






本文为 1 月 4 日,腾讯 AI Lab 高级研究员——涂兆鹏在第 22 期 PhD Talk 中的直播分享实录。
机器翻译是自然语言处理的经典任务之一,涉及到自然语言处理的两个基本问题:语言理解和语言生成。这两个问题的建模直接对应译文的两个评价指标:忠实度(是否表达原文的完整意思)和流利度(译文是否流畅)。
近几年来,神经网络机器翻译取得了巨大进展,成为了主流模型。神经网络由于能缓解数据稀疏性及捕获词语之间的关联,生成的译文流利度高,这是过去二十余年上一代统计机器翻译一直以来的难点。但由于神经网络目前来说仍然是个黑盒子,无法保证原文的语义完整传递到目标端,导致经常出现漏翻、错翻等忠实度问题。
本次报告主要讲述过去一年我们在提高神经网络翻译忠实度方向上的系列研究工作,从利用句法结构、扩大翻译粒度、引入篇章信息、忠实度学习方面加强模型对原文的理解。
class="video_iframe" data-vidtype="2" allowfullscreen="" frameborder="0" data-ratio="1.588235294117647" data-w="432" data-src="http://v.qq.com/iframe/player.html?vid=i05393bdj9i&width=638&height=358.875&auto=0" style="display: block; width: 638px !important; height: 358.875px !important;" width="638" height="358.875" data-vh="358.875" data-vw="638" src="http://v.qq.com/iframe/player.html?vid=i05393bdj9i&width=638&height=358.875&auto=0"/>
△ Talk 实录回放
翻译其实是自然语言处理中的经典任务,早在 1949 年就有学者提出了一种翻译备忘录。虽然当时翻译系统本身没有被实现,但是提出的“编码解码”的思想被广泛地应用于后续的机器翻译研究中。
翻译是自然语言处理中的一个基本任务,有人曾说翻译是自然语言处理皇冠上的明珠,当翻译问题被解决的时候,自然语言处理的大部分问题也就被解决了。
当然在其他领域诸如对话系统、句法分析等研究中也会有类似的说法,但毫无疑问翻译是其中比较明亮的一颗。因为翻译涉及了语言的理解和生成,需要理解原文的意思,并在此基础上生成译文。
在人工智能的大领域中,翻译也是一个比较合适的任务,因为相对于对话系统等而言,翻译的任务难度相对适中。
首先,它可以被认为是一种有监督的学习,因为原文的存在,我们只需要做到完整地将原文信息传递到译文中,有这样的监督信号使得质量得到一定保证; 其次,它有比较充足的语料,很多开源的数据和系统都到达了千万级别;最后,它有比较好的评价机制,虽然一直被人诟病,但在整个翻译体系中仍旧是一个比较可靠的评价指标。
这三个优势使得翻译比较常被用于测试一些模型算法,可以看到近期深度学习在自然语言处理中的应用也经常使用翻译作为主要的任务。
综上所述,翻译是一个综合的、有意思的且难度适中的任务 。因此我们也在翻译任务上关注了很久 。
发展历程

严复在《天演论》中提出翻译有三个难点:信、达、雅。信,是指准确地将原文意思翻译出来,不增不减;达,是指译文流畅、自然;雅,是需要有古风。
比如严复的《天演论》是对达尔文《进化论》的翻译,他将这本书的思想总结为八个字“物竞天择,适者生存”,这其实是“信、达、雅”的典范。
但是在实际翻译中,即使是专业人员也很难达到“雅”,因此更多地我们只追求“信”和“达”,也就是说能准确、流畅地传达原文意思。
严复还提到“求其信已大难矣,顾信矣不达,虽译犹不译也,则达尚焉”,就是说翻译能够忠实原文已经很难了,有时候为了忠实原文使得译文不流畅,这样翻译了也犹如没有翻译,所以还是流畅地翻译更加重要。
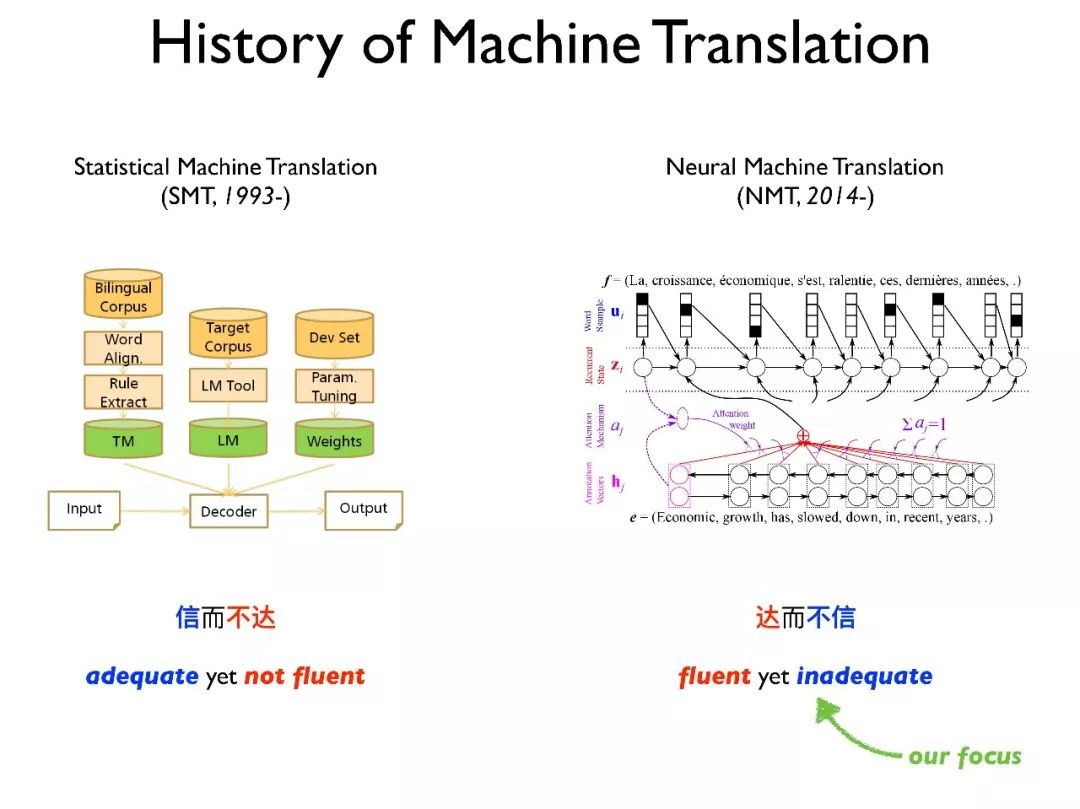
严复提出的这些理论和现代机器翻译发展的趋势密切相关。在 1993 年由 IBM 提出的 IBM 模型揭开了机器翻译的篇章,这个模型也是统计机器翻译的基石。
统计机器翻译的特点是“信而不达”(adequate yet not fluent)。以前的谷歌翻译和百度翻译都采用这种方式,其翻译的效果比较机械,虽然能基本翻译原文的意思,但不够流畅更。
在过去 20 年,如何提高翻译的流畅性一直是统计机器翻译的难点,包括如何更好地集成语言模型以及引入句法知识。
2014 年,神经网络机器翻译的概念被提出来,它用一个很大的神经网络去完整建模整个过程。由于神经网络可以捕获词的语义相关性,同时克服词的稀疏性,因此其能生成比较流畅的译文。
但由于其黑盒的特征使得很难保证其能够忠实原文的意思,因此神经网络机器翻译的特点是“达而不信”(fluent yet inadequate),经常会出现漏翻和翻飞的现象。因此,我们的关注点也就是如何提高神经网络机器翻译的忠实度。
工作概览

