







跳表是由William Pugh发明。他在 Communications of the ACM June 1990, 33(6) 668-676 发表了Skip lists: a probabilistic alternative to balanced trees,在该论文中详细解释了跳表的数据结构和插入删除操作。跳跃表使用概率均衡技术而不是使用强制性均衡,因此,对于插入和删除结点比传统上的平衡树算法更为简洁高效。参考算法导论,跳表插入、删除、查找的复杂度均为O(logN)。LevelDB的核心数据结构是用跳表实现的,redis的sorted set数据结构也是用跳表实现的。
下面来研究一下跳表的核心思想:
先从链表开始,如果是一个单链表,那么我们知道在链表中查找一个元素I的话,需要将整个链表遍历一次,时间复杂度为O(n)。

如果是说链表是排序的,并且结点中还存储了指向后面第二个结点的指针的话,那么在查找一个结点时,仅仅需要遍历N/2个结点即可。因为我们可以先通过每个结点最上面的指针先进行查找,这样子就能跳过一半的节点。比如我们想查找19,首先和6比较,大于6之后,在和9进行比较,然后在和12进行比较......最后比较到21的时候,发现21大于19,说明查找的点在17和21之间,从这个过程中,我们可以看出,查找的时候跳过了3、7、12等点,因此查找的时间复杂度为O(n/2)(只是下图的情况)。

其实,上面基本上就是跳跃表的思想,每一个结点不单单只包含指向下一个结点的指针,可能包含很多个指向后续结点的指针,这样就可以跳过一些不必要的结点,从而加快查找、删除等操作。对于一个链表内每一个结点包含多少个指向后续元素的指针,这个过程是通过一个随机函数生成器得到,这样子就构成了一个跳跃表。这就是为什么论文“Skip Lists : A Probabilistic Alternative to Balanced Trees ”中有“概率”的原因了,就是通过随机生成一个结点中指向后续结点的指针数目。随机生成的跳跃表可能如下图所示。

