









表
线性表的定义
线性表,从名字上来看,像线连起来的表。每个元素都是连起来的,比如在体育课按照老师定好的队列排队的时候,有一个打头,一个收尾,中间的每个人都知道前面是谁,后面是谁,就像一根线将他们联系在一起,就可以称之为线性表。
这时候我们来看几个关键点,首先元素之间是有顺序的,并且第一个元素无前驱,最后一个元素无后继,其他的元素都有且只有一个前驱和后继,这样才能形成线性表。
我们用数学语言来进行定义,若有线性表(a1,a2,….,ai-1,ai,ai+1,…,an),则称表中ai-1是ai的直接前驱元素,ai+1是ai的直接后继元素,a1没有直接前驱元素,an没有直接后继元素。线性表元素的个数定义为线性表的长度,当n=0时的特殊表我们称之为空表。
我们来举几个例子,每年的星座列表是不是线性表?当然是,因为星座以白羊打头,双鱼收尾,其中的都有且只有一个前驱和后继,所以完全符合线性表的条件。
那么公司的上下级关系是不是线性表?当然不是,因为一个上级会有很多个下级,每个人不只有一个后继和前驱,不符合线性表的条件。
前面我们明确定义了线性表的概念,与这些概念相关的是线性表应该具有的操作集合。
例如,向表中插入一个数据,或者获取表中的某个元素,删除某个元素,获取某个元素的直接前驱后继等操作,当然对于不同的应用,线性表应该有什么操作都是不同的,完全由程序设计者来决定,当然像增删查等必要的操作基本是每个线性表都需要具有的。
顺序存储结构
线性表的顺序存储结构,指的是用一段地址连续的存储单元依次存储线性表的数据元素。

说白了,就是在内存中找一块位置,把一定的内存空间占了,然后把相同数据类型的数据元素按顺序存放在这儿。说到这儿,我们可能有人会想起来,和数组怎么那么像呢?对,线性表的每个数据元素类型都相同,所以我们完全可以通过数组来实现线性表的顺序存储结构。
如果我们用数组来实现的话,我们就必须需要两个属性:线性表的长度,需要的数组长度。并且要保证线性表的长度要小于数组的长度,因为我们可能还需要执行插入操作。
java顺序结构线性表的实现
public class LinearList<T> {
/**
* 对象数组,用数组来存放线性表的数据
*/
protected Object[] element;
/**
* 线性表长度,记载元素个数
*/
protected int len;
/**
* 默认构造方法,创建默认容量的空表
*/
public LinearList() {
this(64);
}
/**
* 构造方法,创建容量为size的空表
*
* @param size
*/
public LinearList(int size) {
this.element = new Object[size];
this.len = 0;
}
/**
* 判断顺序表是否空,若空返回true,O(1)
*/
public boolean isEmpty() {
return this.len == 0;
}
/**
* 返回顺序表长度,O(1)
*/
public int length() {
return this.len;
}
/**
* 返回第i(≥0)个元素。若i<0或大于表长则返回null,O(1)
*/
public T get(int i) {
if (i >= 0 && i < this.len) {
return (T) this.element[i];
}
return null;
}
/**
* 设置第i(≥0)个元素值为x。若i<0或大于表长则抛出序号越界异常;若x==null,不操作
*/
public void set(int i, T x) {
if (x == null)
return;
if (i >= 0 && i < this.len) {
this.element[i] = x;
} else {
throw new IndexOutOfBoundsException(i + ""); // 抛出序号越界异常
}
}
/**
* 顺序表的插入操作 插入第i(≥0)个元素值为x。若x==null,不插入。 若i<0,插入x作为第0个元素;若i大于表长,插入x作为最后一个元素
* 思路:从最后一个元素往前遍历到第i个位置,分别将他们都往后移一位
*/
public void insert(int i, T x) {
if (x == null)
return;
// 若数组满了,则扩充数组容量
if (this.len == element.length) {
// temp也引用elements数组
Object[] temp = this.element;
