







 本文讲述了如何解决JMeter中request请求体出现乱码的问题,从修改本地配置文件、调整消息头和请求体编码到深入源码分析,最终发现是CHARSET_DECODE配置不一致导致,通过改为UTF-8成功解决。
本文讲述了如何解决JMeter中request请求体出现乱码的问题,从修改本地配置文件、调整消息头和请求体编码到深入源码分析,最终发现是CHARSET_DECODE配置不一致导致,通过改为UTF-8成功解决。
故事背景
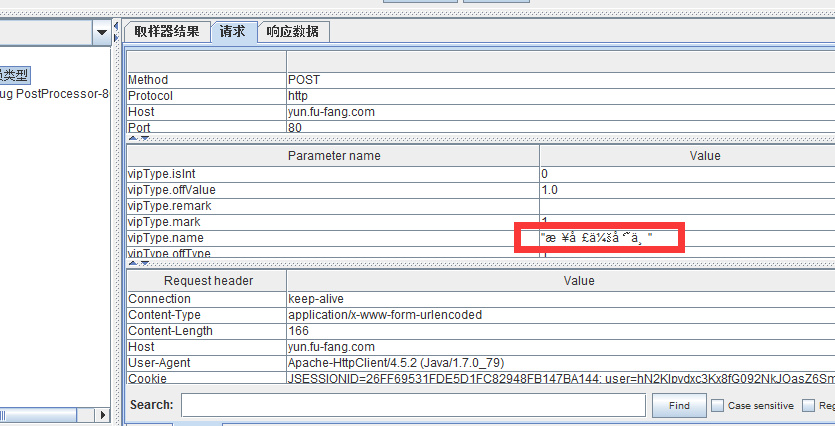
飞测群里有同学,又提了一个乱码的问题—request请求提的乱码。各种配置修改,都不能解决。乱码现象如下图:
解决思路
1、修改本地配置文件
因为此处的数据,还没有发送出去,所以,肯定是这个变量的编码和jmeter内部的一些编码不一致导致。然后,尝试修改jmeter.properties的配置项:
`sampleresult.default.encoding=utf-8`重启jmeter后,依然还是乱码。
2、修改消息头和请求体编码
同时把消息头和请求体的编码修改为utf-8,结果依然不生效。
3、查看jmeter源码
<1>因为是request请求体的内容,所有先在下面的包中进行查看:
org.apache.jmeter 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 822
822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









