字(8 个字节),而矩阵 B 的 stride 为 100,或者说 100个双字(800 个字节)。
只要一个向量被 load 到向量寄存器之后,它就好像在逻辑上是相邻的元素了。因此一个 vector-register 型的处理器可以处理 stride 大于 1 的情况,称之为非单元化跨度(nonunit stride),只要向量的 L/S 操作有处理 stride 的能力即可。这种访问不连续的内存地址并且把它们重构成为一个紧致的数据结构的能力是向量处理器相比基于 cache 的处理器的一大优点。cache 内在而言是处理单元化跨度(unit stride)的数据的 [1],所以虽然增加 block 的大小可以降低有单元化跨度访问特性的大规模数据集的缺失率,但是另一方面对于以非单元化跨度模式访问的数据而言有负面影响。虽然 blocking 可以部分解决这些问题(参考 5.2 小节),能够访问不连续的数据的能力仍然是向量处理器在这类问题上的优势。
在 VMIPS 上,可寻址的最小单元是一个字节,因此我们的例子中 stride 是 800。这个值必须动态求得,因为矩阵的大小有可能在编译时并不知道,或者--就像向量的长度一样--可能在执行时因为对同一条语句的多次执行而变化。向量跨度,就和向量的起始地址一样,可以被放入一个通用寄存器中。然后可以使用VMIPS 的 LVWS (load vector with stride)指令取出某个向量置入向量寄存器中。同样的,当 store 一个非单元化跨度的向量时,可以使用 SVWS (store vector with stride)指令。在有些向量处理器上,L/S 指令总是需要一个存储在寄存器中的 stride 值,所以只需要一条 load 指令和一条 store 指令就够了。单元化跨度的访问比非单元化跨度访问频繁得多,并且可以从内存系统的特别处理中获益,因此就像在 VMIPS 中一样通常是和非单元化跨度访问分开的。
内存系统因为支持大于 1 的 stride 而变得复杂。在我们之前的例子中,我们看到如果 memory bank 的数目至少和 bank 忙碌时间(bank busy time)的时钟周期数一样的话,单元化跨度访问就可以满速进行。然而,一旦非单元化跨度被引入,很可能访问同一个 bank 的频率会超过 bank 忙碌时间所允许的最大值。当几个访问竞争同一个 bank 的时候,bank 冲突(bank conflict)就会发生,其中的一个访问必须停顿。bank 冲突,也即bank 停顿,满足以下条件就会产生:
bank 数目 / 最小公倍数(跨度,bank 数目) < bank 忙碌时间
_____________________________________________________
例题:假定我们有 8 个 memory bank,每个 bank 的忙碌时间是6 个时钟周期,并且内存的访问延迟是 12 个周期。对 64 个向量元素进行 stride 为 1 的访问需要多少时间?如果 stride 是 32 呢?[2]
解答:对于 stride 为 1 的情形,因为 bank 的数目大于 bank 的忙碌时间,所以load 操作会花 12 + 64 = 76 个周期,或者说平均每个元素 1.2 个周期。最差的stride 情况是 memory bank 数目的倍数,就像在本例中,8 个 memory bank,stride 为 32。每个访存操作(除了第一个)都会和前一个操作冲突,因此需要等待 6 个周期的 bank 忙碌时间。总共的时间是 12 + 1 + 6 × 63 = 391 个周期 [3],或者说平均每个元素 6.1 个周期。
_____________________________________________________
如果 memory bank 的数目和 stride 互素,并且有足够多的 bank 来防止单元化跨度访问的冲突,那么 memory bank 冲突就不会发生。在没有 bank 冲突的时候,多字访问和单元化跨度访问的速度是一样的。增加 bank 的数目超过最少满足单元化跨度访问无冲突的需求会减少可能的停顿的发生频率。比如,对于 64 个bank 而言,跨度为 32 的访问会每隔一次产生,而不是每次访问都产生。如果我们一开始的时候 stride 是 8, bank 数目是 16,那么同样每隔一次访问会产生一次停顿。但是如果有 64 个 bank,stride 为 8 的访问会每隔 8 个才停顿。如果我们有多条存储流水线(memory pipeline)[4] 或者多个处理器共享一个内存系统,我们就会需要更多的 bank 以避免冲突。即使对于只有一条 memory 流水线并且访存模式为单元化跨度的机器而言,我们仍然会在一条指令的最后几个元素和下一条指令的头几个元素之间遇到冲突。增加 bank 数目有助于降低这种指令间冲突的可能性。在 2006 年,大多数的向量超级计算机都把每个 CPU 的访存请求分布到几百个 memory bank 上。因为 bank 冲突仍然有可能在非单元化跨度访问时发生,程序员无论何时都倾向于单元化访问。
一台现代超级计算机可能有几打 CPU,每个都有好几条存储流水线连接到几千个 memory bank。在每个存储流水线和每个 memory bank 之间都只用专用的通路是不切实际的。所以通常我们会使用一个多级的交换网络(switching network)来连接存储流水线和 memory bank。在不同的向量访问竞争同一条线路时会发生网络的拥挤,导致内存系统额外的停顿。
---------------大家好,我是分割线---------------
[1] unit stride 指的是 stride 为 1 的情形。这段话的基本意思是如果访问的数据不具有很好的局部性,那么 cache 的效果会非常差。
[2] 想一想什么情况下内存的访问延迟会是 bank 的忙碌时间的两倍?