// 重新申请一个双倍的数组
this.element = new Object[temp.length * 2];
// 复制数组元素,O(n)
for (int j = 0; j < temp.length; j++) {
this.element[j] = temp[j];
}
}
// 下标容错
if (i < 0)
i = 0;
if (i > this.len)
i = this.len;
// 元素后移,平均移动len/2
for (int j = this.len - 1; j >= i; j--) {
this.element[j + 1] = this.element[j];
}
this.element[i] = x;
this.len++;
}
/**
* 在顺序表最后插入x元素
*/
public void append(T x) {
insert(this.len, x);
}
/**
* 顺序表的删除操作 删除第i(≥0)个元素,返回被删除对象。若i<0或i大于表长,不删除,返回null。
* 思路:从删除元素的位置到最后遍历,每一个元素向前移一位
*/
public T remove(int i) {
if (this.len == 0 || i < 0 || i >= this.len) {
return null;
}
T old = (T) this.element[i];
// 元素前移,平均移动len/2
for (int j = i; j < this.len - 1; j++) {
this.element[j] = this.element[j + 1];
}
this.element[this.len - 1] = null;
this.len--;
return old;
}
/**
* 删除线性表所有元素
*/
public void removeAll() {
this.len = 0;
}
/**
* 查找,返回首次出现的关键字为key元素
*/
@SuppressWarnings("unchecked")
public T search(T key) {
int find = this.indexOf(key);
return find == -1 ? null : (T) this.element[find];
}
/**
* 顺序表比较相等 比较两个顺序表是否相等 ,覆盖Object类的equals(obj)方法,O(n)
*/
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj instanceof LinearList) {
LinearList<T> list = (LinearList<T>) obj;
// 比较实际长度的元素,而非数组容量
for (int i = 0; i < this.length(); i++) {
if (!this.get(i).equals(list.get(i))) {
return false;
}
}
return true;
}
return false;
}
// 返回顺序表所有元素的描述字符串,形式为“(,)”,覆盖Object类的toString()方法
public String toString() {
String str = "(";
if (this.len > 0)
str += this.element[0].toString();
for (int i = 1; i < this.len; i++)
str += ", " + this.element[i].toString();
return str + ") "; // 空表返回()
}
}
上面是我们实现的顺序结构存储的线性表,我们已经发现了插入和删除是最麻烦的,步骤最多,需要很多遍历,我们来分析一下这两个操作的时间复杂度。
如果要插入的或者删除的是最后一个元素,那么不需要移动任何元素,这时候为O(1).
如果要插入的或者删除的是第一个元素,那么所有元素都需要移动,这时候为O(n).
而当执行存储和查询的时候,时间复杂度都为O(1),这也间接的说明了一个问题,它比较适合元素个数不变化的存取操作,而插入和删除很不方便。
线性表顺序结构存储的优缺点
- 优点:可以快速的存取表中任意位置的数据
- 缺点:插入和删除需要移动元素,花费大量时间,并且当数组扩容时,难以确定存储空间的容量,容易造成存储空间的碎片化。
- -
链式存储结构
前面我们已经证明了,线性表的顺序存储结构有一个很大的缺点,就是插入和删除操作时需要消耗大量时间,能不能想个办法解决一下呢?
