







我们写了很多的Java代码,有些代码包括一些设计一看就非常ugly. 所以需要不断总结看看哪些设计更优雅一点(文章参考了阿里的开发规约)。
一、编程规约
命名规范:
1、【强制】类名使用UpperCamelCase风格,必须要使用驼峰形式,不包括:DO/BO/DTO/VO/AO
正例:MarcoPolo / UserDO / UserDTO
2、【强制】常量命名应该全部大写,单词间用下划线隔开,力求语义完整清楚,不要嫌名字太长。
正例:MAX_STOCK_COUNT
3、【强制】抽象类命名使用Abstract或Base开头;异常类命名使用Exception结尾;测试类命名以它要测试的类名称开始,以Test结尾。
4、【强制】POJO类中任何布尔类型的变量都不要加is,否则部分框架解析会引起序列化错误。
反例:不要定义boolean isDeleted这样的属性名称
5、【强制】不允许出现不规范的缩写
反例:<业务代码>AbstractClass 被“缩写” AbsClass; 会降低代码的可读性
6、【推荐】如果使用到了设计模式,建议在类中体现出具体模式
正例:pulic class OrderFactory;
7、【推荐】接口类中方法和属性不要加任何修饰符号(public也不要加),保持代码的简洁性,并加javadoc注解。尽量不要在接口定义变量,如果一定要定义肯定是与接口方法相关,并且是整个应用的基础常量。
8、【参考】枚举类名建议带上Enum后缀,枚举成员名称需要全大写,单词间用下划线隔开。
正例:枚举名字:DealStatusEnum,;成员名称:SUCCESS / UNKOWN_REASON.
9、【参考】各层命名规约:
A) service/dao层方法命名规约
1)获取单个对象的方法用get前缀
2)获取多个对象使用list前缀
3)获取统计数据用count前缀
4)插入用save/insert
5)删除用remove/delete
6)修改用update
B)领域模型命名规约
1)数据对象:xxxDO,xxx即为数据表名
2)数据传输对象:xxxDTO,xxx为业务领域相关的名称
3)展示对象: xxxVO, xxx一般为网页名称
4)POJO是DO/DTO/BO/VO的统称,禁止叫xxxPOJO
常量定义:
1、【强制】不允许任何魔法值(未经定义的常量)直接出现在代码里面。
正例:final String TB_HELLO = ""; 后续引用这个常量值进去
2、【强制】long或Long初始赋值时,必须使用L大写的L,而不能用小写的l ,很容易看成1了。
3、【推荐】不要使用一个常量类管理全部的常量,应该按常量功能进行归类,分开维护。比如缓存相关的常量放在类:CacheConsts下
4、【推荐】常量的复用层次有五层:跨应用共享、应用内共享、子工程内共享、包内共享、类内共享
1)跨应用:打到二方包里面,A中的常量提供B应用使用
2)应用内:放到一方库的modules中constant目录下。
3)子工程:即在当前子工程的constant目录下
4)包内:在当前包中的constant目录下
5)类内共享:直接在类中定义public static final 定义
OOP规约:
1、【强制】避免通过一个类的对象引用访问此类的静态变量或静态方法,无谓增加编译器解析成本,直接用类名访问。
2、【强制】所有覆写方法必须加@Override注解。
3、【强制】相同参数类型,相同业务含义,才可以使用Java的可变参数,避免使用Object.可变参数放在参数列表最后。建议尽量不要使用可变参数编程。
正例:public User getUsers(String type,Integer... ids){}
4、【强制】外部正在调用或二方库依赖的接口,不允许修改方法签名,避免对接口调用产生影响。接口过期必须加@Deprecated注解,并说明采用的新接口或新服务是什么
这里引申了一个问题就是在我们定义接口的时候入参如果参数过多的时候尽量定义一个对象,怕万一后面添加新的入参,得改接口就比较麻烦。
5、【强制】尽量不要使用过时的类或方法
6、【强制】object的equals方法容易抛空指针,推荐使用java.util.Objects#equals(jdk7引入的工具类)
7、【强制】所有相同类型的包装类对象之间的值比较,使用使用equals方法进行比较。
说明:对于Integer var=? 如果是在-128到127之间进行赋值,这个范围内的Integer值是在IntegerCache.cache产生,会复用已有对象,这个范围内的值可以直接使用==进行判断,如果在这个区间之外的所有数据都会在堆上产生并不会复用已有对象,这是一个大坑,使用==就会有大问题,得使用equals.