在最初的时候,我们先做了一些比较基础的尝试。因为当时神经网络机器翻译模型还处于比较初级的阶段,所以我们在编码端引入了覆盖率机制,使得模型更加关注于未被翻译的地方。
而后,我们又引入了一种“context gate”,使得原文的意思能够更有效地传递到目标端。最后,我们提出了更好的训练目标使得解码端能更忠实原文意思。可以看出这三个工作是比较基础、粗犷的改进方式。
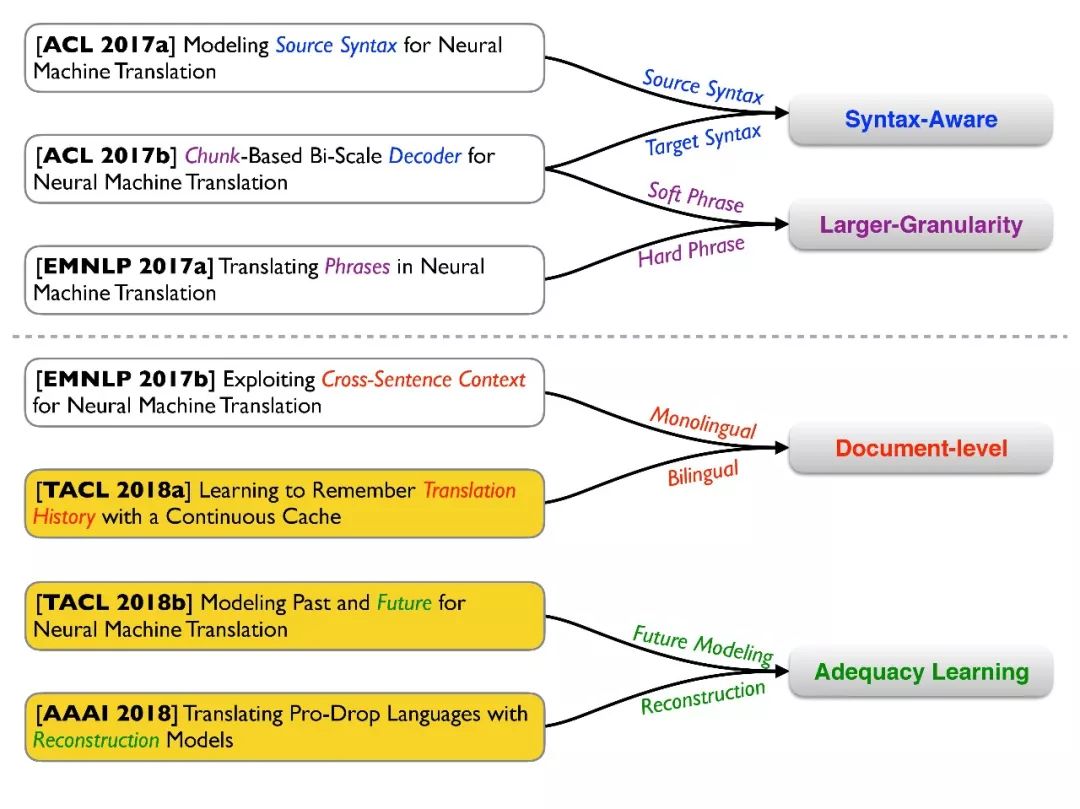
在过去一年里,我们提出了一些更深入的改进方式,借助了统计机器翻译中的一些经验。
首先,我们想引入句法信息,比如在 ACL2017 上的两篇文章,我们分别把源端和目标端的句法信息引入,使其能够更好地理解原文和生成译文。其次,我们提出了短语级别的翻译。
短语是统计机器翻译的基础,我们希望将短语也引入神经机器翻译,比如在模型结构上引入类似于短语的操作(Soft Phrase)或者是直接将统计机器翻译中的短语表引入(Hard Phrase)。
同时,我们也关注文档级别的翻译。文档级别的翻译是机器翻译的经典任务,也具有较强的实用价值。相对于句子级别的翻译,文档级别的翻译存在一些特殊的问题,比如需要满足句子间的一致性和帮助消歧等。
最后,我们希望直接对忠实度问题进行建模。比如直接对翻译过和未被翻译的内容进行建模,类似于之前提到的覆盖率,但是更加直接。另外,在一些特殊场景下,比如口语中,会存在代词的缺失问题,这也会导致翻译的不完整。
由于报告时间有限,我今天只讲我们最近的三个工作,其他工作会简单介绍一下。
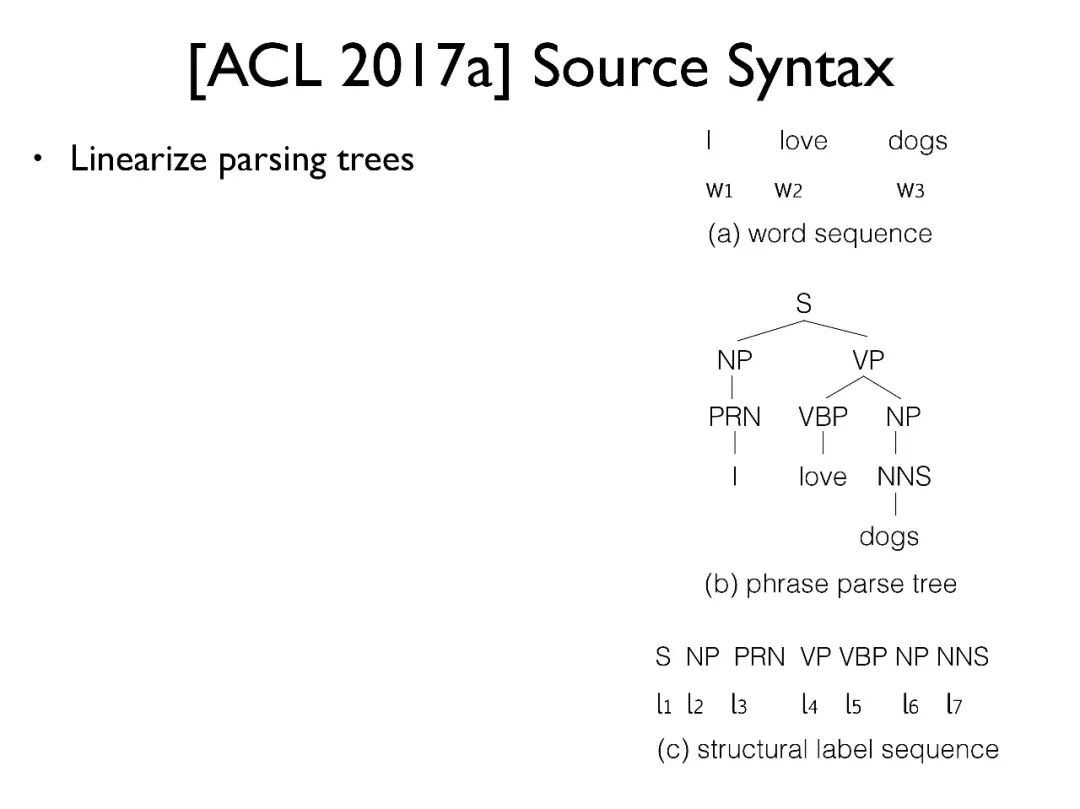
第一个工作是如何集成源端的句法树。我们采用了一种非常简单的方法,首先 (a) 是输入的原句,(b) 是该句的句法树,(c) 将句法树拉平成为一个字符串。
我们提出了三种方法:
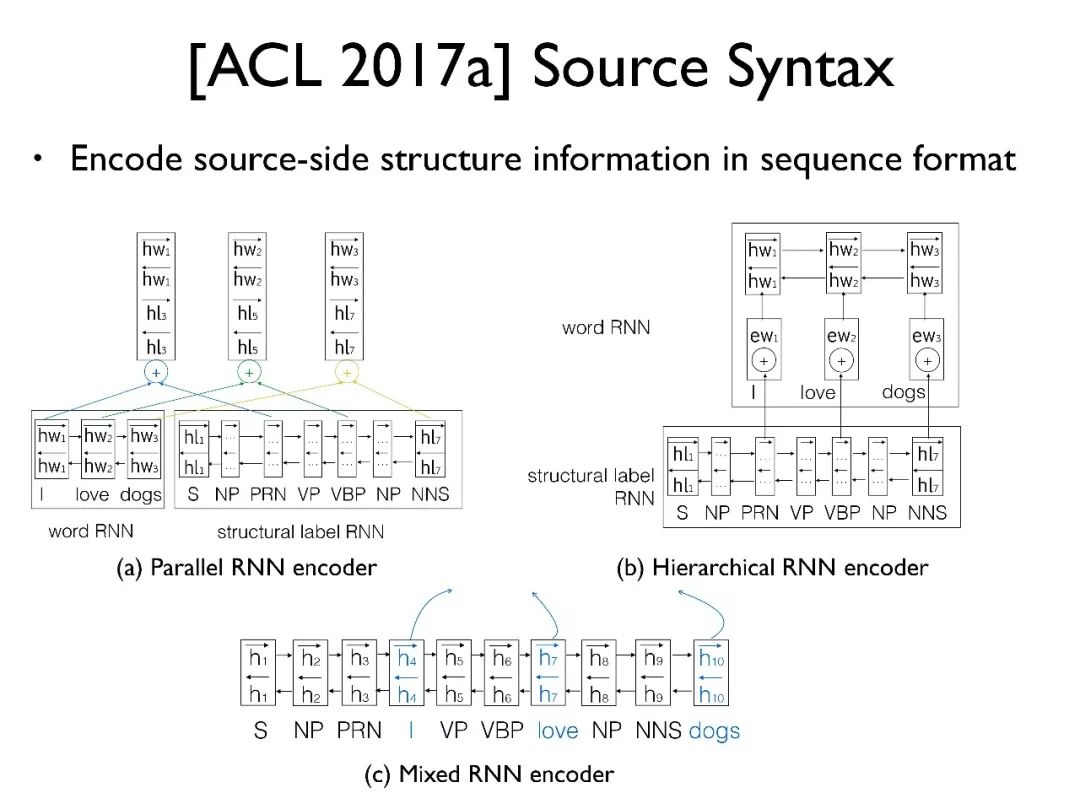
(a) 中是使用两个独立的编码器分别编码句子和句法标签序列,再将生成的向量拼起来作为编码好的隐向量;
(b) 是一种层次化的编码方式,先将句法标签序列编码,再传到对应的词处;
(c) 是比较简单也是最有效的一种方法,将标签和词混合到一起,用单个编码器编码,这样词中就会具有对应的句法信息。这种模型结构在基于神经网络的句法树分析中也是一种常见的做法。

第二个工作是如何将目标端的句法信息引入。我们使用了一种比较浅层的句法知识,引入了一新的个 chunk-layer。
我们希望其能将短语的性质引入,一个 chunk 就是一个短语,比如:“the french republic (法兰西 共和国)” 就是一个 chunk。我们希望“the”, “french”, “republic”这三个词能够共享同一个隐向量,相当于是在隐层维护了短语的概念。
为了实现 chunk,我们需要一个边界预测。在 chunk 内部共享同一个 chunk-layer 的状态,只有在 chunk 边界处才去更新 chunk-layer 的状态。这样就引入了一种“soft phrase”的概念。

第三个工作我们希望直接能复用统计机器翻译中的短语表,因为短语表本身就是一个非常好的知识源。我们利用 SMT 推荐一些短语的翻译结果,以及利用 NMT 推荐词的翻译结果,而后通过一个 Balancer 平衡两个的翻译结果。
这种方法效果上并不是特别好,但是比较具有创新性。我们也再进一步改进这个工作,希望找到更好的方式去实现这种结合。
TACL 2018a

首先是篇章级别的翻译,这是我们与清华大学刘洋老师合作的文章。
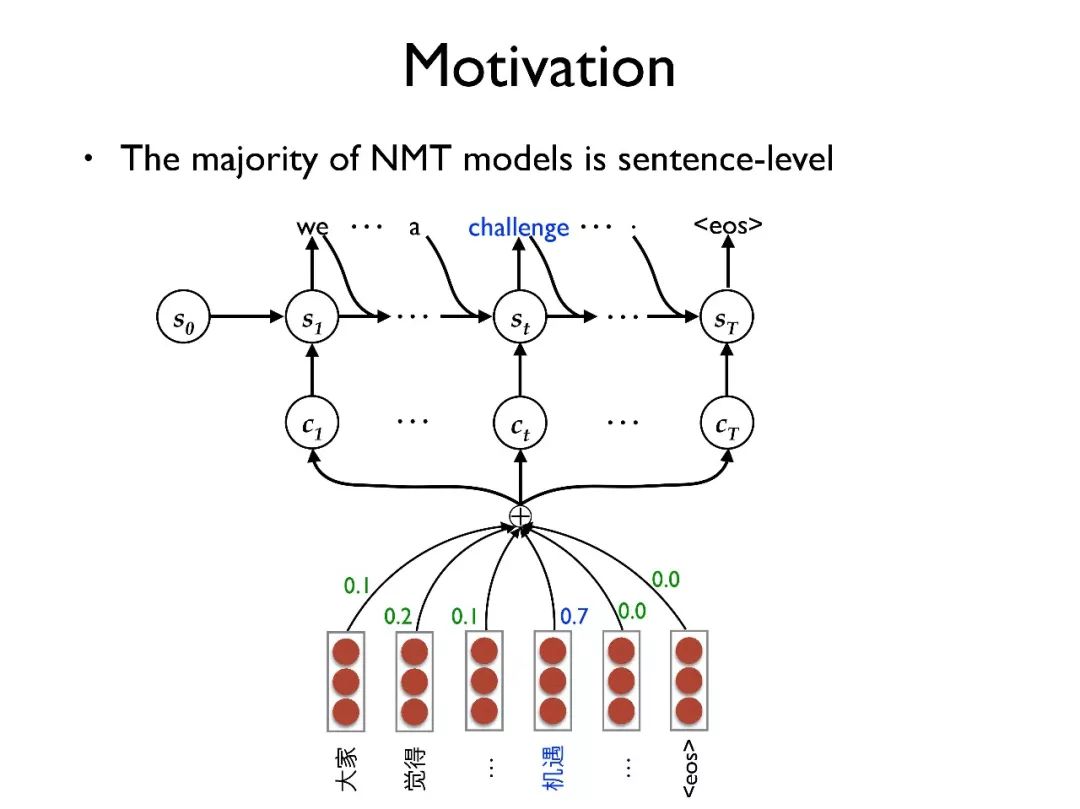

当前大部分的翻译都是基于句子的翻译,上面的例子中可以看到,由于该句子中缺少重要的上下文信息,“机遇”被错误地翻译成了“challenge”。
对于篇章级别的翻译有两个重要问题。一个是一致性问题(consistency),比如时态问题,在历史翻译中会把“觉得”翻译成“felt”,在当前翻译中会翻译成“feel”。如果只考虑一个句子,这种时态问题就很难保持一致,但是实际应用中一致性是非常重要的。
另一个是歧义问题(ambiguity),这个是机器翻译中的经典问题,在统计机器翻译中就存在,在神经网络机器翻译中这个问题更加严重。因为在神经网络机器翻译中采用词向量来表示每个词,这种方式可以缓解词的稀疏性并学习到词之间的关系。
但是这种方式也给翻译带来了词选择的困难,比如在翻译“机遇”时就很容易将其错翻成“challenge”而不是“opportunity”,尤其在缺乏额外的上下文信息的时候。

我们就希望解决以上两个问题,如上图,对比 base 模型,我们可以将过去时和有歧义的词翻译出来。右边的矩阵图中 x 轴是生成的译文,y 轴是历史信息。
在生成“felt”这个词时,模型找到了历史中出现的“felt”,从而保持了时态的一致性;在生成“opportunity”的时候,模型找到了历史中出现的“courses”,“tasks”等词,通过这些词的信息正确地翻译出“opportunity”。