[3] 为什么这里要额外加 1?为什么前一种情况是 12 + 64 而不是 12 + 63?这里额外的 1 可能是数据从 memory system 给出到到达处理器经过互联网络时的耗时。
[4] 我认为存储流水线(memory pipeline)是一个重要但是模糊的概念,参见此专用页面。
4. 改进向量处理器性能
在这一节里我们会展示五种改善向量处理器性能的技术。第一种技术,称之为链接(chaining),能够让一系列相互依赖的向量操作运行得更快。它起源于Cray-1,但是现在大多数的向量处理器都支持这种技术。接下来两种技术通过引入新的向量指令类型来处理条件执行(conditional execution)和稀疏矩阵从而扩展可以被向量化的循环类型。第四种技术通过以增加道(lane)的方式增加更多的并行执行单元来提升向量处理器的峰值性能。第五种技术通过流水化以及重叠指令的启动来降低启动开销。
4.1 链接(chaining)--前推(forwarding)的概念在向量寄存器上的扩展
考虑一下简单的向量序列:
MULV.D V1, V2, V3
ADDV.D V4, V1, V5
在 VMIPS 中,就像我们看到的那样,这两条指令必须放到两个独立的 convoy中,因为他们是互相依赖的。另一方面,如果我们把向量寄存器,在本例中即V1,不看成一个单个个体,而是看成一组寄存器,那么所谓前推(forwarding)的概念就可以扩展以作用于向量的每个元素上。这一允许 ADDV.D 更早开始执行的电子称为链接(chaining)。Chaining 允许只要一个向量操作的源操作向量中的某个元素已经准备就绪时就开始执行该元素的操作:在链(chain)中,前一个功能单元的结果被 forward 到后一个功能单元。在实际中,chaining 通常是通过允许处理器同时读写同一个向量寄存器的不同元素来实现的。早期的chaining 确实是以类似前推的方式工作的,但是这限制了链中源指令和目的指令的时序。近来的实现采用了灵活链接(flexible chaining)的方法,允许一个向量指令和任何别的活跃的向量指令链接,只要没有结构 hazard [1]。Flexible chaining 需要几条指令同时访问一个向量寄存器,这可以通过增加读写端口或者把向量寄存器文件组织成类似于内存系统里 bank 的形式类实现。我们在整个附录里就假定采用这种链接方式。
虽然一组操作互相依赖,但是 chaining 允许对于不同元素的操作并行执行。这使得这一组操作能够被调度到一个 convoy 中,从而减少 chime 的数目。对于前一个例子而言,可以达到持续达到每一个周期 2 个浮点操作,或者一个chime,的速率(不考虑启动开销),即使他们是互相依赖的!它的总共执行时间为:
向量长度 + ADDV 的启动时间 + MULV 的启动时间
图 F.10 展示了上例链接和没有链接两个版本的情况,其中向量长度为 64。新的convoy 仍然只需要一个 chime,但是因为他使用了 chaining,启动时间会很显著。在图 F.10 中,链接版本的总共执行时间为 77 个时钟周期,或者说平均一个结果 1.2 个周期。由于有 128 个浮点操作在其间执行,所以我们达到了 1.7 FLOPS每周期。对于未链接版本,一共要花费 141 个周期,或者说 0.9 FLOPS 每周期。
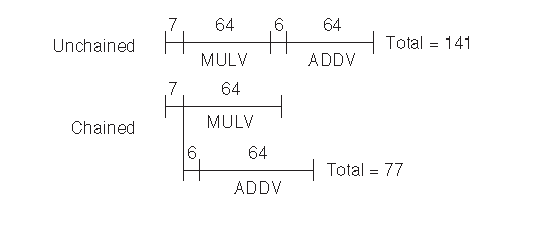
图 F.10 链接和未链接版本的一个互相依赖的 ADDV 和 MULV 向量操作序列的时序。
图中 6 和 7 个时钟周期的延迟分别是加法和乘法的延迟。