首先我们需要思考一下为什么会造成这个情况,仔细思考其实是因为两个相邻元素之间在内存中也是紧挨着的,如果要插入自然要向后移,否则会出现覆盖,要删除,后面的元素自然也要向前移。那么我们应该怎么解决这一情况呢?我们可不可以让逻辑上相邻的两个元素,在内存中其实不是相邻的,而只需前一个元素知道后一个元素的地址,然后连起来就行了?对,这就是我们要讲的链式存储结构。
通常讲采用链式存储结构的线性表称为线性链表,从链接方式来看,链表可分为单链表、循环链表和双链表。从实现角度来看,链表分为动态链表和静态链表。
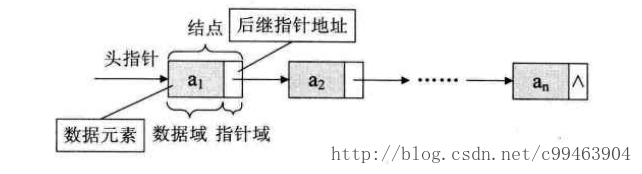
链表用一组任意的存储单元来存储线性表的元素,这组存储单元可以连续也可以不连续,所以现在每个元素中除了要存储数据,还要存储其后继元素的存储地址。我们把存储数据元素信息的域称为数据域,把存储后继元素位置的域称为指针域,这两部分共同组成一个数据元素单元,我们把它叫做结点(Node)。
单链表
每个结点中的指针域只包含下一个结点的位置,叫做单链表。单链表的最后一个结点指向为null。
单链表的java实现
首先,我们要实现一个结点类Node
public class Node<T> {
/**
* 数据域,保存数据元素
*/
public T data;
/**
* 地址域,引用后继结点
*/
public Node<T> next;
/**
* 构造节点
*/
public Node() {
this(null, null);
}
/**
* 构造结点,data指定数据元素,next指定后继结点
*
* @param data
* @param next
*/
public Node(T data, Node<T> next) {
this.data = data;
this.next = next;
}
/**
* 返回结点元素值对应的字符串
*/
public String toString() {
return this.data.toString();
}
}public class SingleLinkedList<T> {
/**
* 指定头结点
*/
public Node<T> head;
/**
* 默认构造方法,构造空单链表
*/
public SingleLinkedList() {
// 创建头结点,data和next值均为null
this.head = new Node<T>();
}
/**
* 由指定数组中的多个对象构造单链表。采用尾插入构造单链表
* 头插入就是每次新的结点在前面,例如第一个结点在头结点的前面,以此类推
* 头插入不太符合我们逻辑,所以尾插入,生成的结点在后面
*
* 若element==null,Java将抛出空对象异常;若element.length==0,构造空链表
* 思路:让一个结点指向最后一个结点,刚开始就一个头结点,然后循环遍历数组,将最后一个结点的地址域设置为数组的元素
*
* @param element
*/
public SingleLinkedList(T[] element) {
// 创建空单链表,只有头结点
this();
// last指向单链表最后一个结点
Node<T> last = this.head;
for (int i = 0; i < element.length; i++) {
last.next = new Node<T>(element[i], null);
last = last.next;
}
}
/**
* 判断单链表是否空,O(1)
* 判断头节点的地址域是否为空即可
*/
public boolean isEmpty() {
return this.head.next == null;
}
/**
* 返回单链表长度,O(n), 基于单链表遍历算法
* 数组中长度定义时就确定,单链表就必须得从头开始向后计数
*/
public int length() {
//定义i用来计数
int i = 0;
// p从单链表第一个结点开始
Node<T> p = this.head.next;
// 若单链表未结束
while (p != null) {
i++;
// p到达后继结点
p = p.next;
}
return i;
}
/**
* 获得第i(≥0)个元素,若i<0或大于表长则返回null,O(n)
*/
public T get(int i) {
if (i >= 0) {
//定义一个头结点,从头开始查找
Node<T> p = this.head.next;
//如果j在跳出循环时不为空,说明i处元素存在,否则说明元素不存在
for (int j = 0; p != null && j < i; j++) {
p = p.next;
}
// p指向第i个结点
if (p != null) {
return p.data;
}
}
return null;
}
/**
* 设置第i(≥0)个元素值为x。若i<0或大于表长则抛出序号越界异常;若x==null,不操作。O(n)
*/
public void set(int i, T x) {
if (x == null)
return;
//还是从头结点开始
Node<T> p = this.head.next;
for (int j = 0; p != null && j < i; j++) {
p = p.next;
}
//如果插入的位置>0,并且循环后的p不为null,则赋值给这个结点
if (i >= 0 && p != null) {
p.data = x;
} else {
throw new IndexOutOfBoundsException(i + "");
}
}
/**
* 插入第i(≥0)个元素值为x。若x==null,不插入。 若i<0,插入x作为第0个元素;若i大于表长,插入x作为最后一个元素。O(n)
* 初始化从第一个结点开始,当j<i时遍历节点,若到末尾结点为空,说明第i个元素不存在