虽然这些问题对于 NMT 是较新的问题,但在 SMT 的技术中已经验证过篇章级的翻译会缓解以上两个问题。由于很多研究是针对于对 NMT 模型结构的改进,缺乏对特定问题的关注。我们是较早期地采用篇章级的翻译去解决以上两个问题。
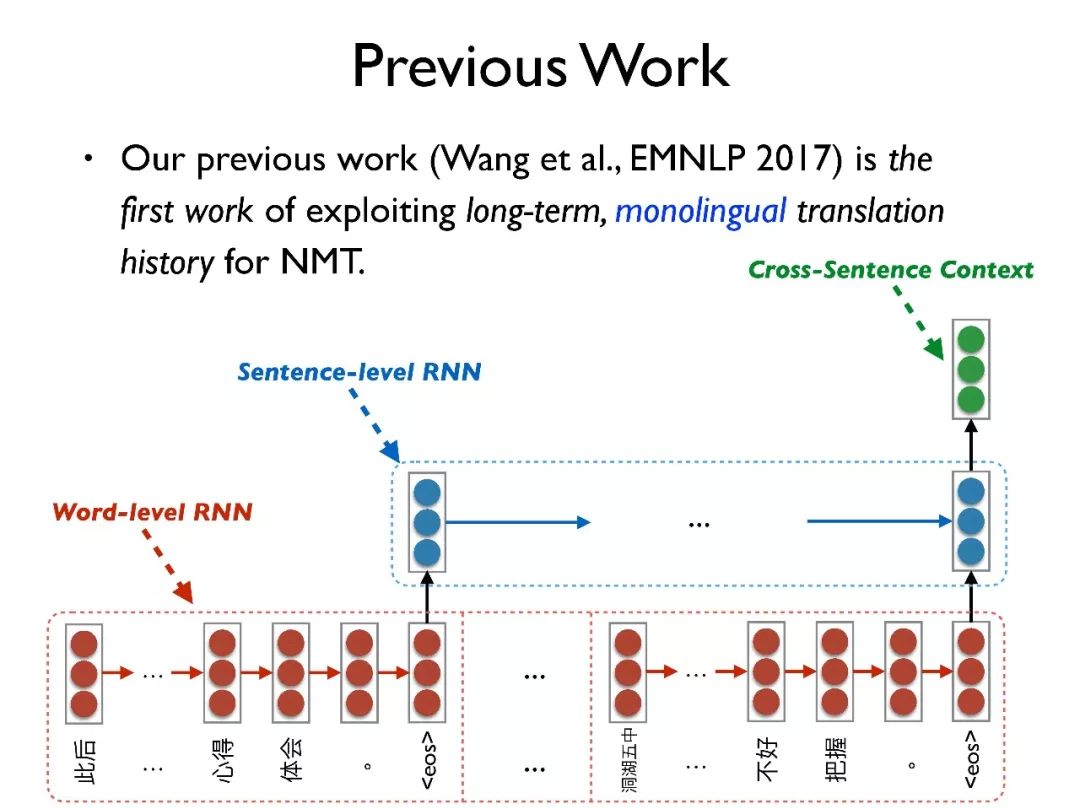
首先介绍一些历史工作。第一个是我们在 EMNLP2017 中一篇短文的工作,利用了长期的、单语料的翻译历史信息。
我们用层次化的 RNN,一个是 word-level RNN 去编码每个句子得到每个句子的向量表征,另一个是 sentence-level RNN 将上一步生成的向量再次编码成一个整个篇章的表征向量。
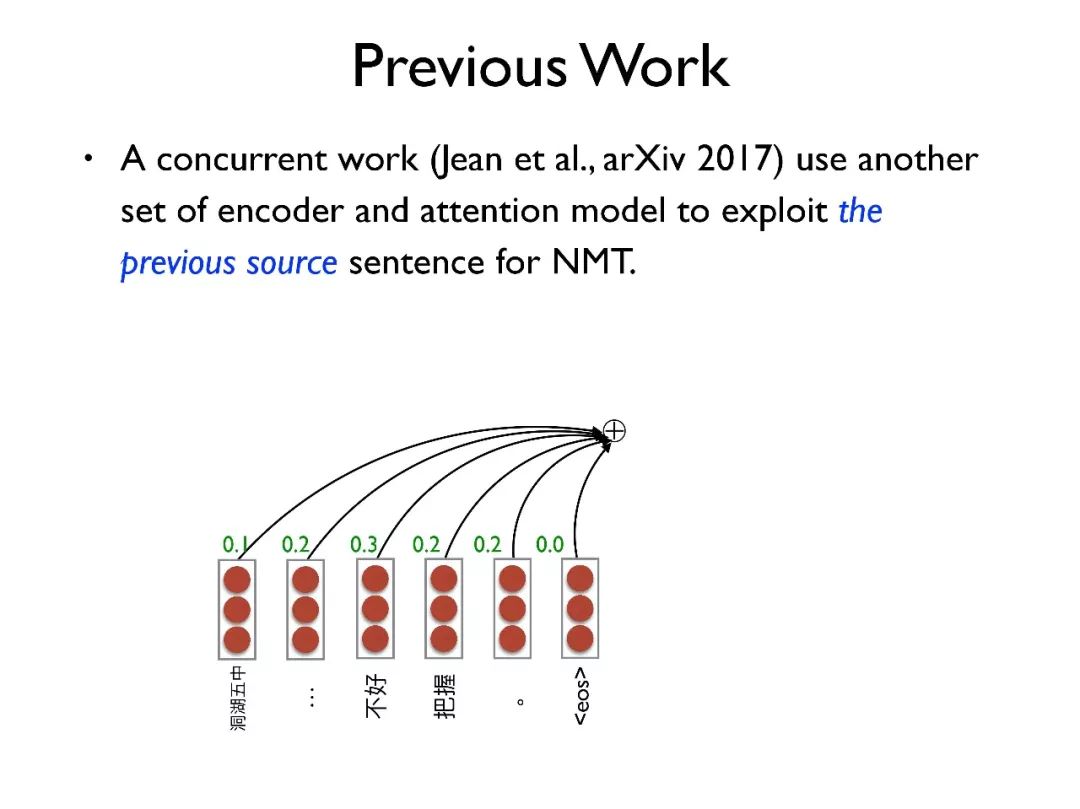
第二个是纽约大学的工作,采用另外一套编码器和注意力机制去引入前面一个句子的信息。虽然这些工作已经被证明具有一定的有效性,但是存在一些缺点。
首先,它们的计算复杂度较高,使得其必须限定在比较小的范围内操作 。其次,由于它们只使用了单语的信息,因此有可能不适用与某些特定领域,比如在电影字幕领域,由于电影字幕很多是意译而非逐词翻译,所以只利用源端信息很难翻译正确。

于是, 我们提出了一个轻量级的翻译模型,增加了 key-value 的 cache memory 来存储翻译的历史信息。计算复杂度较低,同时适用于不同领域。


上图是我们的模型的结构,在标准的 NMT 模型上,我们引入了一个 cache memory 来存储翻译的历史信息。
所谓翻译历史信息就是在过去解码过程中的源端 context vector 和目标端状态信息,这一对信息可以较好地表达翻译历史信息。
我们将源端作为 key,目标端作为 value。在解码的过程中,我们利用当前的从 cache memory 中检索,把 value 中相关的值结合起来得到一个输出,并将该输出与 decoder 的当前状态结合得到一个新的状态。该状态中就带有翻译历史的信息从而能更好地进行翻译。
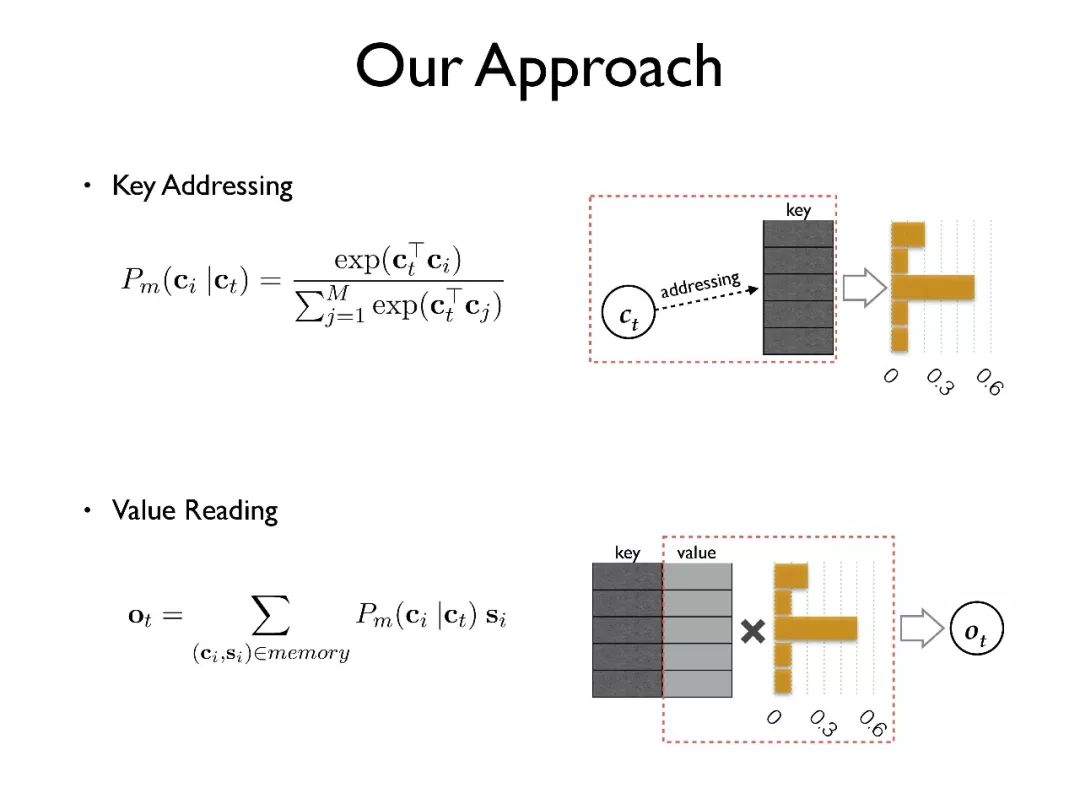
简单介绍一下模型的细节。首先是检索(key addressing)的方法,我们尝试了很多中实现方式比如 attention,加入转换矩阵等。我们最后选择用点积的方式,能够在保证效果的同时速度最快。
其次是值读取(value reading)的方法,采用根据检索得到的概率分布加权求和得到输出。
再次是和的结合,我们采用一个”gate”来做更新。这种方式是具有语言学含义的,因为对于一些实词和动词在翻译时需要篇章信息来进行消歧和确定时态。但对于一些虚词就不需要篇章的信息。
最后根据结合后的状态信息生成词。总的来说,这个工作使用了一个轻量级的 memory 结构来记住双语的历史翻译信息,不仅计算复杂度较低,还可以用于不同的领域。
TACL 2018b