虽然 chaining 通过把两个互相依赖的操作放置到同一个 convoy 的方式减少了以chime 表示的执行时间,它并没有降低启动延迟。如果我们期望得到一个精确执行时间,我们就必须考虑启动开销。在 chaining 技术中,一个向量序列的chime 数由不同的功能单元的个数以及程序所需的实际个数所决定。特别注意的是在任何 convoy 中都不能有结构 hazard。这意味着在 VMIPS 这样只有一个向量 load-store 单元的处理器上,如果一个程序有两个向量指令,那它必须至少占据两个 convoy,因此至少花两个 chime 的时间。
我们会在第六小节看到 chaining 对提升性能有极其重要的作用。实际上,chaining 是如此的重要以至于现在每一个向量处理器都支持 flexible chaining。
4.2 条件执行语句
根据 Amdahl 定律,我们知道如果一个程序可向量化部分很少或者不高,那么加速比是非常有限的。两个限制向量化的原因是在循环内部条件代码的存在以及稀疏矩阵的使用。在循环里包含 if 语句的程序不能在向量模式下执行,因为if 语句引入了循环内部的控制依赖(control dependency)。同样的,稀疏矩阵也不能有效地利用我们之前讨论过的相关技术有效实现。我们在这一小节讨论如何处理条件执行,下一小节讨论稀疏矩阵。
考虑如下循环:
do 100 i = 1, 64
if (A(i).ne. 0) then
A(i) = A(i) - B(i)
end if
100 continue
这个循环由于包含有条件执行而不能正常地向量化。但是如果内层循环可以对A(i) != 0 的部分进行迭代,那么减法操作就可以被向量化。在附录 G 中,我们看到了条件执行指令不是正常指令集的不一份。它们可以把控制依赖转换成为数据依赖,从而增加了循环的并行度。向量处理器可以类似地获益。
通常我们使用的一种扩展技术称为向量-掩码控制(vector-mask control)。Vector-mask control 利用一个长度为 MVL 的二值向量来控制向量指令的执行,就如同条件执行指令利用一个二值条件来决定一条指令是否执行一样。当向量-掩码寄存器(vector-mask register)被启用的时候,任何向量指令都只作用于向量掩码寄存器中相应元素值为 1 的那些向量元素上。在目的向量寄存器(destination vector register)中那些掩码寄存器里对应位置为 0 的元素不受向量操作的影响。如果向量-掩码寄存器由某个条件语句的结果来设置,那么只有满足条件的元素才会受到影响。把该寄存器清空表示将里面所有元素的值设为 1,使得后续的向量操作作用于所有的向量元素上。下面的代码可以用来实现前面的循环,假定 A 和 B 的起始地址分别在 Ra 和 Rb中。
LV V1, Ra ;load vector A into V1
LV V2, Rb ;load vector B
L.D F0, #0 ;load FP zero into F0
SNEVS.D V1, F0 ;set VM(i) to 1 if V1(i) != F0
SUBV.D V1, V1, V2 ;subtract under vector mask [2]
CVM ;set the vector mask to all 1s
SV Ra, V1 ;store the result in A
大多数最近的向量处理器都提供了向量-掩码控制。在这里描述的这种向量-掩码在大多数的处理器里都可以看到,但是另外一些允许向量掩码只作用于一部分的向量指令上。
