







githup地址:https://github.com/jbymy
一、简介
中文分词是地然语言处理中的最基础的环节,到目前为止已经有不少优秀的分词工具的出现,如“中科院分词”,“结巴分词”等。个人认为在中文分词领域在算法层面上虽层出不穷,但归其根本仍然是大同小异,基于统计的分词算法在根本上并无太大差别,因此我写的这个分词算法在保证高准确性的情况下以实用性,灵活性为主打方向。
二、wordseg分词算法
借鉴结巴分词的思想,采用基于词典的有向无环图算法结合HMM隐马尔科夫模型分词。关于结巴分词已经有非常成熟的版本了,本分词工具中的基础词典也是结巴分词的词典加上自己整理的新词。wordseg分词工具基本思路如下:
- 用TRIE树存储词典
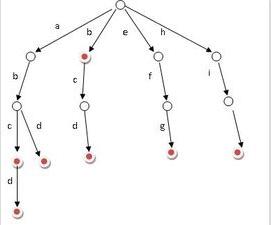
Trie树的详细描述详见维基百科,这里有一张百科截图
上图显示的是英文词典的Trie树,中文词典构成Trie数也和上图类似,只不过每一个节点存储的是每个中文汉字的编码(在linux下一般是UTF-8编码,每一个汉字用一个INT型变量表示,具体的转码方式参见UTF-8编码ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 312
312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