第二个工作是直接对忠实度建模,这是我们和南京大学合作的文章。
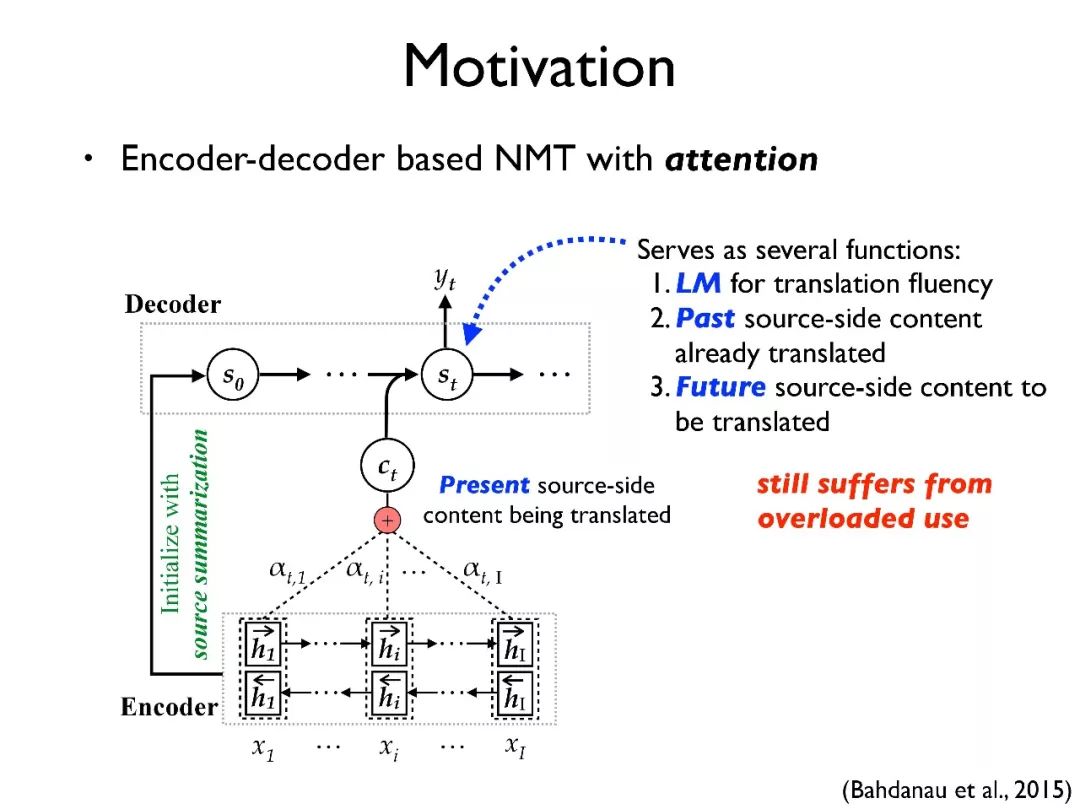

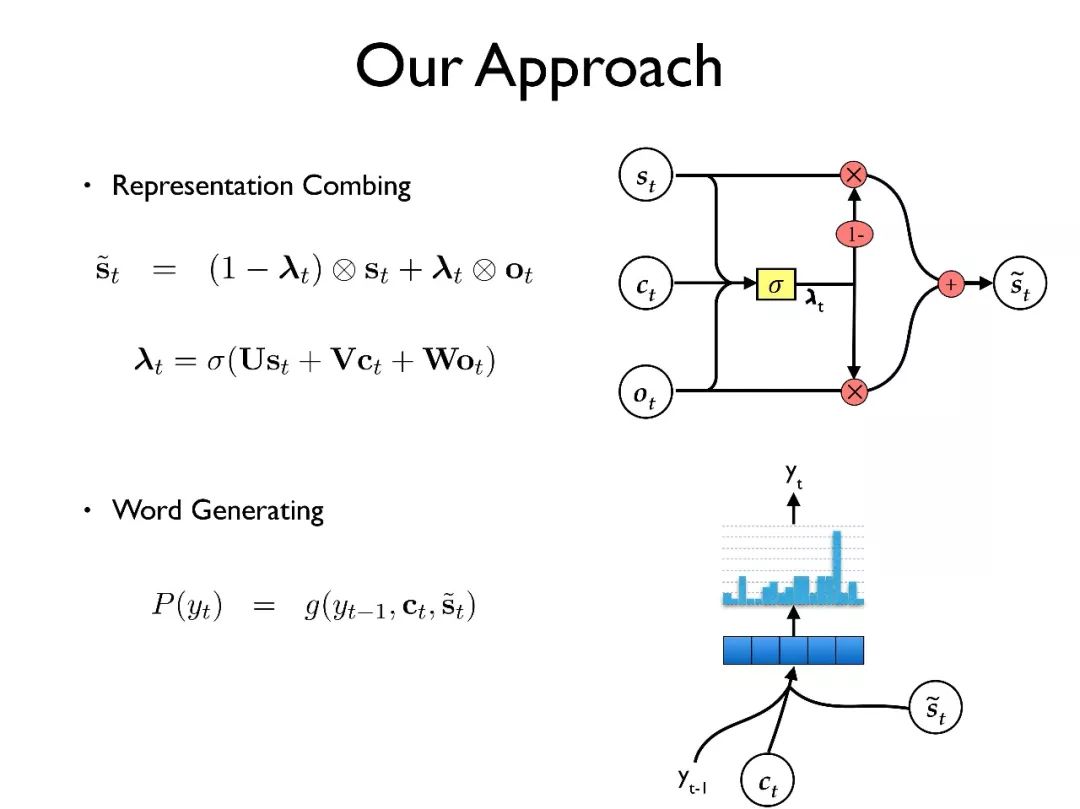
这个工作的动机是:在最初的编码器和解码器结构下,解码器的状态信息需要承担很多任务。
第一个是它需要承担语言模型的责任,以保证翻译的流畅度。第二个是其需要保存三个内容:当前被翻译的内容(present),已经被翻译的内容(past)和没有被翻译的内容(future)。
然而一个解码器状态其实只是一个 1000-2000 维的向量,需要同时承担这么多任务会对训练带来很大的难度。
2015 年,有研究者提出了注意力机制(attention),它将保存当前被翻译的内容的任务分离出来,在翻译过程中动态生成来指导当前需要翻译的内容。这种方式给翻译带来了很大的提升,现在也作为了许多深度学习模型的标配。
但即使这样,解码器的状态仍旧需要承担其他三个任务。因此,我们假设如果能把这些任务再次分离会带来效果的进一步提升。
近期的一些工作都验证发现,如果模型中每个向量或者组件都能很清晰地学习出某一部分的作用,那么将会得到更好的效果,包括近期 Hinton 提出的胶囊网络其实也是类似的思想。
为了验证我们的想法, 我们做了更细致的探究。首先,我们发现 NMT 有很多漏译和重复翻译的错误,这个问题说明模型没有很好地将源端的信息传递到目标端。另外,理想情况下我们希望在每步翻译时,解码器都能将翻译过的内容减掉,只保留未被翻译的内容。
然而我们发现,即使用全零向量初始化解码器,其效果也不会下降太多,说明解码器并不能很好地利用源端的信息。
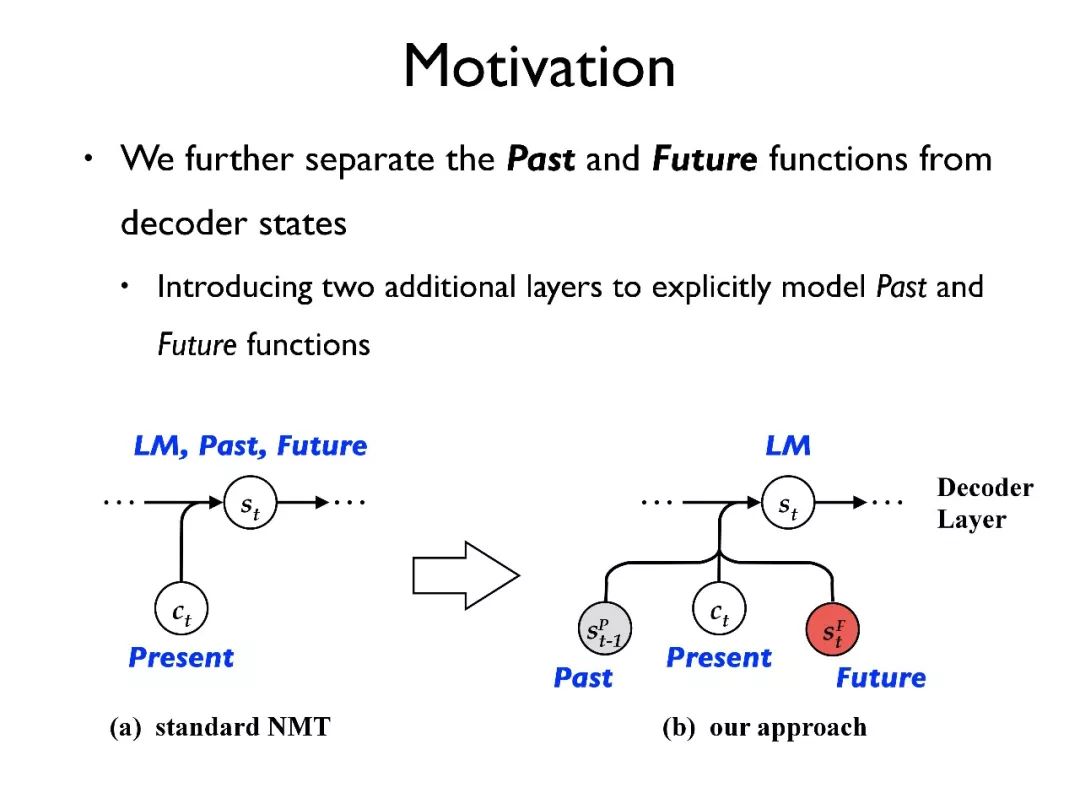
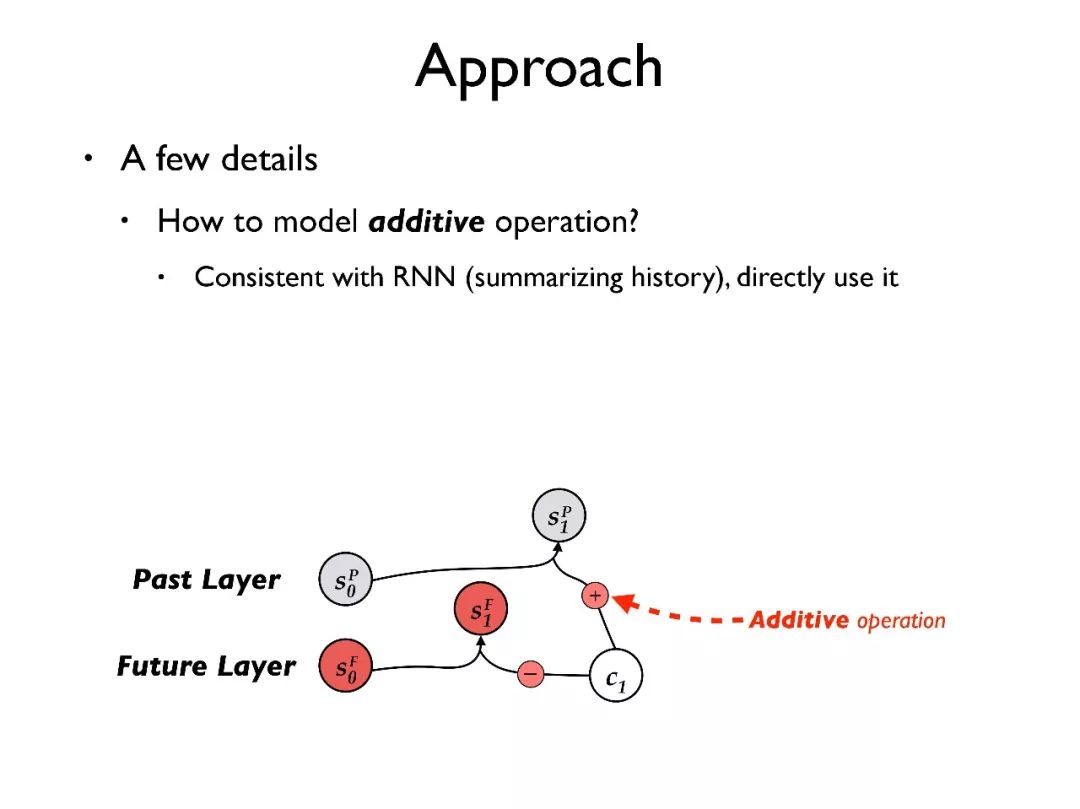
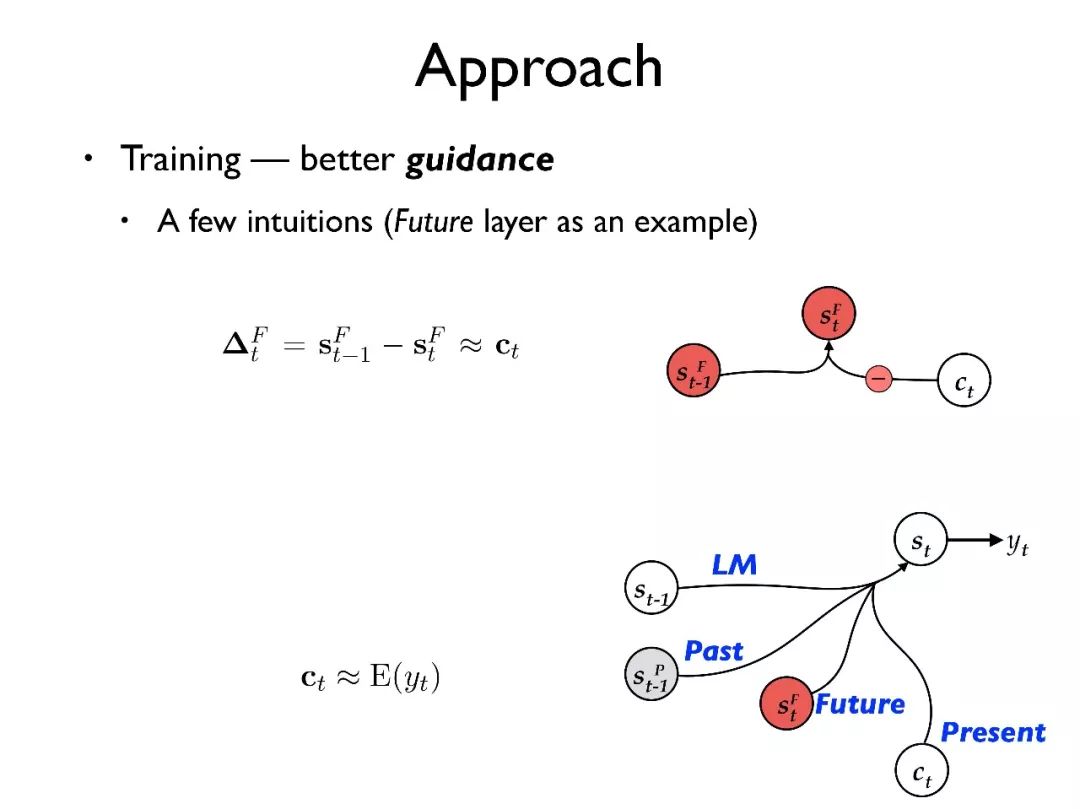
我们的工作希望把对 past 和 future 的表征分离出来,进行单独建模。
举一个例子来展示我们的想法,对于一个输入句子,首先用 RNN 将其转化为隐向量序列。在目标端有三层结构:decoder layer, past layer, future layer。
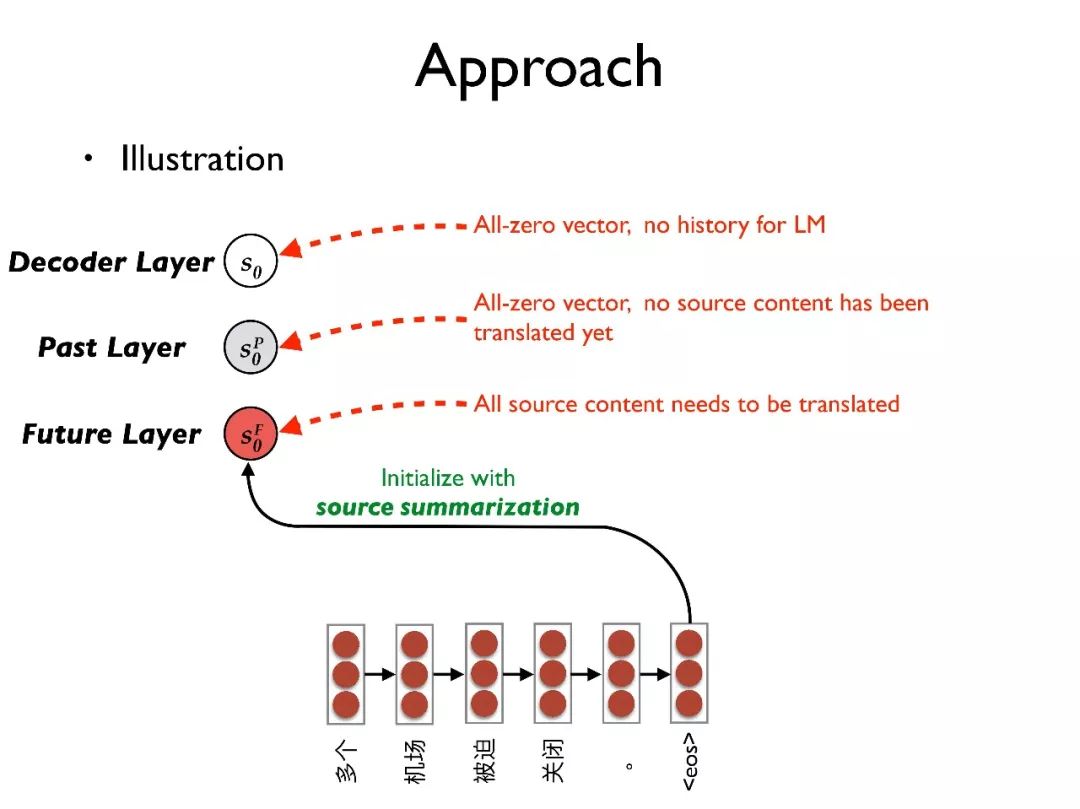
首先用源端句子的总结去初始化 future layer,也就是代表最初整个句子都需要被翻译;用全零向量初始化 past layer,代表当前没有内容已经被翻译;同样用全零向量初始化 decoder layer,也就是对语言模型当前没有任何历史信息。