然而,利用向量-掩码寄存器也有缺点。在讨论条件执行指令时,我们看到即使条件没有满足,该指令仍然需要花时间。但是,消除了分支和相应的控制依赖仍然使得条件指令执行地更快即使它得做一些没用的工作。同样的,应用向量掩码的向量指令即使对那些掩码值为 0 的元素而言也需要一定的执行时间。同理,即使大部分掩码值都为 0,使用向量-掩码控制仍然可能会比标量模式要快得多。实际上,在向量模式和标量模式之间巨大的潜在性能差距使得包含向量-掩码指令非常重要。
第二,在有些向量处理器中,向量掩码只用于禁止结果写回目的寄存器,而实际的计算操作会发生。这样的话,如果在前面例子中的操作是除法而不是减法,并且是对 B 而不是 A 进行条件测试,那么由于除数为 0 导致的浮点异常可能会发生。利用掩码同时屏蔽计算和写回的处理器可以避免这个问题。
---------------大家好,我是分割线---------------
[1] Flexible chaining 简单来讲就是放宽了 chaining 的限制。最初的 chaining 只能作用于相邻的两条指令之间。但是很有可能由于写程序的关系,原本可以chaining 的两条语句被人为地分开了而不能利用 chaining 技术。Flexible chaining允许这两条不相邻的指令重叠执行。
[2] 想一想这条指令硬件有可能是如何执行的?
4.3 稀疏矩阵
存在一些能够使得基于稀疏矩阵的程序在向量模式下运行的技术。在一个稀疏矩阵中,向量的元素通常是以紧凑的形式储存,并且以间接的方式被访问。我们会看到以下一个简化了的稀疏矩阵的代码:
do 100 i = 1, n
100 A(K(i)) = A(K(i)) + C(M(i))
这段代码利用 K 和 M 作为索引向量来给出 A 和 C 中的非零元素实现了数组 A 和C 的稀疏向量求和和。(A 和 C 必须有相同数目个非零元素--本例中的 n)另外一个常见的稀疏矩阵的表示形式是用一个位向量来表示哪些位是非零元素以及一个稠密向量包含所有的非零元素。通常这两种表示形式会同时在一个程序里出现。在很多代码里都能看到稀疏矩阵的影子,并且根据不同的数据结构有很多中实现方法。
支持稀疏矩阵的最主要的机制是利用索引向量(index vector)的 scatter-gather操作。这类操作的目标是支持在稠密表示(即没有非零元素)和正常表示(即包括非零元素)之间进行数据迁移。Gather 操作根据一个索引向量,通过把索引向量给出的偏移值加到基地址上来取出向量的元素。其输出是在一个在向量寄存器里的稀疏向量。在这些元素以稠密的形式被处理之后,稀疏向量要以扩展的形式通过 scatter 操作存回内存,使用同样的索引数组。对于这两个操作的硬件支持称之为 scatter-gather,并且在几乎所有的现在向量处理器上都能看到。VMIPS 提供了 LVI(load vector indexed)和 SVI(store vector indexed)指令来实现这两个操作。比如,假定 Ra,Rc,Rk 和 Rm 分别有前例中四个向量的起始地址,那么彼代码段的内层循环可以用以下的向量指令实现:
LV Vk, Rk ;load K
LVI Va, (Ra + Vk) ;load A(K(I))
LV Vm, Rm ;load M
LVI Vc, (Rc + Vm) ;load C(M(I))
ADDV.D Va, Va, Vc ;add them
SVI (Ra + Vk), Va ;store A(K(I))
这个技术使得稀疏矩阵的代码可以以向量模式执行。简单的向量编译器不能自动向量化以上代码,因为编译器不会知道 K 中的元素的值互相是不相同的,因此不存在任何依赖关系 [1]。因此,程序员需要告诉编译器该循环可以以向量模式运行。
