







1 .1在managed-schema文件夹中添加分词器。
现在Solr已经更新到了6.6,网上很多分词器出现不兼容的情况,在网站找到了半天的解决方案。看到一位大神,找到原因后更改源码,重新打包,放在/webapps/solr/WEB-INF/lib/ 下,感谢博主写了大段的文章阐述原因及代码分析。
附上大神博客:http://www.cnblogs.com/immortal-ghost/p/6954360.html
<!-- IKAnalyzer -->
<fieldType name="IK_cnAnalyzer" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false"/>
</analyzer>
</fieldType>
如下的分词效果:
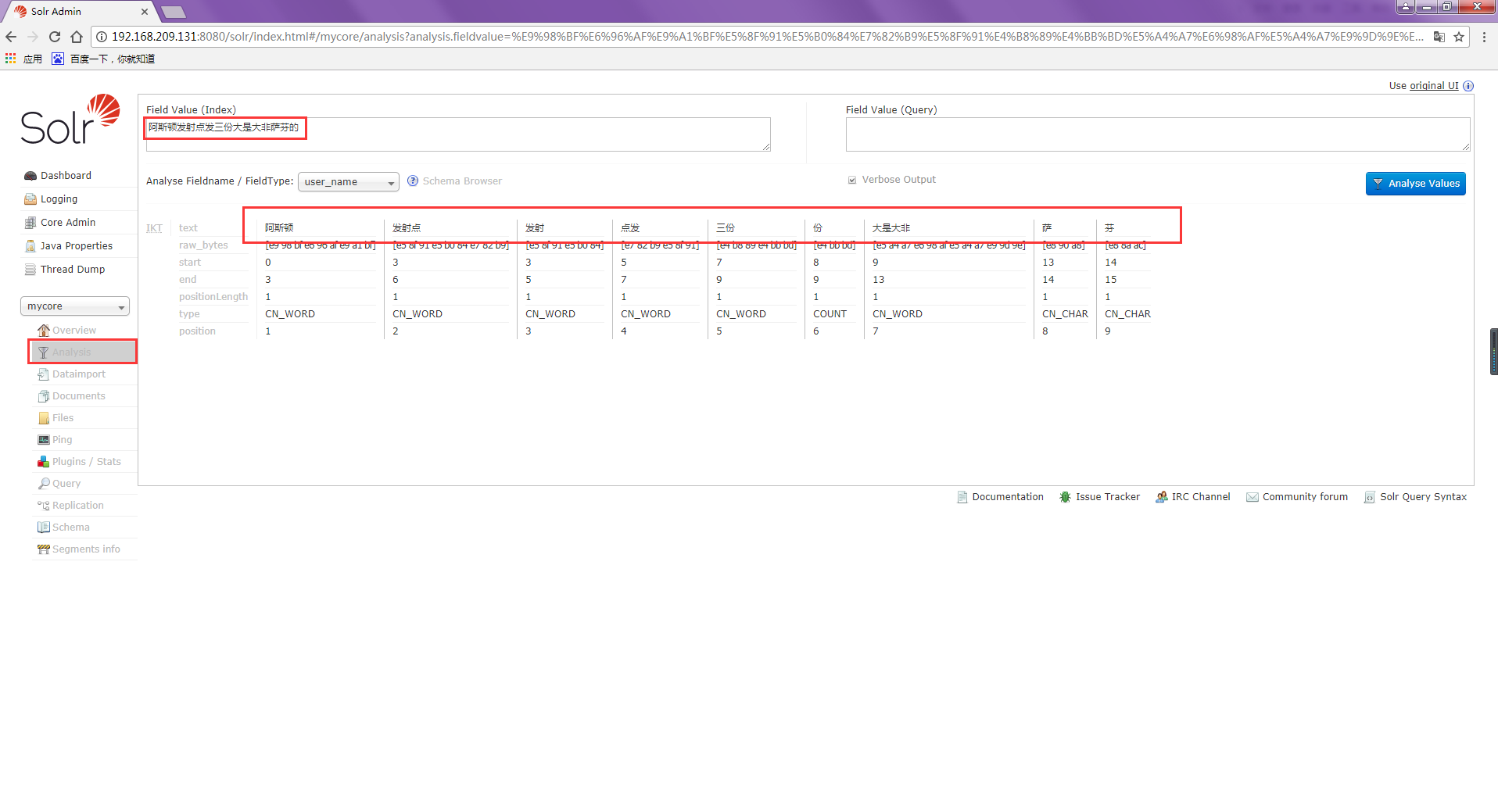
1.2 字段:
<field name="user_id" type="string" indexed="true" stored="true"/>
<field name="user_name" type="IK_cnAnalyzer" indexed="true" stored="true"/>
<field name="user_password" type="string" indexed="true" stored="true"/>
<!--default search field-->
<field name="item_keyword" type="IK_cnAnalyzer" indexed="true" stored="true" multiValued="true"/>
<copyField source="user_name" dest="item_keyword"/>
1.3 整合到Spring。
solr-solrj为5.5,有的版本可能不一样,会出现不支持的情况。
<bean id="solrClient" class="org.apache.solr.client.solrj.impl.HttpSolrClient">
<constructor-arg index="0" value="http://192.168.209.131:8080/solr/mycore"/>
</bean>
需要说明的是,注入的URL,应该是IP+端口号+solr运行在Tomcat中的项目名+数据仓库名称,Solr管理页面为:
http://192.168.209.131:8080/solr/index.html有点区别。
自动注入到需要使用的位置。
2 做的一个简单的搜索。
搜索Dao层,处理各种情况的搜索。
@Autowired
private SolrClient solrClient;
/**
* 搜索
*/
public List<User> search(SolrQuery solrQuery) {
// TODO Auto-generated method stub
List<User> lstUser=new ArrayList<User>();
try {
QueryResponse queryResponse=solrClient.query(solrQuery);
SolrDocumentList documentList=queryResponse.getResults();
System.out.println(documentList.getNumFound());//取查询结果总数量
//高亮部分单独分开了。
Map<String, Map<String, List<String>>> highlighting=queryResponse.getHighlighting();//高亮部分
for (SolrDocument solrDocument : documentList) {
User user=new User();
System.out.println(solrDocument.get("user_id"));
user.setId(Integer.parseInt(solrDocument.get("user_id").toString()));
//取高亮部分,
List<String> lstHigh=highlighting.get(solrDocument.get("id")).get("user_name");