* 如果存在,就创建一个新结点,然后相互赋值即可
*/
public void insert(int i, T x) {
// 不能插入空对象
if (x == null) {
return;
}
// p指向头结点
Node<T> p = this.head;
// 寻找插入位置
for (int j = 0; p.next != null && j < i; j++) {
// 循环停止时,p指向第i-1结点或最后一个结点
p = p.next;
}
// 插入x作为p结点的后继结点,如果i<0,则p还是为头结点,所以是在最前面插入
//如果i>链表长度,则p指向最后一个元素,所以是插入到最后
p.next = new Node<T>(x, p.next);
}
/**
* 在单链表最后添加x对象,O(n)
* 直接定义一个比较大的数,然后插入的时候会遍历,当结点为空时说明是最后,然后跳出循环
* 直接插入到最后
*/
public void append(T x) {
insert(Integer.MAX_VALUE, x);
}
/**
* 删除第i(≥0)个元素,返回被删除对象。若i<0或i大于表长,不删除,返回null。O(n)
* 思路:从头结点开始遍历,如果遍历结束,结点为空,则说明第i个元素不存在,否则就查找成功
* 然后将删除元素的地址域赋值给前一个元素即可,然后返回删除元素的数据
*/
public T remove(int i) {
if (i >= 0) {
Node<T> p = this.head;
for (int j = 0; p.next != null && j < i; j++) {
//因为我们是从链表元素是从0开始,所以p并不是我们要删除的元素,p的下一个才是
p = p.next;
}
if (p != null) {
// 获得原对象
T old = p.next.data;
// 删除p的后继结点
p.next = p.next.next;
return old;
}
}
return null;
}
/**
* 删除单链表所有元素 Java将自动收回各结点所占用的内存空间
* 我们只需要将头结点设为null,其他的jvm会帮我们回收垃圾
*/
public void removeAll() {
this.head.next = null;
}
/**
* 顺序查找关键字为key元素,返回首次出现的元素,若查找不成功返回null
* key可以只包含关键字数据项,由T类的equals()方法提供比较对象相等的依据
*/
public T search(T key) {
if (key == null)
return null;
for (Node<T> p = this.head.next; p != null; p = p.next){
if (p.data.equals(key))
return p.data;
}
return null;
}
/**
* 返回单链表所有元素的描述字符串,形式为“(,)”,覆盖Object类的toString()方法,O(n)
*/
public String toString() {
String str = "(";
for (Node<T> p = this.head.next; p != null; p = p.next) {
str += p.data.toString();
if (p.next != null)
str += ","; // 不是最后一个结点时后加分隔符
}
return str + ")"; // 空表返回()
}
/**
* 比较两条单链表是否相等
*/
public boolean equals(Object obj) {
if (obj == this)
return true;
if (obj instanceof SingleLinkedList) {
SingleLinkedList<T> list = (SingleLinkedList<T>) obj;
return equals(this.head.next, list.head.next);
}
return false;
}
/**
* 比较两条单链表是否相等,递归方法
*
* @param p
* @param q
* @return
*/
private boolean equals(Node<T> p, Node<T> q) {
return p == null && q == null || p != null && q != null
&& p.data.equals(q.data) && equals(p.next, q.next);
}
}单链表的优缺点
通过代码的编写,我们发现单链表的查找方法时间复杂度为O(n),而插入和删除为O(1)
优点:执行插入和删除效率高,不需要事先分配空间,元素个数不受限制,不会浪费空间
缺点:查找效率比较低
我们可以得出一些结论,若线性表需要频繁查找,很少进行插入和删除操作时,则使用顺序存储结构。反之,需要大量的插入和删除时,则使用链式存储结构。
循环链表
循环链表是一个首尾相连的链表,将单链表最后一个结点的地址域改为指向表头结点,就得到了单链循环链表,称为循环单链表。
循环单链表和单链表的主要差异就在循环的判断条件上,单链表判断循环结束是看地址域是否为空,而循环单链表则是判断地址域是否是头结点。在前面的单链表中,我们总是用一头结点来指向我们的第一个数据元素,这样非常方便。在单链表中,我们有了头结点,可以很快的访问到第一个元素,访问最后一个元素却需要O(n),循环链表就可以解决这个问题,使访问第一个元素和最后一个元素都是O(1),怎么实现呢?再添加一个指向尾部的结点。
循环单链表的实现
public class CircleSingleLinkedList<T> {
/**
* 头指针,指向循环单链表的头结点
* 尾指针,指向循环单链表的最后一个结点
*/