更为复杂的向量编译器可以自动向量化以上循环而不需要程序员的干预。这是通过插入运行时对于数据 dependency 的检查实现的。这种运行时检查是通过 Itanium 处理器中的 Advanced Load Address Table(ALAT)硬件机构的向量化软件版本实现的。ALAT 在
附录 G 中有描述。ALAT 硬件被一个软件哈希表所代替。该哈希表能够检测出在同一个 strip-mining 的迭代循环中的两个元素是否指向同一个地址。如果没有检测到 dependency,该 strip-mining 循环则可以以长度 MVL 来完成。如果检测到了 dependency,向量的长度则被重置为较小的一个可以避免 dependency 的值,而留下剩下的部分给下一个循环执行。虽然这种机制给执行循环增加了很多软件开销,但是这种开销还是会被更为常见的没有依赖的情况所均摊,因此这个循环仍然会比标量代码快得多(当然会比程序员直接指出可以向量化的情况慢得多)。
近来大多数的超级计算机都有 scatter-gather 的能力。这种操作比有跨度的操作更为之慢因为实现起来更复杂,而且更容易出现 bank 冲突,但是比之标量版本,则要快很多。如果一个矩阵的稀疏程度改变了,必须重新计算索引向量。很多处理器提供了快速计算所以向量的方法。VMIPS 中的 CVI 指令可以根据一个给定的跨度值(m)来创建一个所以向量。其各个元素值为0,m,2×m,...,63×m。一些处理器提供一条创建压缩形式的索引向量的指令。该向量中各元素值对应于掩码寄存器中相应位置为 1 的元素。另外一些则提供压缩向量的指令。在 VMIPS 中,我们定义 CVI 指令为总是根据向量掩码来创建一个压缩过的索引向量。当所有的掩码都为 1 的时候,则创建一个标准的索引向量。
索引化的 L/S 操作以及 CVI 指令提供了支持条件向量执行的一种新方法。以下是我们在上一小节中循环的另一种实现:
LV V1, Ra ;load vector A into V1
L.D F0, #0 ;load FP zero into F0
SNEVS.D V1, F0 ;sets the VM to 1 if V1(i) != F0
CVI V2, #8 ;generates indices in V2
POP R1, VM ;find the number of 1's in VM
MTC1 VLR, R1 ;load vector-length register
CVM ;clears the mask
LVI V3, (Ra + V2) ;load the nonzero A elements
LVI V4, (Rb + V2) ;load corresponding B elements
SUBV.D V3, V3, V4 ;do the subtract
SVI (Ra + V2), V3 ;store A back
至于究竟是使用 scatter-gather 的版本更好还是使用条件执行的版本更好取决于该条件测试满足的频率以及这些操作的开销。不考虑 chaining 的话,第一个版本(前一小节)的耗时是 5n + c1。第二个版本,也即采用每一个周期能执行对于一个元素索引化 L/S 的版本,的执行时间是4n + 4fn + c2 [2],其中 f 是条件测试满足(也即A(i) != 0)的比率。如果我们假设 c1 和 c2 差不多,或者说他们都远小于 n,我们可以求出什么时候第二个版本会更好。
Time1 = 5n
Time2 = 4n + 4fn
如果我们要 Time1 > Time2,那么
5n > 4n + 4fn
1/4 > f
也就是说,如果小于 1/4 的元素是非零元素,那么第二个版本更好。在很多情况下,条件满足的比率要小得多。如果可以索引向量可以被重用,或者在 if 语句下的向量语句 [3] 的数目增加,scatter-gather 的优势会显著增加。