String name="";
if(lstHigh!=null && lstHigh.size()>0){
name=lstHigh.get(0);
}else{
//无高亮
name=(String)solrDocument.get("user_name");
}
user.setName(name);
user.setPassword((String)solrDocument.get("user_password"));
lstUser.add(user);
}
} catch (SolrServerException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return lstUser;
}
调用处:
/**
* 搜索
* @param queryString
* @return
*/
public List<User> search(String queryString) {
// TODO Auto-generated method stub
SolrQuery solrQuery = new SolrQuery();
solrQuery.setQuery(queryString);
//solrQuery.setQuery("*:*");
solrQuery.setHighlight(true);
solrQuery.addHighlightField("user_name");// 设置高亮字段
solrQuery.setHighlightSimplePre("<em style=\"color:red\">");
solrQuery.setHighlightSimplePost("</em>");
//solrQuery.set("", "");
solrQuery.set("df", "item_keyword");// 设置默认
return searchService.search(solrQuery);
}
Controller:
@Autowired
private UserService userService;
@RequestMapping(value="/query",method=RequestMethod.GET)
@ResponseBody
public void search(HttpServletRequest request,
HttpServletResponse response, String queryString,
@RequestParam(defaultValue = "15") Integer rows,
@RequestParam(defaultValue = "1") Integer page) throws IOException {
List<User> lstUser=userService.search(queryString);
JSONArray jsonArray=new JSONArray();
JSONObject jsonObject=null;
for (User user : lstUser) {
jsonObject=new JSONObject();
jsonObject.put("id",user.getId());
jsonObject.put("name", user.getName());
jsonObject.put("password", user.getPassword());
jsonArray.add(jsonObject);
}
response.setContentType("text/html;charset=utf-8");
response.getWriter().print(jsonArray);
}
附出现的问题:
1 在配置了分词后,在分词界面中能成功的分词,但是在进行查询的时候却啥都不能查出来,就连全匹配都查不出来,各种查资料,差点都准备放弃这块的,突然发现数据是之前就已经存在了的,重新配置的字段类型配置的分词器是在数据导入后添加的。重新构建一下索引试试,果然,重构索引后能成功登顶分词并能查询出来。














 2165
2165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