public Node<T> head;
public Node<T> tail;
/**
* 默认构造方法,构造空循环单链表
* 即让自己指向自己
* 然后让尾指针指向最后一个结点,此时也是指向头结点
*/
public CircleSingleLinkedList() {
this.head = new Node<T>();
this.head.next = this.head;
this.tail=new Node<T>();
this.tail.next=this.head;
}
/**
* 判断循环单链表是否空
* 判断头结点的地址域是不是自己即可
*/
public boolean isEmpty() {
return this.head.next == this.head;
}
/**
* 返回循环单链表长度,单链表遍历算法,O(n)
* 注意我们说的判断条件的区别
*/
public int length() {
int i = 0;
for (Node<T> p = this.head.next; p != this.head; p = p.next) {
i++;
}
return i;
}
/**
* 返回第i(≥0)个元素,若i<0或大于表长则返回null,O(n)
*/
public T get(int i) {
if (i >= 0) {
Node<T> p = this.head.next;
for (int j = 0; p != this.head && j < i; j++)
p = p.next;
if (p != this.head)
return p.data; // p指向第i个结点
}
return null;
}
/**
* 设置第i(≥0)个元素值为x。若i<0或大于表长则抛出序号越界异常;若x==null,不操作。O(n)
*/
public void set(int i, T x) {
// 不能设置空对象
if (x == null)
return;
Node<T> p = this.head.next;
for (int j = 0; p != this.head && j < i; j++)
p = p.next;
// p指向第i个结点
if (i >= 0 && p != this.head)
p.data = x;
else
throw new IndexOutOfBoundsException(i + ""); // 抛出序号越界异常
}
public void insert(int i, T x) {
// 不能插入空对象
if (x == null)
return;
// p指向头结点
Node<T> p = this.head;
// 寻找插入位置
for (int j = 0; p.next != this.head && j < i; j++) {
// 循环停止时,p指向第i-1结点或最后一个结点
p = p.next;
}
// 插入x作为p结点的后继结点,包括头插入(i<=0)、中间/尾插入(i>0)
p.next = new Node<T>(x, p.next);
//每插入一个都要保证尾结点指向最后一个元素
this.tail.next=p.next;
}
public void append(T x) {
insert(Integer.MAX_VALUE, x);
}
/**
* 删除第i(≥0)个元素,返回被删除对象。若i<0或i大于表长,不删除,返回null。O(n)
*/
public T remove(int i) {
if (i >= 0) {
Node<T> p = this.head;
for (int j = 0; p.next != this.head && j < i; j++) {
p = p.next;
}
if (p != null) {
// 获得原对象
T old = p.next.data;
// 删除p的后继结点
p.next = p.next.next;
return old;
}
}
return null;
}
/**
* 删除单链表所有元素 Java将自动收回各结点所占用的内存空间
*/
public void removeAll() {
this.head.next = this.head;
}
/**
* 顺序查找关键字为key元素,返回首次出现的元素,若查找不成功返回null
* key可以只包含关键字数据项,由T类的equals()方法提供比较对象相等的依据
*/
public T search(T key) {
if (key == null)
return null;
for (Node<T> p = this.head.next; p != this.head; p = p.next)
if (p.data.equals(key))
return p.data;
return null;
}
/**
* 返回循环单链表所有元素的描述字符串
*/
public String toString() {
String str = "(";
Node<T> p = this.head.next;
// 遍历单链表的循环条件改变了
while (p != this.head) {
str += p.data.toString();
if (p != this.head)
str += ", "; // 不是最后一个结点时后加分隔符
p = p.next;
}
return str + ")";
}
/**
* 比较两条单链表是否相等
*/
@SuppressWarnings("unchecked")
public boolean equals(Object obj) {
if (obj == this)
return true;
if (obj instanceof CircleSingleLinkedList) {
CircleSingleLinkedList<T> list = (CircleSingleLinkedList<T>) obj;