8、【强制】关于基本数据类型与包装数据类型的使用标准如下:
1)所有POJO类属性必须使用包装数据类型(不要对POJO里面定义基本数据类型切记!)
2)RPC方法的返回值和参数必须使用包装数据类型
3)所有局部变量推荐使用基本数据类型
正例:数据库查询的结果可能为null, 因为自动拆箱,如果用基本数据类型接收会有NPE风险.
9、【强制】定义POJO类时不要设定任何属性的默认值
比如某个DO里面的gmtCreate默认值为new Date(). 这样就会产生一个默认值。
10、【强制】序列化类新增属性时,不要修改serialVersionUID字段,避免反序列失败;如果完全不兼容升级,避免反序列化混乱,那就修改这个值
11、【强制】构造方法里面禁止加入任何业务逻辑,如果有初始化逻辑,放到init方法中。
12、【强制】POJO类必须写toString方法。
13、【推荐】循环体内,字符串联接方法使用StringBuilder的append方法进行扩展。而不要使用 + 进行字符串连接
14、【推荐】慎用Object的clone方法来拷贝对象。
说明 :对象的clone默认是浅拷贝,若想深拷贝则需要重写clone 方法实现属性的拷贝
并发处理:
1、【强制】获取单例对象需要保证线程安全,其中的方法也要保证线程安全。
2、【强制】创建线程或线程池需要指定有意义的名称,方便出错排查
3、【强制】线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。
使用线程池的好处可以减少在创建和销毁线程上所花的时间及资源开销。如果不使用线程池,可能会造成大量的线程创建消耗问题。
4、【强制】线程池不允许使用Executors创建,而是通过ThreadPoolExecutor方式。
5、【强制】SimpleDateFormat是线程不安全的类,一般不要定义成static,如果定义成static,则必须加锁,或者使用DateUtils工具类。
正例:注意线程安全,使用DateUtils.
6、【强制】必须回收自定义的ThreadLocal变量,尤其在线程池场景下,线程会复用,如果不清理自定义ThreadLocal变量可能会影响后续业务逻辑和造成内存泄露问题,尽量在try-finally进行回收。
正例:objectThreadLocal.set(x); try {...} finally{ objectThreadLocal.remove();}
7、【强制】高并发时同步调用应该去考量锁的性能损耗,能用无锁数据结构就不要用锁;;能锁区块就不要锁整个方法体,能用对象锁,就不要用类锁;
说明:让锁的代码块工作量尽可能小。
8、【强制】并发修改同一个记录时,避免更新丢失,要么在应用层加锁、要么在缓存加锁,要么在数据库层加乐观锁,使用version作为更新依据。
说明:如果每次访问冲突概率小于20%,推荐使用乐观锁,否则使用悲观锁。
正例:可以使用tairManager方法:incr(namespace,loclKey,1,0,expireTime);判断返回步长是否为1,实现分布式锁;借助缓存可以实现分布式锁
9、【推荐】资金相关金融信息使用悲观锁策略
10、【参考】HashMap在容量不够进行resize由于高并发可能出现死链,导致CPU飙升。
其他:
1、【强制】避免用apache beanutils进行属性copy
可以使用其他方案如SpringBeanUtils, CglibBeanCopier
2、【强制】后台输送给页面的变量必须加$!{var}
3、【推荐】任何数据结构的构造或初始化,都应指定大小,避免数据结构无限增长把内存吃光。
二、异常日志
异常处理:
1、【强制】异常不要用来控制流程控制,条件控制,因为异常处理效率比较低
2、【强制】对大段代码进行try-catch,这是不负责的表现,catch时请分清稳定代码和非稳定代码。稳定代码是指不论如何都不会出错。对于非稳定的代码也要细分异常类型
3、【强制】捕获了异常就要处理它,如果不想处理就往上抛,让调用方来处理这个异常
4、【强制】事务场景中,抛出异常被catch后,如果需要回滚,一定要手动回滚事务
5、【推荐】防止NPE,是程序员的基本修养,注意NPE产生的场景:
1)返回类型为基本数据类型,return包装数据类型的对象时自动拆箱有可能产生NPE。
2)数据库查询结果可能为null
3)集合的元素即使isNotEmpty但取出来的数据元素也可能是null
4)远程调用返回对象时,一律要做空指针判断
5)对session中获取的数据,建议NPE检查
6)级联调用obj.getA().getB().getC() 易产生NPE
6、【推荐】在代码中使用“抛异常”还是“返回错误码”,对于对外提供的必须使用错码码,而应用内部推荐异常抛出;跨应用间HSF调用优先考虑使用Result方式,封装isSuccess()方法、错误码、错误简短信息。
7、【参考】避免出现重复代码
尽量抽取出来公用模块、公共类、公共方法
三、应用分层
1、【推荐】推荐如下的分层结构
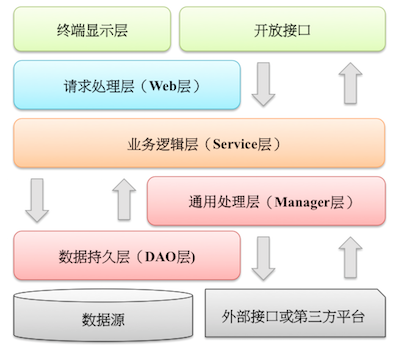
1)开放接口层:可直接封装service接口暴露RPC接口;通过web封装成http接口;网关控制层等;
2)终端显示层:各个端的模板渲染并执行显示层,比如JS渲染、JSP渲染
3)WEB层:主要是对访问控制进行转发,各类基本参数校验
4)service层:相对具体的业务逻辑服务层
5)manager层:通用业务处理层(核心逻辑处理在此层)
a) 对第三方平台封装的层,预处理返回结果及转换异常信息
b) 对service层通用能力下沉,如缓存方案、中间件通用处理(比如定时任务、消息发送)
c) 与DAO交互,对DAO的业务通用能力封装。
6)DAO层:数据访问层,负责写DAL的代码
7)外部接口或第三方平台:包括其他部门的RPC接口,HTTP接口。
说说我的理解:
controller schduleX hsf 服务提供层 这一层需要提供统一的拦截器(对方法的入参做拦截+对异常做统一拦截)
通用业务处理层(Biz)(接口驱动:即事先定义出来接口比如Hsf接口\controller层接口)再封装各种业务Biz业务
领域对象(含DAO\Serivce\Domain层的东西) 【外部系统对接层】管这一层叫manage层比如调用其他系统获取数据
2、【参考】(分层之后的异常规约)在DAO层,产生的异常类型有很多,无法用细粒度异常进行catch,就需要throw new DAOException(e),但不需要打日志,让上层manage/service层进行捕获并打到日志文件里面。这样就可以避免浪费性能和日志存储。
3、【参考】分层领域模型规约:
1)DO:与数据库表结构一、一对应,通过DAO层向上传输数据源对象
2)DTO:数据传输对象,service/manager向外传输的对象(!!!在manage层就是DTO了注意不是DO!)
3)BO:业务对象,可以由service层输出的封装业务逻辑的对象
4)Query: 数据查询对象,各层接收上层的查询请求,超过2个参数的查询封装,禁用map来传输。而是定义对象
5)VO:显示层。通常是WEB向模板渲染引擎传输的对象














 651
651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