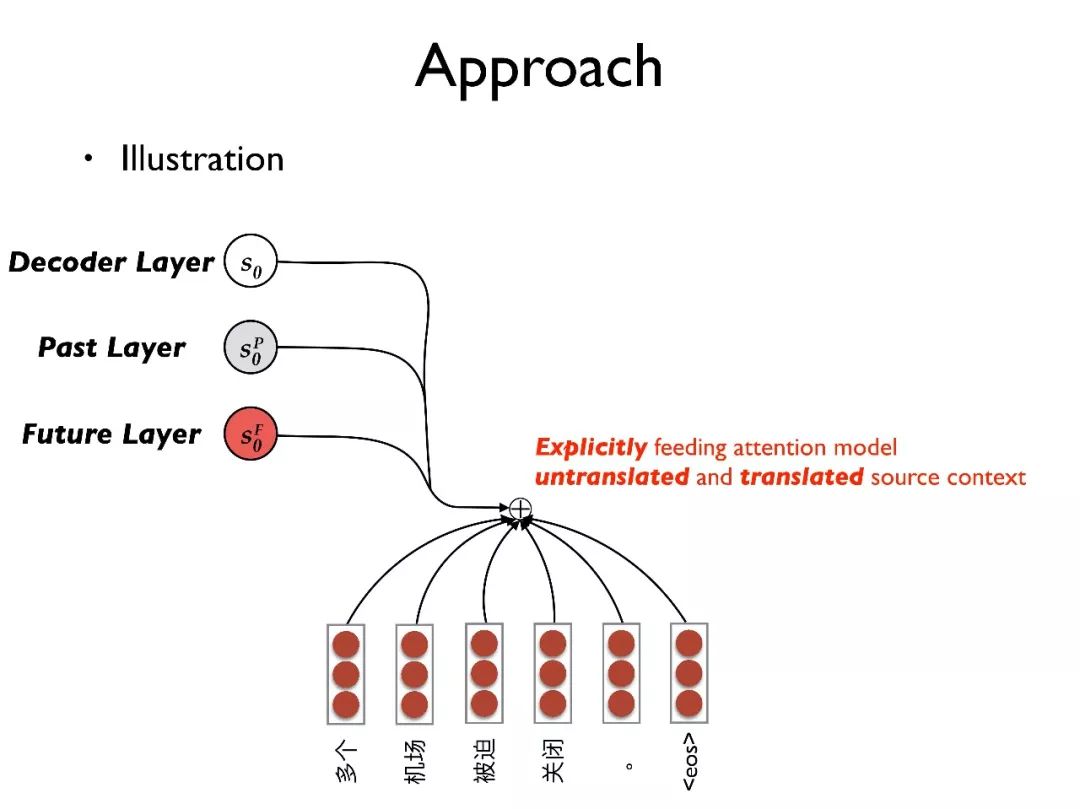
其次,我们将三层的状态 都传入 attention 模型,这样 attention 模型可以更好地确定需要被翻译的内容和规避翻译过的内容。
都传入 attention 模型,这样 attention 模型可以更好地确定需要被翻译的内容和规避翻译过的内容。
在翻译了第一个词时,我们将 C1 从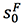 中减去得到
中减去得到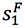 ,也就是从未被翻译的内容中减去当前的内容。
,也就是从未被翻译的内容中减去当前的内容。
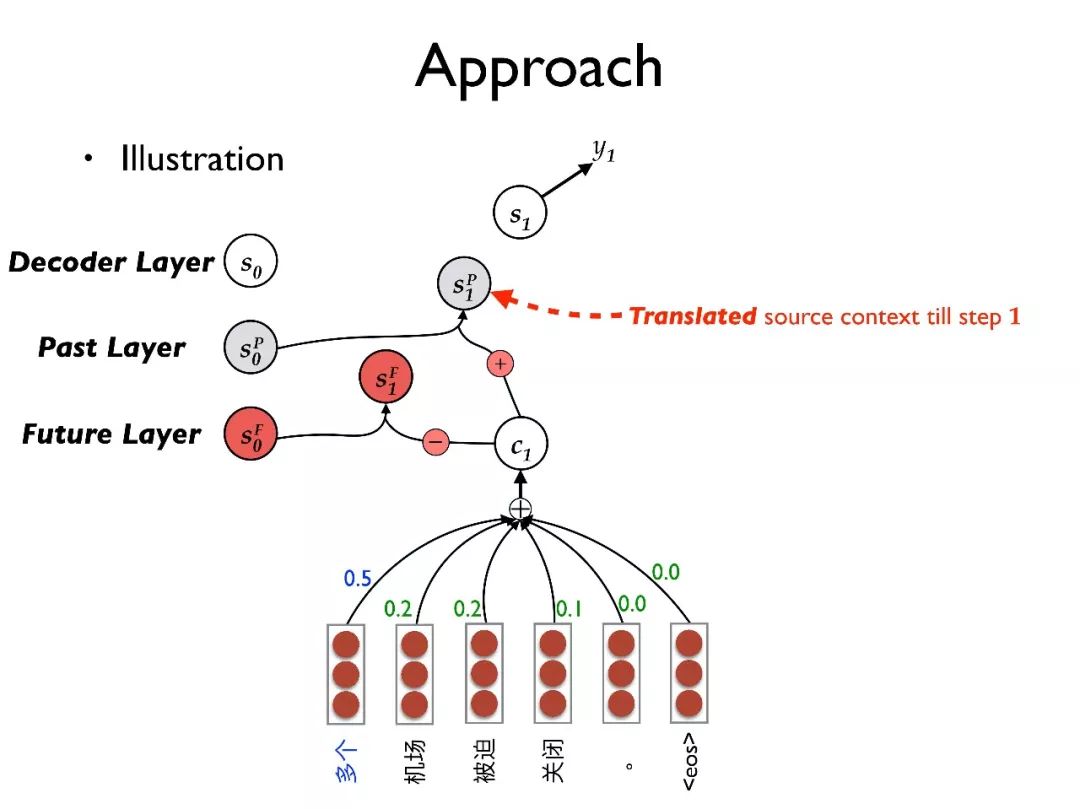
将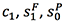 用于更新 decoder layer 的状态得到 S1,并预测输出词 y1;最后再将 C1 加到
用于更新 decoder layer 的状态得到 S1,并预测输出词 y1;最后再将 C1 加到 上得到
上得到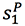 ,从而更新被翻译过的内容。以此类推进行翻译。
,从而更新被翻译过的内容。以此类推进行翻译。
总的来说我们引入了多层结构,每层有清晰独立的功能建模。
下面简单介绍一些技术细节。首先,如何建模加法操作,因为模型中用到加法操作是和 RNN 的更新密切相关的,所以我们直接利用 RNN 来完成加法操作。
其次,如何建模减法操作,参考词向量模型中的经典公式 E(king) - E(male) + E(female) = E(queue),我们也希望能直接在 RNN 更新过程中建模减法操作。
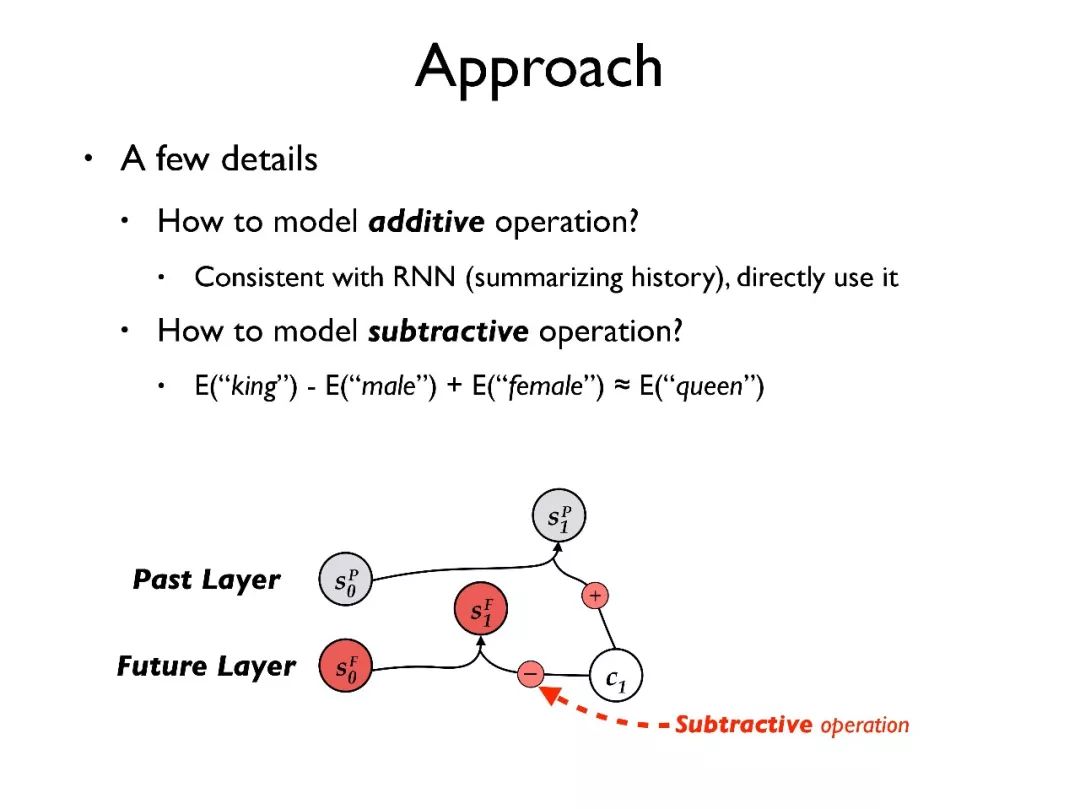
以 GRU 为例,第一个可以使用标准的 GRU 结构,让模型自动学出减法操作;第二个我们提出了 GRU-o,我们将减法操作建模在 GRU 的外面,在上乘以负号再输入 GRU;第三个我们提出了 GRU-i,在 GRU 结构内部建模减操作,把原本对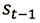 的重置改为对 Ct 的重置,并乘以一个负号。
的重置改为对 Ct 的重置,并乘以一个负号。