return equals(this.head.next, list.head.next);
}
return false;
}
/**
* 比较两条单链表是否相等,递归方法
*
* @param p
* @param q
* @return
*/
private boolean equals(Node<T> p, Node<T> q) {
return p == null && q == null || p != null && q != null
&& p.data.equals(q.data) && equals(p.next, q.next);
}
//合并两条循环单链表
/*有了尾结点这个工作将变得无比轻松,我们只需要让A链表的尾部指向B链表的第一个结点(不是头结点)
然后让B链表的尾结点指向A链表的头结点即可
*/
public void merge(CircleSingleLinkedList t) {
Node <T> n=this.tail.next.next;
this.tail.next.next=t.tail.next.next.next;
t.tail.next.next=n;
}
}双向链表
我们在单链表中如果要查找上一个结点的话,那就得从头开始循环了,最坏的时间复杂度就是O(n),
你会想这也太麻烦了,我能不能像next直接查找下一个结点一样,设计链表可以直接查找上一个结点呢?当然可以,为了克服上述问题,前辈们设计了双向链表。
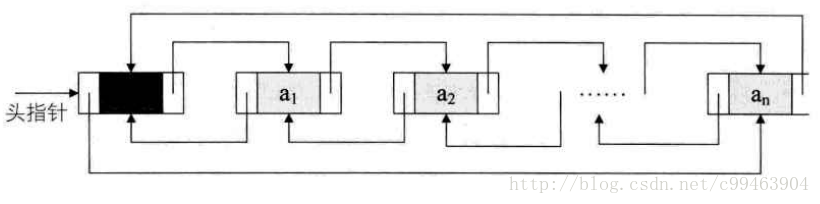
双向链表:就是在单链表的每个结点中,再设置一个指向其前驱结点的指针域。所以在双向链表中的每个结点都有两个指针域,一个指向直接后继,一个指向直接前驱。
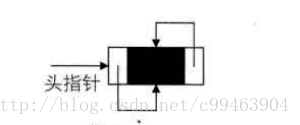
既然单链表可以有循环链表,那么双向链表当然也可以循环。
双向循环链表为空时
双向循环链表不为空时
双向循环链表的实现
//先创建一个指向前驱和后继结点的结点对象
public class DLinkNode<T> {
public T data;
/**
* pred指向前驱结点,next指向后继结点
*/
public DLinkNode<T> pred;
public DLinkNode<T> next;
/**
* 构造节点,data指定元素,pred指向前驱节点,next指向后继节点
*/
public DLinkNode(T data, DLinkNode<T> pred, DLinkNode<T> next) {
this.data = data;
this.pred = pred;
this.next = next;
}
/**
* 默认构造器
*/
public DLinkNode() {
this(null, null, null);
}
}//实现双向循环链表
public class CircleDoubleLinkedList<T> {
//头结点
public DLinkNode<T> head;
//默认构造方法
public CircleDoubleLinkedList() {
this.head=new DLinkNode<T>();
this.head.pred=this.head;
this.head.next=this.head;
}
//将数组构造成循环双链表
public CircleDoubleLinkedList(T[] element) {
this();
//rear指向最后的结点
DLinkNode<T> rear=this.head;
for(int i=0;i<element.length;i++) {
rear.next=new DLinkNode<T>(element[i],rear,this.head);
rear=rear.next;
}
//将头结点的直接前驱结点设置为最后一个结点
this.head.pred=rear;
}
public boolean isEmpty() {
return this.head.next == this.head;
}
/**
* 获取链表的长度
*/
public int length() {
int i = 0;
for (DLinkNode<T> p = this.head.next; p != this.head; p = p.next) {
i++;
}
return i;
}
/**
* 返回第i(≥0)个元素,若i<0或大于表长则返回null,
*/
public T get(int i) {
if (i >= 0) {
DLinkNode<T> p = this.head.next;
for (int j = 0; p != this.head && j < i; j++) {
p = p.next;
}
// p指向第i个结点
if (p != null) {
return p.data;
}
}
return null;
}
/**
* 设置第i(≥0)个元素值为x。若i<0或大于表长则抛出序号越界异常;若x==null,不操作。O(n)
*/
public void set(int i, T x) {
if (x == null)
return;
DLinkNode<T> p = this.head.next;
for (int j = 0; p != this.head && j < i; j++) {
p = p.next;
}
// p指向第i个结点
if (i >= 0 && p != null) {
p.data = x;
} else {
throw new IndexOutOfBoundsException(i + "");
}
}
/**
* 插入第i(≥0)个元素值为x。若x==null,不插入。 若i<0,插入x作为第0个元素;若i大于表长,插入x作为最后一个元素。O(n)
*/
