







1、阅读本文前,读者要对二叉树、贪心、优先队列等知识有一定了解。
2、此题比较坑,阅读之前请做好心理准备。
一、了解基本概念
1、二叉树、二叉树的构造方法、二叉树的各种遍历(不用说了吧....)
2、优先队列的使用方法
3、贪心思想、深搜算法,结构体的应用。。。
4、最优二叉树(哈夫曼树)的定义
在具有n个带权叶结点的二叉树中,使所有叶结点的带权路径长度之和(即二叉树的带权路径长度)
为最小的二叉树,称为最优二叉树(又称最优搜索树或哈夫曼树),即最优二叉树使
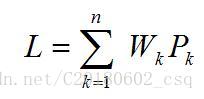
(Wk—第k个叶结点的权值;Pk—第k个叶结点的带权路径长度)达到最小。
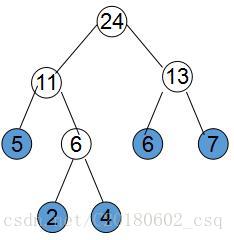
如图,图中为一棵最优二叉树
5、如何构造最优二叉树
可以从上图中看出,最优二叉树的构造方法就是:每次选两个权值最小的点,将它们合并成一个点,这个点就是原来的两点的父亲。
常规方法:
假定给出n个结点ki(i=1‥n),其权值分别为wi(i=1‥n)。要构造以此n个结点为叶结点的最优二叉树,其构造方法如下:
首先,将给定的n个结点构成n棵二叉树的集合F={T1,T2,……,Tn}。其中每棵二叉树Ti中只有一个权值为wi的根结点ki,其左、右子树均为空。然后做以下两步
⑴在F中选取根结点权值最小的两棵二叉树作为左右子树,构造一棵新的二叉树,并且置新的二叉树的根结点的权值为其左、右子树根结点的权值之和;
⑵在F中删除这两棵二叉树,同时将新得到的二叉树加入F中;
重复⑴、⑵,直到在F中只含有一棵二叉树为止。这棵二叉树便是最优二叉树。
以上构造最优二叉树的方法称为哈夫曼(huffmann)算法。
二、题目描述
哈夫曼编码
题目描述
输入N个整数表示N个叶节点权值,构造一棵最优二叉树,从左向右输出每个叶节点的哈夫曼编码。
输入
第1行:1个整数N(N≤50)第2行:N个空格分开的整数
输出
共N行,每行表示1个叶节点的编码。
样例输入
3
1 2 4
样例输出
00
01
1
三、题目分析
先来了解一下哈夫曼编码是如何产生的:
1、通过叶节点来构造一棵二叉树(就拿样例数据来说)
2、将非叶节点的左右两条边上的权值分别标记为0和1
3、每个叶节点的哈夫曼编码就是:从根节点到该节点的路径上的权值的顺序(不能颠倒)
4、注意,最优二叉树有可能有多种情况,比如:
6
1 2 3 4 5 6
情况1: 情况2: 情况3:
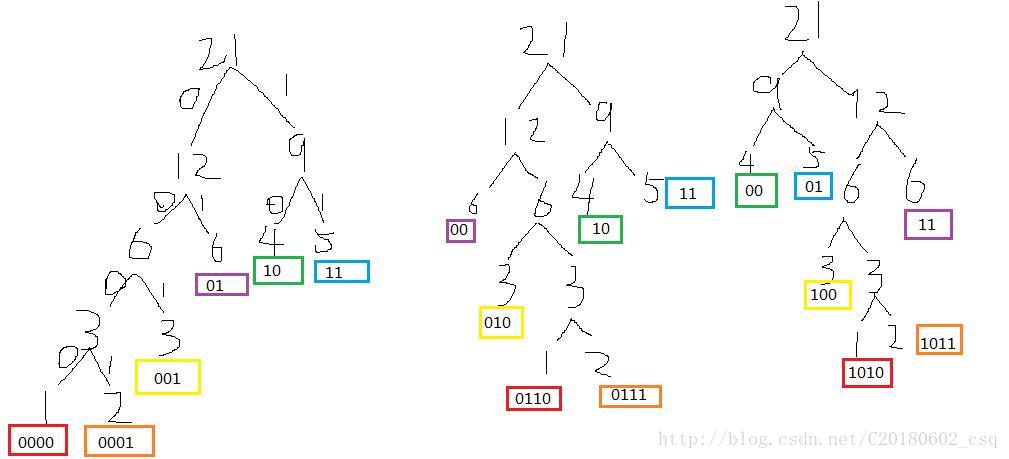
遇到这种情况,就输出其中的一种就可以了。
哈夫曼编码的应用:主要是战争时在电报上应用,因为有的字母常用,有的字母不常用,所以将常用的字母的电报信息变短一点,有助于提高发电报的速度。
这道题主要有两个难点:
1、如何生成最优二叉树
2、如何通过遍历来生成哈夫曼编码
先来看第一个问题,
通过之前讲的最优二叉树的构造方法,我们可以定义一个结构体tree,里面包含father,leftchild,rightchild,
再用一个优先队列将所有输入数据存入进去,因为优先队列会进行自动维护,所以只需要把前两个top元素拿出来
对它们进行建树操作,将它们的和push进优先队列。
再来看看第二个问题,
其实就是一个DFS(深搜),在深搜时顺便记录下结果,到了叶节点,就把结果输出就可以了。
附上代码(类似于合并果子)
#include<cstdio>
#include<queue>
#include<algorithm>
using namespace std;
priority_queue<int,vector<int>,greater<int> >h;