另外,为了让组间更清晰地学习到相关的功能,我们在训练时引入了额外的指导。以 future layer 为例,我们希望满足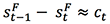 ,同时
,同时 。
。
因此我们在训练目标中加入了使得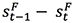 尽可能等于
尽可能等于 的学习目标。同样对于 past layer,我们也希望
的学习目标。同样对于 past layer,我们也希望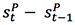 尽可能等于。
尽可能等于。

我们在中英和德英数据集上都做了实验。

首先在中英上,我们只加入 future layer 并对比了三种减法操作的建模方式,发现 GRU-i 效果最好 ;再加入额外的学习目标效果会更好;同样只用 past layer 也有类似的效果;最后,同时使用 past layer,future layer 和额外的学习目标会达到最好的效果。
另外,我们对比了仅仅使用多层解码器的情况,发现其提高并不显著。最后,对比我们以前的 coverage 的工作能够有进一步的提升。
这种提升主要来源于两方面:一方面是这个工作中我们直接对语义内容进行建模,而非仅仅是针对于词;另一方面这个工作同时影响了 attention 机制和解码器状态。
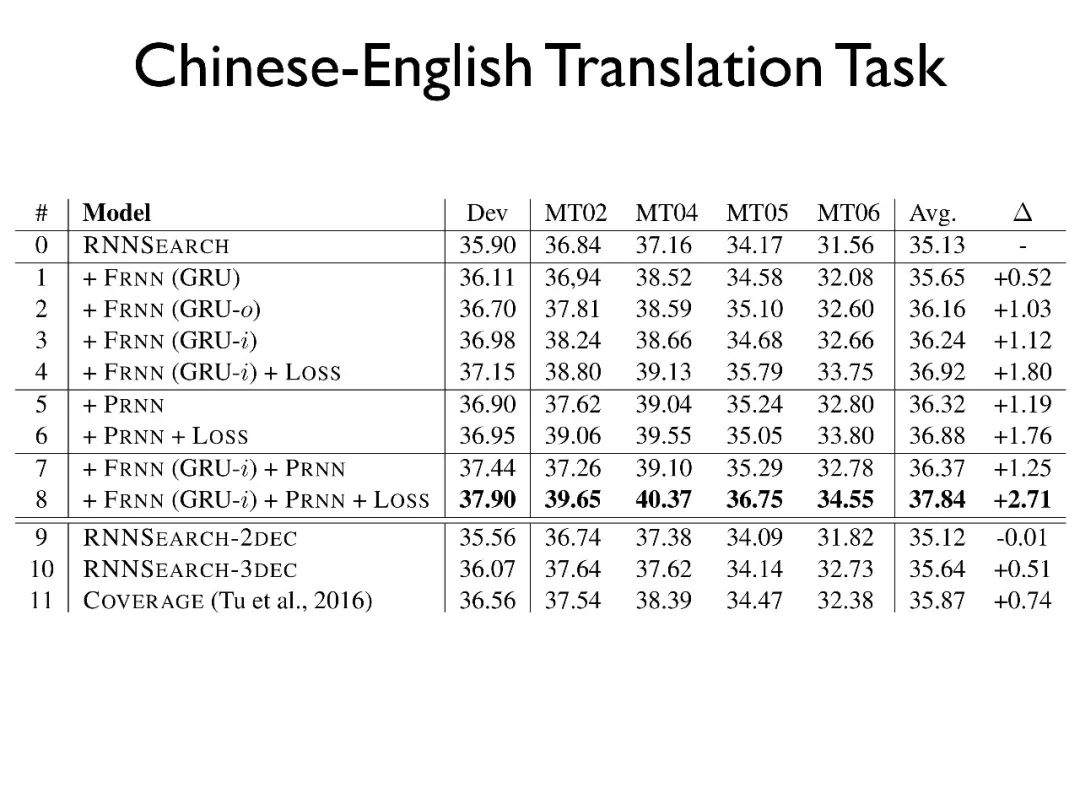
在德英上的实验发现我们的模型和很多其他工作是有可比性的。另外,人工的评测发现我们的工作在过度翻译和漏译上都有一定提升。最后,对于词对齐的效果也有所提升。

总结来说,该工作直接建模了翻译过和未被翻译的内容,并在不同的数据集上都得到了效果验证。
AAAI 2018

最后一个工作是我们和都柏林大学的合作,针对口语领域,尤其是中文等 pro-dropp language 进行处理。

Pro-dropp language 是代词省略的语言,比如中文中经常为了保持句子的紧凑程度,而把一些代词省去。
在中英翻译中,我们对 100 万的句对进行了分析,其中有 20% 的中文句子中存在代词省略的现象,而对应的英文句子则不存在代词的省略。