---------------大家好,我是分割线---------------
[1] 如果 K 中有两个元素的值相等,那么它们会指向对于 A 中同一个元素进行操作。简单的编译器会认为这两个操作之间有相互数据依赖而不能自动并行化。
[2] 为什么是 4n + 4fn?在第二个版本中,需要完全执行(也即需要遍历向量中所有的元素)的向量指令是 LV,SNEVS.D,CVI,POP;需要部分执行(也即只需要对满足条件的向量元素进行操作)的指令是 2 条 LVI,SUBV.D,SVI。条件满足的比率是 f。
[3] 也就是满足条件测试后所需要执行的那部分语句。拿本例来说,如果 A(i) != 0 的情况下不仅仅是做简单的减法而是执行一系列复杂的操作,那么索引化L/S的优势更明显。原因在于索引化 L/S 相比原来只用掩码的版本的优点正在于减少了 if 语句下的那些指令的执行时间(即只对满足条件的元素执行操作)。如果 if 语句下的那些指令数目增大,这个优势会被扩大。读者可以用上面给出的分析模型定性分析。
4.4 多道向量处理器
向量指令集的一个最大的优点是它能够允许软件传递大量的并行任务给硬件,而只需要一条很短的指令即可。一条向量指令可以包括数十上百个独立的操作,但是仍然和通常的标量指令一样译码为相同的长度。向量指令的并行语义使得执行这些元素操作有两种方法。第一是使用深度流水化的功能单元,就像我们研究的 VMIPS 一样;或者通过一组并行的功能单元,或者是并行单元和流水化单元的组合。图 F.11 展示了如何通过使用并行流水线执行向量 add 指令来提升向量性能。

图 F.11 使用多个功能单元来改进 add 向量指令 C = A + B 的性能。 ( a )中的机器有一条 add 流水线,可以在每个周期完成一次加法。( b )中的机器有四个加法流水线,并且在每个周期可以完成 4 个加法才做。一个向量加法操作涉及到的那些元素被分散分布在四条流水线上。一起通过这些流水线的那组元素被称为元素组( element group )。
VMIPS 指令集设计的特点是所有的向量指令只允许一个向量寄存器的 N 个元素和另一个向量寄存器的 N 个元素参与运算。这极大地简化了可被组织成多个并行道(lane)的高度并行的向量单元的设计。就像一个高速公路一样,我们可以通过增加更多的 lane 来提升一个向量单元的峰值吞吐率,如图 F.12 所示。
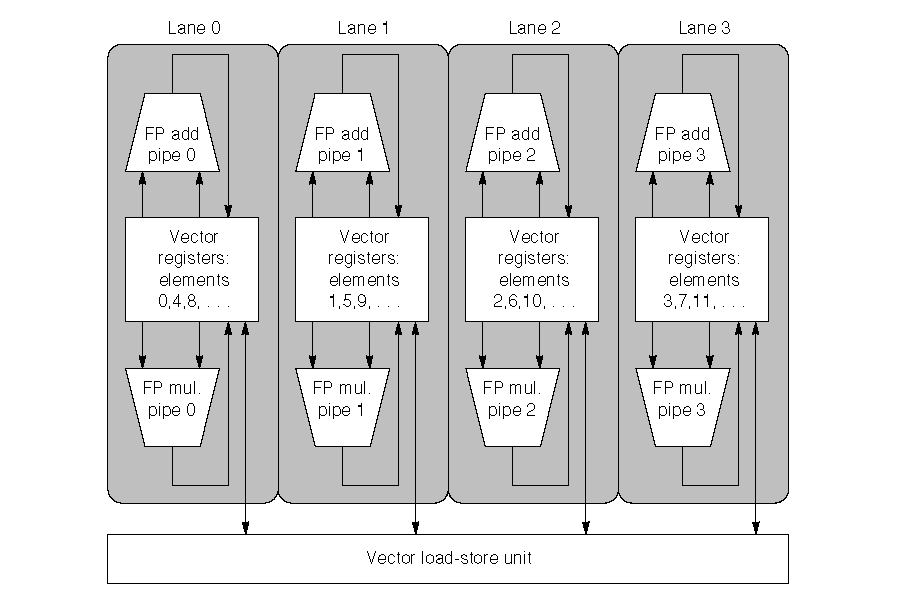
图 F.12 一个包含有 4 个道的向量单元的结构。向量寄存器的存储被分布在各lane 之间,每个 lane 包含有每个向量寄存器的 4 个元素。图中展示了 3 个向量功能单元,一个浮点加法单元,一个浮点乘法单元,以及一个 L/S 单元。每个向量算术单元包含有 4 个执行流水线,每个 lane 一个。他们协同共组去完成每一条向量指令。注意向量寄存器的每一个部分是如何只需要提供本地的 lane 访问的足够端口即可的。这极大减少了提供多端口的开销。提供向量-标量指令(vector-scalar instruction)中标量操作数的通路并没有在这张图中显示出来,但是标量值必须被广播到所有的 lane 中。
每一个 lane 包含了向量寄存器文件的一部分以及每个向量功能单元中的一条流水线。每个向量功能单元通过多个流水线(每个 lane 一个)以每个周期一个element group 的速率来执行向量指令。第一个 lane 包含有所有向量寄存器的第一个元素,因此任何有关第一个元素的向量指令的源操作数和目的操作数都在第一个 lane 中。这使得一个算术运算的流水线的操作能在一个 lane 内部完成而不需要和其他 lane 通信。Lane 间互联只是在访存的时候才需要。缺少 lane 间通信能够降低互联导线开销和用于高度并行执行单元的寄存器文件的端口,并且解释了为什么当前的超级计算机可以在每个周期完成至多 64 个操作(16 个lane,每个有 2 个算术单元和 2 个 L/S 单元)。