public void insert(int i, T x) {
if (x == null)
return;
DLinkNode<T> p = this.head;
// 寻找插入位置 循环停止时,p指向第i-1个结点
for (int j = 0; p.next != this.head && j < i; j++) {
p = p.next;
}
// 插入在p结点之后,包括头插入、中间插入
DLinkNode<T> q = new DLinkNode<T>(x, p, p.next);
p.next.pred = q;
p.next = q;
}
/**
* 在循环双链表最后添加结点,O(1)
*/
public void append(T x) {
if (x == null)
return;
// 插入在头结点之前,相当于尾插入
DLinkNode<T> q = new DLinkNode<T>(x, head.pred, head);
head.pred.next = q;
head.pred = q;
}
/**
* 删除第i(≥0)个元素,返回被删除对象。若i<0或i大于表长,不删除,返回null。O(n)
*/
public T remove(int i) {
if (i >= 0) {
DLinkNode<T> p = this.head.next;
// 定位到待删除结点
for (int j = 0; p != this.head && j < i; j++) {
p = p.next;
}
if (p != head) {
// 获得原对象
T old = p.data;
// 删除p结点自己
p.pred.next = p.next;
p.next.pred = p.pred;
return old;
}
}
return null;
}
/**
* 删除循环双链表所有元素
*/
public void removeAll() {
this.head.pred = this.head;
this.head.next = this.head;
}
/**
* 顺序查找关键字为key元素,返回首次出现的元素,若查找不成功返回null
* key可以只包含关键字数据项,由T类的equals()方法提供比较对象相等的依据
*/
public T search(T key) {
if (key == null)
return null;
for (DLinkNode<T> p = this.head.next; p != this.head; p = p.next)
if (key.equals(p.data))
return p.data;
return null;
}
/**
* 返回循环双链表所有元素的描述字符串,循环双链表遍历算法,O(n)
*/
public String toString() {
String str = "(";
for (DLinkNode<T> p = this.head.next; p != this.head; p = p.next) {
str += p.data.toString();
if (p.next != this.head)
str += ",";
}
return str + ")"; // 空表返回()
}
/**
* 比较两条循环双链表是否相等,覆盖Object类的equals(obj)方法
*/
@SuppressWarnings("unchecked")
public boolean equals(Object obj) {
if (obj == this)
return true;
if (!(obj instanceof CircleDoubleLinkedList))
return false;
DLinkNode<T> p = this.head.next;
CircleDoubleLinkedList<T> list = (CircleDoubleLinkedList<T>) obj;
DLinkNode<T> q = list.head.next;
while (p != head && q != list.head && p.data.equals(q.data)) {
p = p.next;
q = q.next;
}
return p == head && q == list.head;
}
}
双向循环链表就是典型的用空间换时间。
JAVA API中的表实现
JAVA的类库中,包含着很多数据结构的实现,设计的很精妙,所以说JDK源码就是我们非常好的学习工具。Collection接口中有很多使用我们数据结构来实现的集合类,我们今天就来看看集合中的那些表实现。
Collecation接口中定义了很多集合类中应该有的方法,并且实现了Iterable接口,实现Iterable接口的类可以使用增强for循环。
实现Iterable接口的集合必须提供Iterator方法,该方法返回一个Iterator对象,Iterator也是java.util包中的一个接口,Iterator接口主要是为了遍历集合,将当前的位置在对象内部存储起来,然后就可以进行遍历。当一个增强for循环在循环一个实现Iterable接口的对象时,其实增强for循环内部就是使用的Iterator对象在进行遍历。
好了,说了这么多,我们扯得有点远,我们这次最大的目的是来看看jdk中的表实现,它由java.util包中的List接口指定,它下面有很多实现类,例如ArrayList类就是顺序结构线性表的实现,存取指定位置元素比较方便,而插入和删除效率就很低。LinkedList类则是双链表的实现,存取指定位置元素效率比较低,而插入和删除的效率则高于ArrayList。
尽管前面我们已经知道了顺序结构线性表和链表的差别,这里我们再来看一下ArrayList和LinkedList的差别。
不论是对于ArrayList还是LinkedList而言,在后端添加N个元素的操作运行时间都是O(n).