这种现象会对翻译带来较大的困难。在 NMT 中这个问题的影响被略微减轻,模型在翻译时可以自动地补全一些代词,来保持句子的完整性。但是在一些复杂的代词省略场景下,NMT 也会出现错误翻译的现象,甚至有可能完全改变了整句的意思。
我们在原始数据和人工补全了代词的数据上分别做了实验,发现代词的补全对翻译效果有大约 5.0BLEU 的提升。
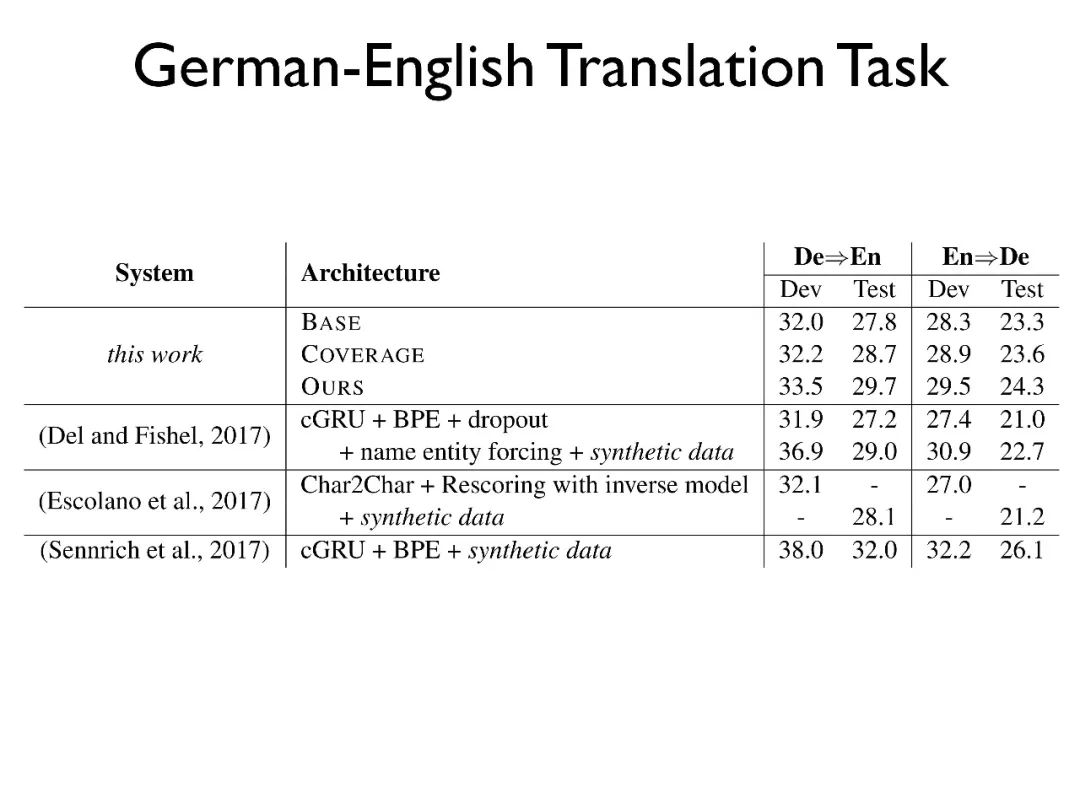
我们引入了去年我们在 AAAI 中提出的 Reconstructor 模型,该模型类似于 auto-encoder,目标是重新生成原文,从而找到更好的原文表示,具体的模型细节不再赘述。
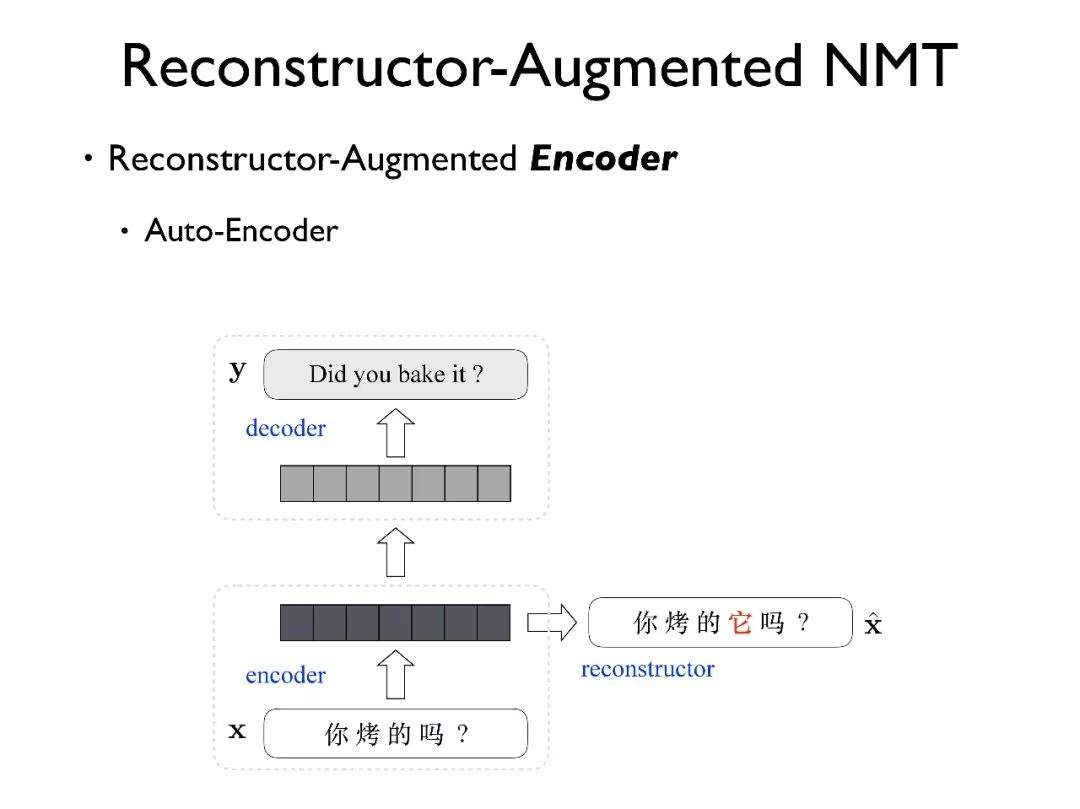
我们采用了不同的方法构建模型,比如我们在源端增加了一个 Reconstructor, 利用 Reconstructor 的编码器状态,希望其中能蕴含补全的代词信息。
Reconstructor 是通过标注后的单语料数据训练得到的。后面我们会验证如果直接使用 Reconstructor 自动生成的数据作为训练语料,由于错误的累积,其效果不好。
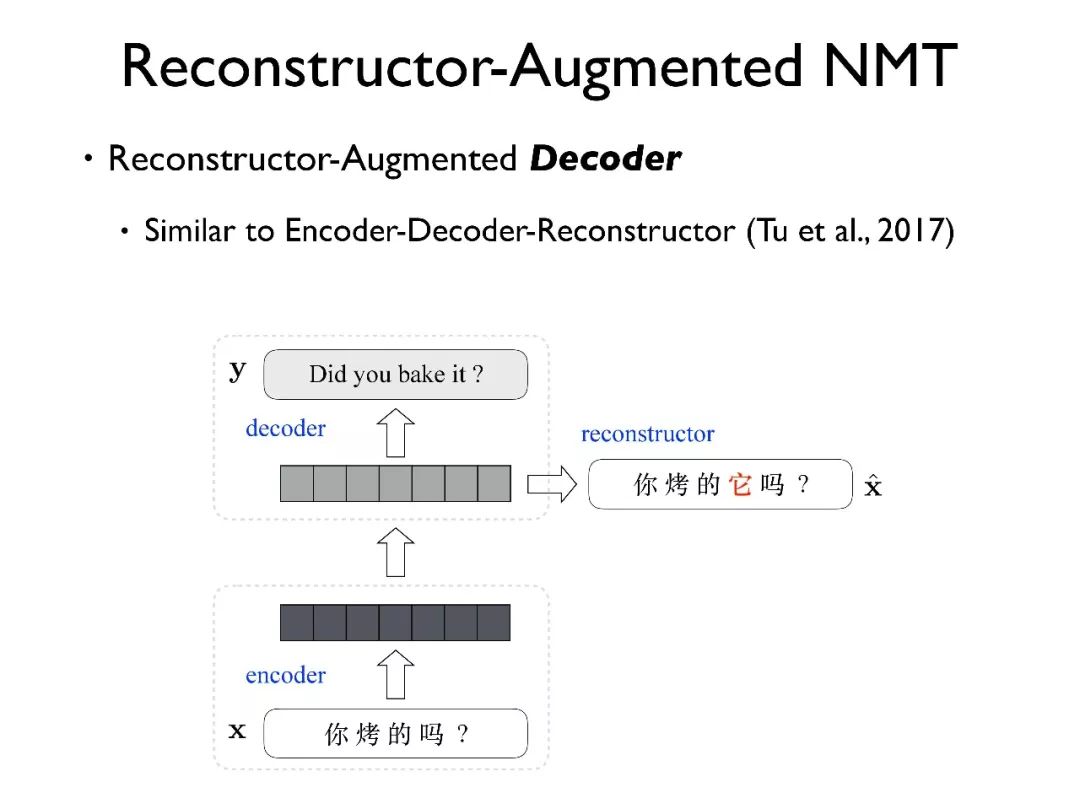
另外一种方式是把 Reconstructor 放在目标端,目的是使得解码器的输入不仅适合于翻译,同时也能很好地表示原文信息。
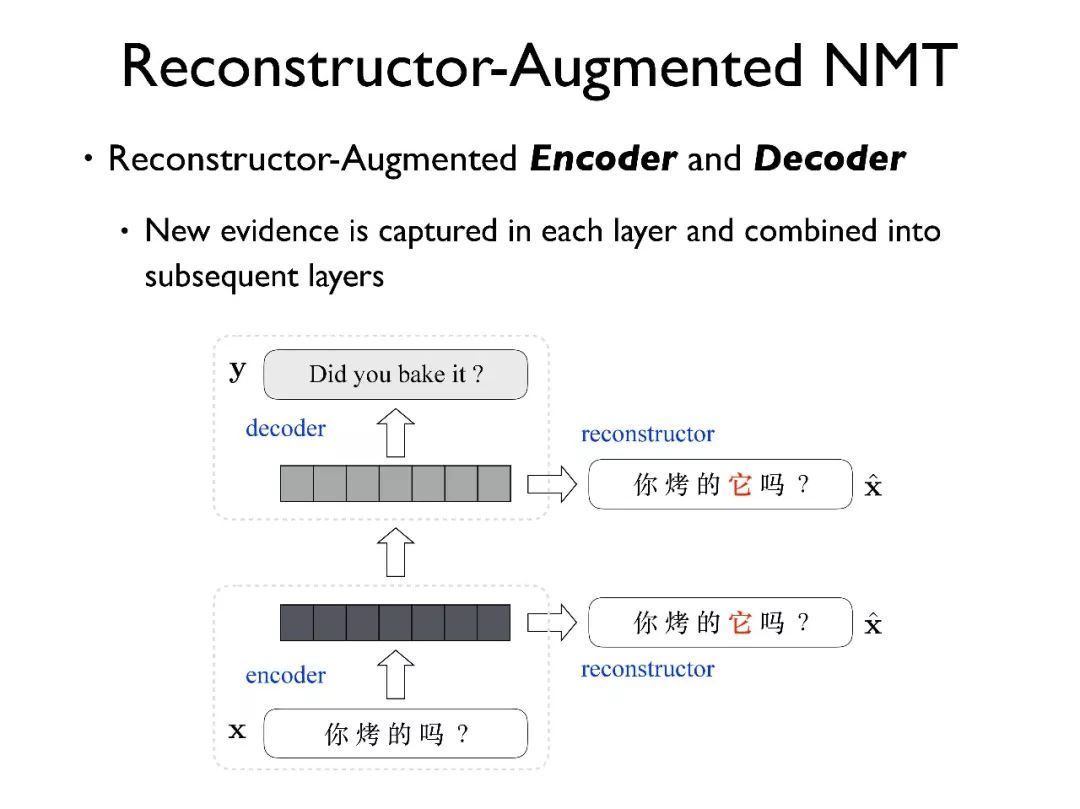
最后,我们可以将 Reconstructor 同时用在源端和目标端。这种模型和 QA 中多层 memory 的结构是非常类似的,在每一层都传入同样的信息源,通过模型自己的学习机制,使得每一层都能捕获到其需要的信息。
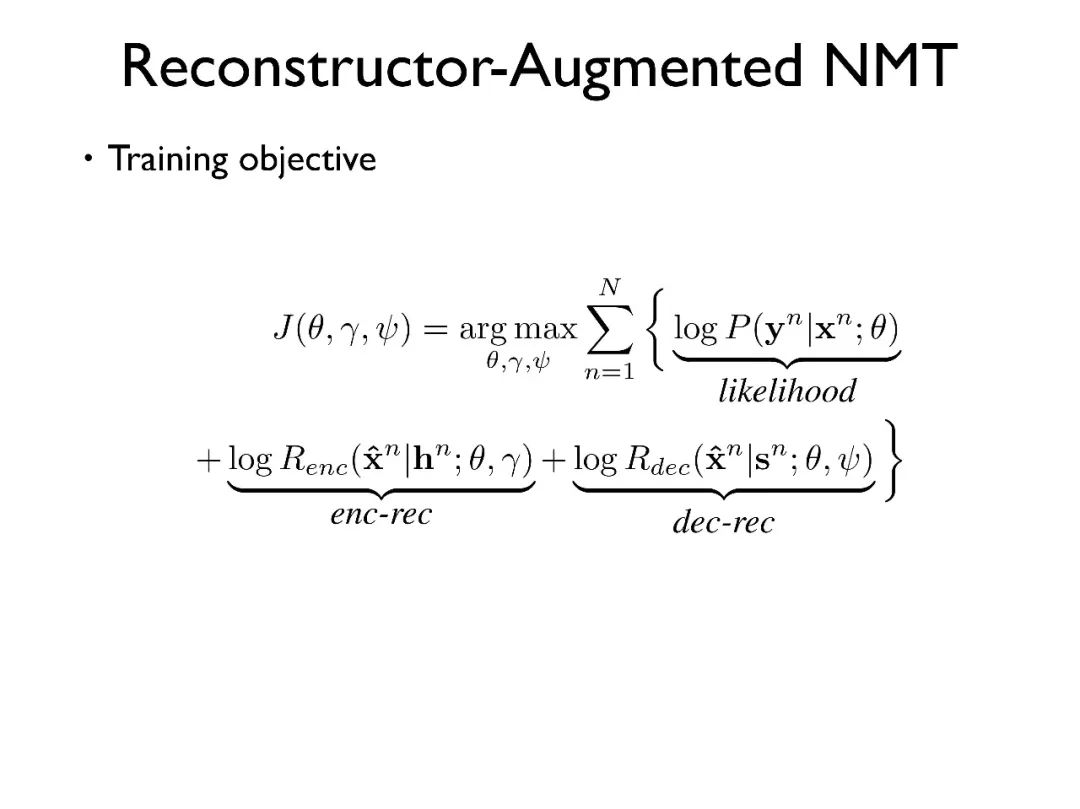
模型的学习目标除了原本的似然度之外,还有源端和目标端 Reconstructor 的学习目标。
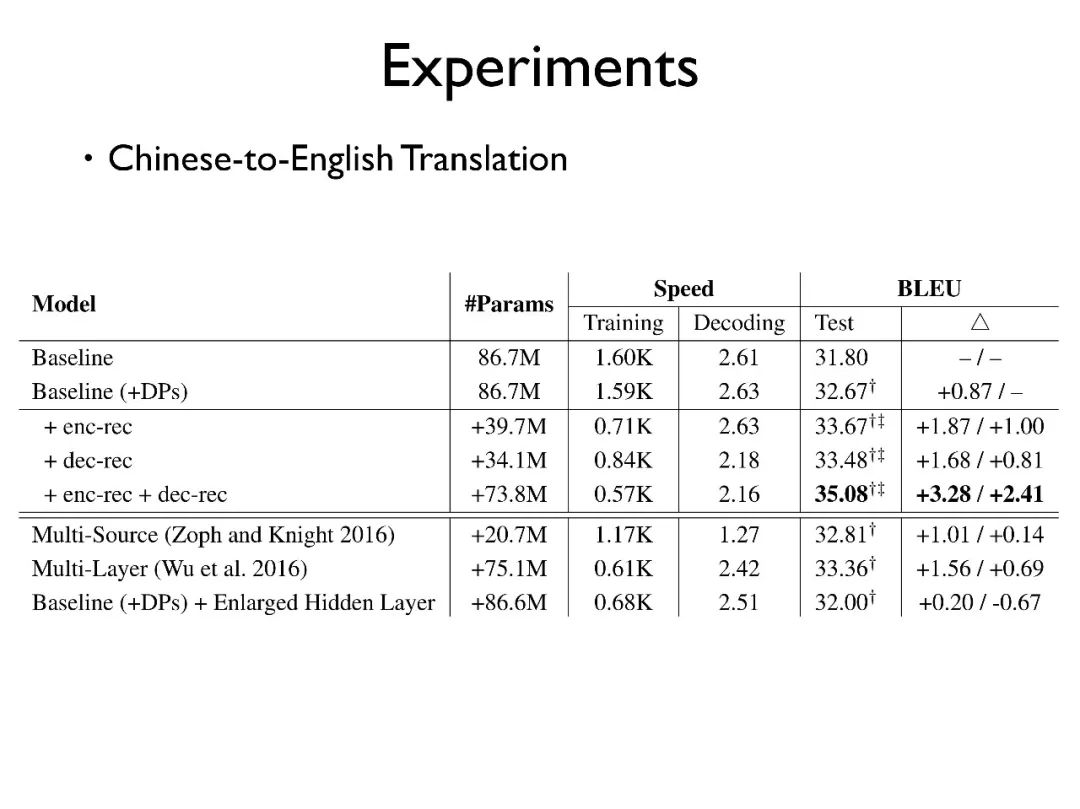
首先来看中英上的实验,baseline 模型是用原始的句对;baseline+DPs 是我们使用自动补全了代词的句子所为训练语料,能比原始 baseline 有所提高,但提高较少。
下面三个是我们提出的模型:在编码器端加入 Reconstructor,在解码器端加入 Reconstructor,在两端均加入 Reconstructor。可以看出,对训练和解码的速度都是有一定影响的,但是其影响可以接受。
两端均加入 Reconstructor 的方法效果最好,可以印证我们的猜想。
同时,我们和其他的方法进行对比,比如有工作尝试使用多个输入源的方式等,发现其效果不如我们的工作 ;另外有工作使用多层的结构来解决这个问题,同样没有我们模型的效果显著;最后我们对比增大 hidden layer 大小的模型,发现模型的效果也不仅仅来自于参数的增多。
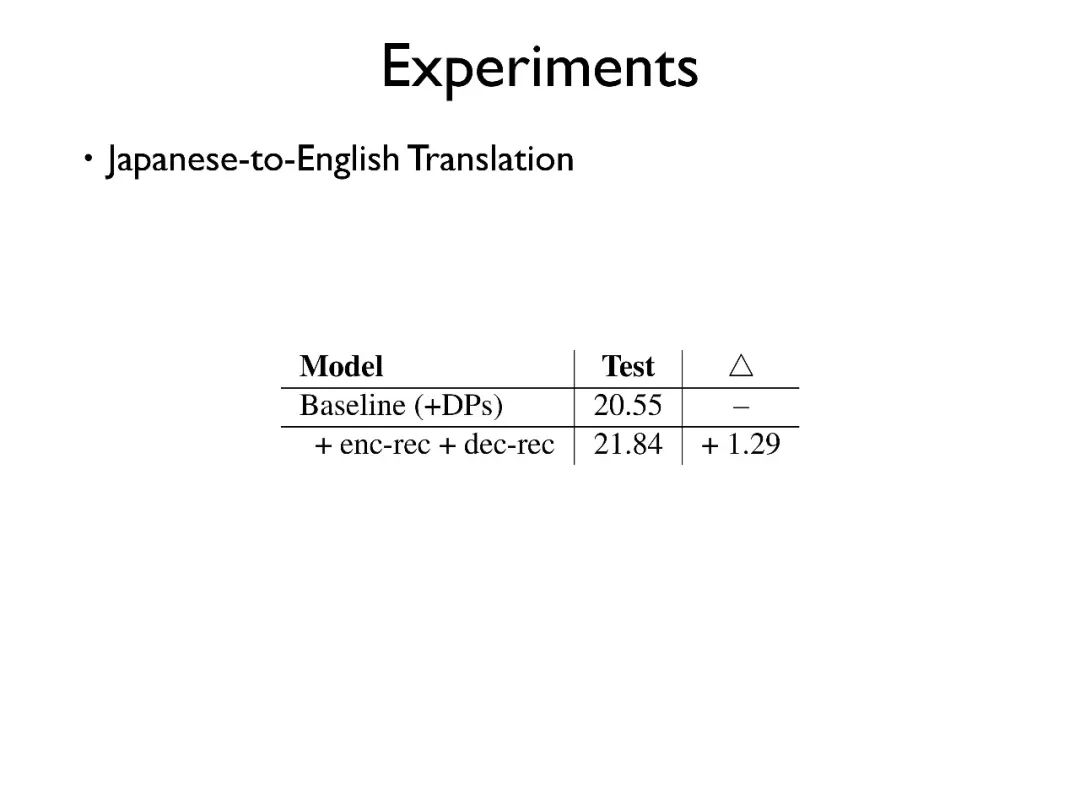
其次,在日英翻译中我们的模型也给出了比较好的效果。
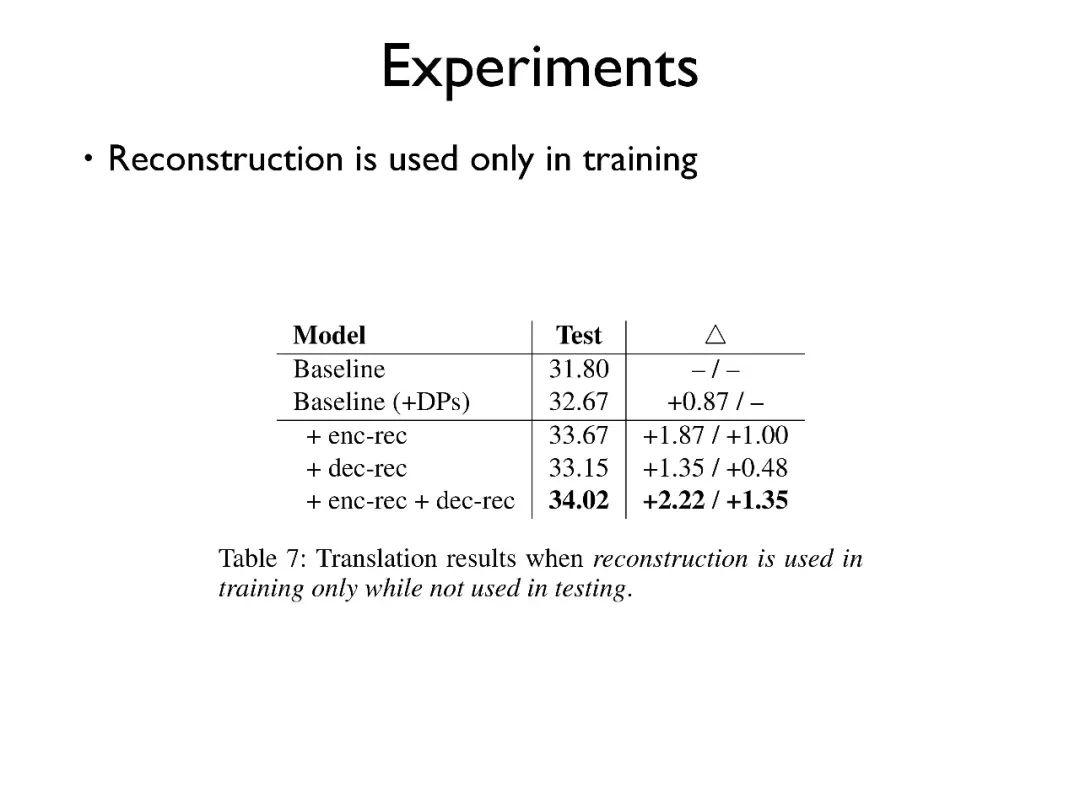
我们试验了仅在训练时使用 Reconstructor,而测试时不使用,这样也会带来 2.22BLEU 的提升。这说明该模型在实际的系统部署中不会带来额外的开销。