增加多个 lane 是一种很通用的提升向量性能的技术,因为它只需要很小的控制复杂度上的靠小,并且不需要改动现有的代码。有一些向量超级计算机以 lane数目可变的系列方式进行销售。这使得用户能够自行权衡价格和峰值性能。Cray SV1 和 X1 允许 4 个 2 道的向量 CPU 组合在一起形成一个单个更大的 8道 CPU,具体在第七小节讨论。
4.5 流水化指令的启动
增加多条道能够提升峰值性能,但是却不能改变启动延迟,所以通过允许一条向量指令的开始与之前一条指令的完成想重合来降低启动开销就变得很关键了。最简单的情形是当两个向量指令访问不同的向量寄存器的时候。比如,在下面的代码段中:
ADDV.D
V1, V2, V3
ADDV.D
V4, V5, V6
一种实现方式是允许第二条指令中的第一个元素紧跟着第一条指令的最后一个元素在浮点加法流水线中执行。为了减少控制逻辑的复杂度,有些向量机器在分发(dispatch)到同一向量单元上的两条向量指令之间需要一些恢复时间(recovery time)或死时间(dead time)图 F.13 展示了一条流水线的启动延迟和死时间。
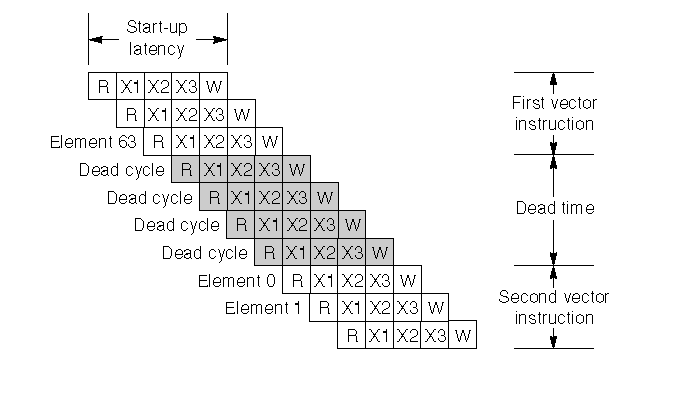
图 F.13 一条向量流水线的启动延迟和死时间。 每个元素操作有 5 个周期的延迟: 1 个周期去读向量寄存器文件, 3 个执行周期,然后一个周期写回寄存器文件。同一个向量指令中的元素可以连续在流水线中执行,但是这个机器在两个向量指令之间插入了 4 个周期的 dead time 。这个 dead time 可以利用更复杂的控制逻辑来减少。
下面的例子展示了死时间对于向量处理器性能的影响。
_____________________________________________________
例题:Cray C90 有两个 lane,但是在任何同一个功能单元上执行的两个向量指令之间需要 4 个周期的 dead time,即使他们之间没有数据依赖。对于最大向量长度为 128 的情形而言,由 dead time 导致的峰值性能的减少是多少?如果 lane的数目增加到 16,那性能折扣又是多少?
解答:最多 128 个元素被划分到 2 个道上,并且占据一个向量功能单元 64 个时钟周期。Dead time 另外增加了 4 个周期的占用,使得峰值性能降为没有 dead time 的 64/(64 + 4) = 94.1%。如果 lane 的数目增加为 16,那么 128 个元素占用一个功能单元的时间只需要 128/16 = 8 个周期,这样 dead time 会导致 8/(8 + 4) = 66.6% 的峰值性能降低。在第二种情况下,向量单元永远不会有超过 2/3 的忙碌时间。
_____________________________________________________
流水化指令的启动在多条指令可以读写同一个向量寄存器或者一些指令不可预期地停顿比如 load 指令遇到 bank conflict 的时候变得更复杂了。但是,因为lane 的数目和流水线的延迟增加了,现在完全流水化指令的启动时间变得越来越重要了。














 2361
2361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









