







1.背景概述
业务上有一定的需求, 希望能实时地对从中间件进来的数据已经已有的维度表进行inner join, 以便后续的统计. 维表十分巨大, 有近3千万记录,约3G数据, 而集群的资源也较紧张, 因此希望尽可能压榨Spark Streaming的性能和吞吐量.
技术架构大致上如下述: 数据从Kafka流入, SparkStreaming 会从HDFS中拿到维度表的数据, 与流入的消息进行计算, 最后进行inner join, 计算结果会插入HBase.
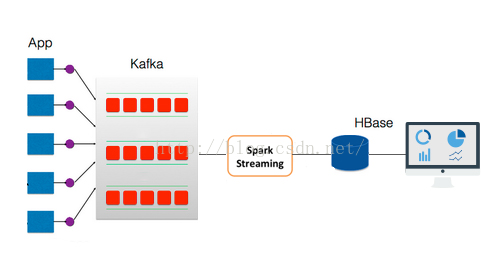
为什么选择Kafka去承担类似数据总线的角色呢,绝大部分是由于它简单的架构以及出色的吞吐量, 并且与Spark也有专门的集成模块. Kafka的出色吞吐量主要是来自于最大化利用系统缓存以及顺序读写所带来的优点, 同时offset和partition的涉及也提供了较好的容灾性.
为什么选择Spark作为流计算引擎呢,主要是由于Spark本身优雅的RDD设计让分布式编程更简单, 同时结合Spark的内存缓存层也使得计算更快,而Spark对各种技术的集成与支持, 能够使技术栈更简单和通用, 也是选用它的一个重要原因. 而Spark的DirectKafkaInputDStream也提供了简单有效的HA.

而对于HBase的选择,则更多的是出于历史原因吧,因为公司一直都有在用HBase.

然后, 硬件资源大概是开了6个计算节点(也就是executor),每个节点占3G内存和3个核, 包括主节点(也就是driver)在内, 整个spark应用占用的集群资源大概是18.5G内存和19个核. 噢, 对了, Kafka用于测试的topic有3个partition, 每个partition两个replication.
现在前面大概描述下测试结果吧, 一开始根本无法在1小时内跑完一个batch, 优化后可以达到每秒处理近6万条Kafka输入数据, 对6万*2千3百万数据(近3G)进行inner join. 与Storm稍微做了下对比, 从网上的资料”http://blog.linezing.com/?p=1048”可以看到Storm可以每秒处理3.5万数据, Spark Streaming则打到了它的近两倍吞吐量. 但需要说明的是, 网上使用的Storm版本不是最新的, 而且也没说明业务逻辑与是否有做优化, 因此只能大概作一些感性上的比较.
2.压之初体验
代码编写完后,不做任何优化, 全量数据压着玩玩, 由于一开始没打算记录这个过程, 所以第一次压测体验的数据木有记录, 估计也是从Kafka一次获得30多万条记录, 然后与HDFS上的3G多数据逐条进行转换后再进行inner join.
结果不大记得, 貌似跑了大半天吧, 同时在shuffle阶段内存严重不够用, 要把数据spill到磁盘进行shuffle.如果是自己的机子这样玩的话, 估计会很心疼吧.














 2136
2136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