其次,我们在模型中使用重构原句而非重构标注后语句的 Reconstructor,发现效果也有一定提升,但提升较少。
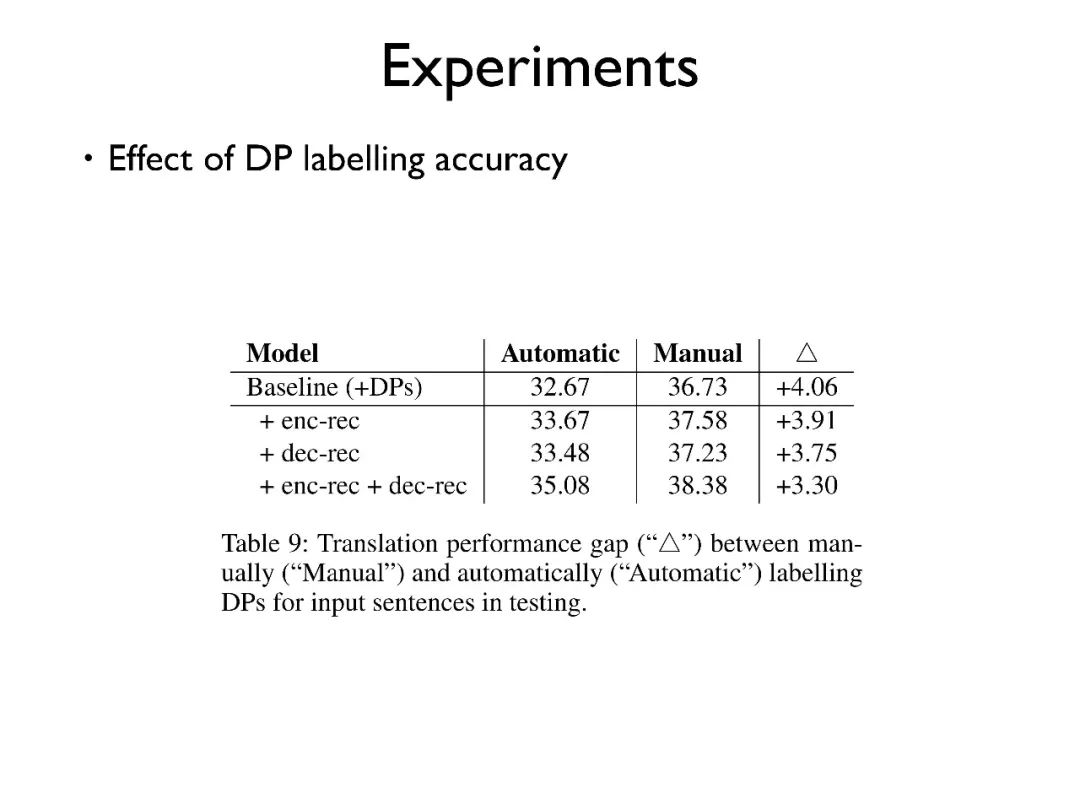
另外,我们发现对使用比人工标注后的数据,我们的模型还存在很大的提升空间。
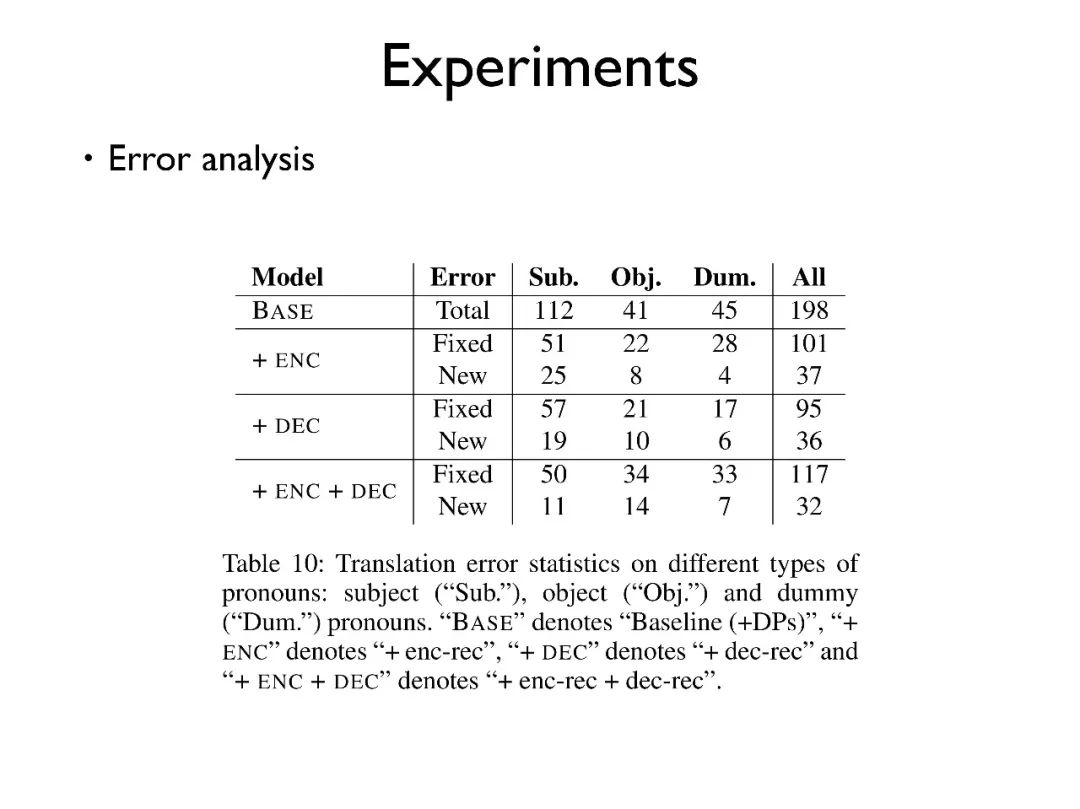
最后,我们进行了错误的分析,可以看出对于 subject, object, dummy 三类代词,我们的模型都能解决大部分错误,引入小部分错误,整体作用是正向的。

上图给出了一些例子,可以看出我们的模型在翻译的时候,不仅仅有补全代词带来的准确率,更多的是防止由于代词缺失带来的句子结构的变化。
总的来说,我们是在 NMT 中较为早期地对代词问题进行建模;在编码解码中我们都能引入代词的信息;如果代词的标注效果提升之后,我们的模型效果会有进一步提升。
以上是我的报告的全部内容,主要介绍在过去一年我们为了提高神经网络翻译忠实度问题上所作出的工作。
Q & A
Q:请问词向量用的是什么?
A:我们用到的词向量都是在模型中自动学习到的。我们实验发现,在比较大的外部数据集,比如 Wikipedia 数据,训练得到的词向量并不适合翻译任务。因为在翻译中想要学习到的词向量可能不仅仅是为了表征每个词的意思和聚类,而是学习到语言之间的关系。
Q:在大的训练语料中是否有推广?
A:好问题!有些模型我们有在大的语料上做了验证,但有些模型并不能很容易推广。 比如引入句法树的方法,因为其本身模型代价较高,在大的语料上效果不明显。所以这个工作更偏科研一些。
Q:请问训练语料都是哪里来的?
A:一般是用开源数据,比如 WMT 上的英德、英法数据。这样可以保持与其他工作有横向可比性。中英目前在 WMT 也有一千万的中英翻译数据。
Q:如何提升解码速度?
A:可以看看 Jacob Devlin 的一些工作,他现在在微软。他的一些开源报告中提出了很多加速方式。比如我们一般使用全部的 softmax,可以换成使用 sampled softmax 等等。
Q:需要迭代多少万次?
A:在百万级的数据上,一个 mini-batch 是 80 的话,一般迭代 15 万到 20 万次会达到比较好的效果。如果加上 layer norm 或者 dropout 的话,会使得实验速度更快一些。
Q:Transformer 的实际实验效果差距大吗?
A:差距确实很大。Transformer 可能是未来的一个 benchmark,但是现在它还存在一些问题,虽然有自己的优点,但也有很大的提升空间。
Q:epoch 是不是越大越好?
A:一般不是,初期随着 epoch 的增加会越来越好,但是后期会下滑或者波动很大。所以一般会选择用 early stop 的方式。
>>>> 获取完整PPT和视频实录
关注PaperWeekly微信公众号,回复20180104获取下载链接。
点击以下标题查看往期实录:
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
















 1389
1389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