如果从集合前面添加N个元素的话,,LinkedList的运行时间是O(n),而ArrayList每添加一个就是O(n),添加n个则是O(n^2)
对于通过get()计算集合中n个数的和的方法,ArrayList的运行时间是O(n),LinkedList则为O(n^2),但是如果使用迭代器的话,那么任意的List集合运行时间都是O(n),因为迭代器会记录当前
位置。
小例子:remove方法对LinkedList的使用
我们来做一个例子,将一个表中的所有偶数都删除,我们当然不可能使用ArrayList,因为每次操作都是O(n),所以我们要使用LinkedList..
我们先来一种我们正常思考的算法。
public void removeEven(LinkedList<Integer> lst) {
int i=0;
while(i<lst.size()) {
if(lst.get(i)%2==0) {
lst.remove(i);
}
i++;
}
}
上面是我们最经常想到的方法,但是也暴露出了两个问题,首先LinkedList的get的效率是很低的,为O(n),并且remove方法效率也很低,也是O(n)。所以整个方法的时间为O(n^2) 怎么解决这两个问题呢?我们用我们前面提到的迭代器。
public void removeEven(LinkedList<Integer> lst) {
Iterator<Integer> i=lst.iterator();
while(i.hasNext()) {
if(i.next()%2==0) {
i.remove();
}
}
}
使用迭代器的话,删除只需要花费常数时间,因为迭代器就在删除元素这里,所以整个函数只需要O(n)的时间,效率大大提高。
ArrayList的实现
我们前面实现的顺序结构存储的线性表其实就是ArrayList的内部实现,如果有什么模糊的地方可以去前面看看源代码,这里我们来实现点更接近ArrayList的功能,那就是迭代器。
我们先来编写一个迭代器
public class LinearListIterator<T> implements Iterator<T> {
private int current=0;
private LinearList<T> linearList;
public LinearListIterator(LinearList<T> linearList) {
this.linearList=linearList;
}
//判断当前项有没有大于表的长度
@Override
public boolean hasNext() {
return current<linearList.len;
}
//返回当前项,并加1记录当前位置
@Override
public T next() {
return (T) linearList.element[current++];
}
}
我们自己编写的ArrayList必须实现Iterable接口,然后实现他的方法,返回一个迭代器对象
@Override
public Iterator<T> iterator() {
return new LinearListIterator(this);
}我们测试一下我们的迭代器
public static void main(String[] args) {
LinearList<Integer> l=new LinearList<Integer>();
l.append(1);
l.append(2);
l.append(3);
l.append(4);
l.append(5);
LinearListIterator<Integer> iterator=(LinearListIterator<Integer>) l.iterator();
//可以正常输出
while(iterator.hasNext()) {
System.out.println(iterator.next());
}
} 当然ArrayList内部采用的是内部类来实现迭代器,这样有一个很明显的优点就是可以直接操作当前的集合对象,而不用别人再来传递,并且可以获得当前集合的所有属性来操作。
LinkedList的实现
JDK中的LinkedList是一个双向链表,并且没有循环。我们前面也实现了,具体可以看看前面的代码。
至于LinkedList迭代器的实现,我想大家有了前面的基础,会很容易的实现。














 205
205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