struct tree{
int fa,l,r;
}a[2505];
int ans[105],k;
void build(int x,int y)
{
int s=x+y;
a[s].l=x;
a[s].r=y;
a[x].fa=s;
a[y].fa=s;
}
void xxbl(int g)
{
if(g){
if(a[g].r==0&&a[g].l==0){
for(int i=1;i<=k;i++)
printf("%d",ans[i]);
printf("\n");
}
ans[++k]=0;
xxbl(a[g].l);
k--;
ans[++k]=1;
xxbl(a[g].r);k--;
ans[k]=0;
k--;
}
}
int main()
{
int i,x,n,y;
scanf("%d",&n);
for(i=1;i<=n;i++){
scanf("%d",&x);
h.push(x);
}
for(i=1;i<n;i++){
x=h.top();
h.pop();
y=h.top();
h.pop();
build(x,y);
h.push(x+y);
}
k=0;
xxbl(h.top());
}这段代码看起来是对的,实际上有一个很大的漏洞:当队列中有两个元素是相同时(即使输入数据不同,也有可能出现两个小数之和为一个大数),原来的tree数组中的数值会被覆盖,导致结果多输出或少输出,并且题目要求按照输入的顺序输出哈夫曼编码,所以应该把结果存入一个aans数组,而不是直接输出。
因为不会写结构体优先队列,所以就用了一个C函数来查找最小数,
代码:
#include<cstdio>
#include<cstring>
struct tree{
int fa,l,r,s;
}a[115];
int n,m,path[55],ans[105],o;
char aans[55][115];
int C(int i)
{
int j,k,min;
min=1<<29;
for(j=1;j<=i;j++)
if(a[j].fa==0&&a[j].s<min){
min=a[j].s;
k=j;
}
return k;
}
void build(int &root)
{
int i,j,k;
memset(a,0,sizeof(a));
scanf("%d",&n);
for(i=1;i<=n;i++)
scanf("%d",&a[i].s);
m=2*n-1;
for(i=n+1;i<=m;i++){
j=C(i-1);
a[j].fa=i;
k=C(i-1);
a[k].fa=i;
a[i].s=a[j].s+a[k].s;
a[i].l=j;
a[i].r=k;
}
root=m;
}
void xxbl(int g)
{
if(g){
if(a[g].r==0&&a[g].l==0){
for(int i=0;i<o;i++)
aans[g][i]=ans[i]+48;
}
ans[o]=0;
o++;
xxbl(a[g].l); //回溯部分,巨坑,写了2个多小时
o--;
ans[o]=1;
o++;
xxbl(a[g].r);
o--;
ans[o]=0;
}
}
int main()
{
int i,rt;
build(rt);
o=0;
xxbl(rt);
for(i=1;i<=n;i++)
printf("%s\n",aans[i]);
}













 3103
3103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