如果一个结点存在k个指向后续元素指针的话,那么称该结点是一个k层结点。一个跳表的层MaxLevel义为跳表中所有结点中最大的层数。跳表的所有操作均从上向下逐层进行,越上层一次next操作的跨度越大。
二.skiplist原理
为了描述方便,将跳表结构绘画成如下形式。
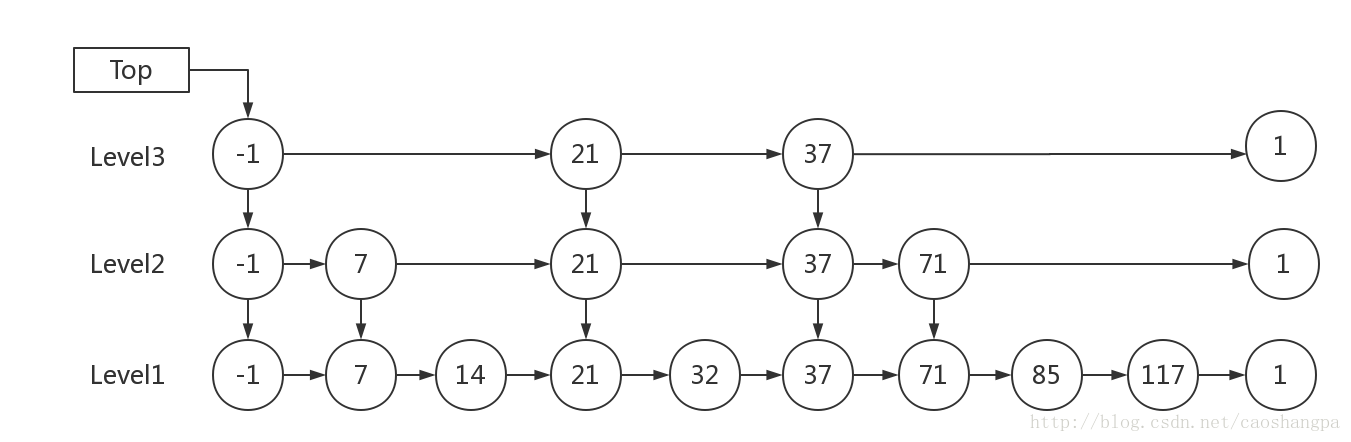
跳表结构:
(1) 由多层结构组成
(2) 每一层都是一个有序的链表
(3) 最底层(Level 1)的链表包含所有元素
(4) 如果一个元素出现在 Level i 的链表中,则它在 Level i 之下的链表也都会出现。
(5) 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。
1.跳表的查找
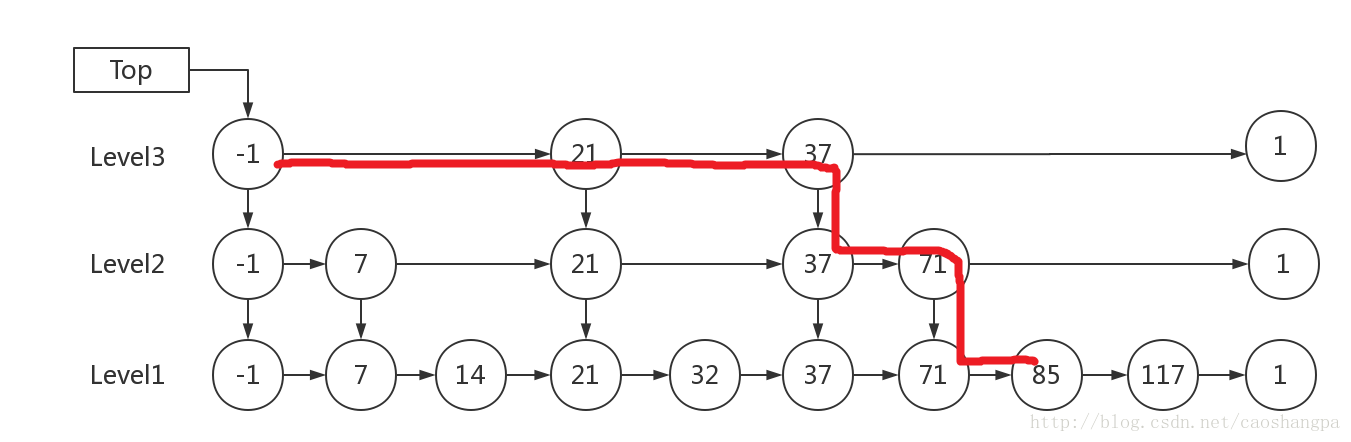
例子:查找元素 117
(1) 比较 21, 比 21 大,往后面找
(2) 比较 37, 比 37大,比链表最大值小,从 37 的下面一层开始找
(3) 比较 71, 比 71 大,比链表最大值小,从 71 的下面一层开始找
(4) 比较 85, 比 85 大,从后面找
(5) 比较 117, 等于 117, 找到了节点。
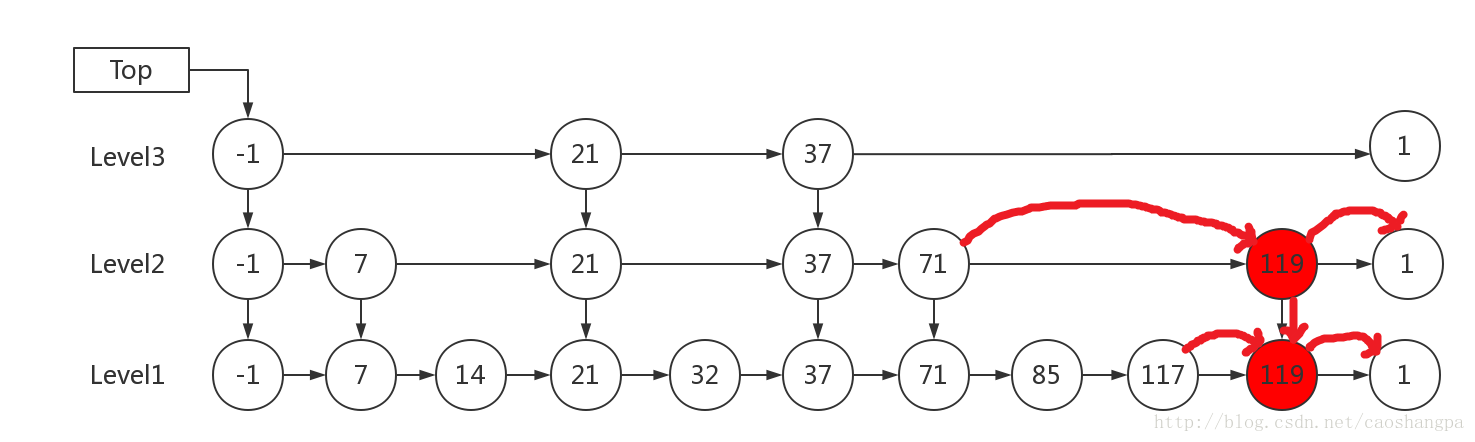
2.跳表的插入
1)K小于链表的层数
先确定该元素要占据的层数 K(采用丢硬币的方式,这完全是随机的),然后在 Level 1 ... Level K 各个层的链表都插入元素。
例子:插入 119, K = 2
2)K大于链表的层数
如果 K 大于链表的层数,则要添加新的层。
例子:插入 119, K = 4
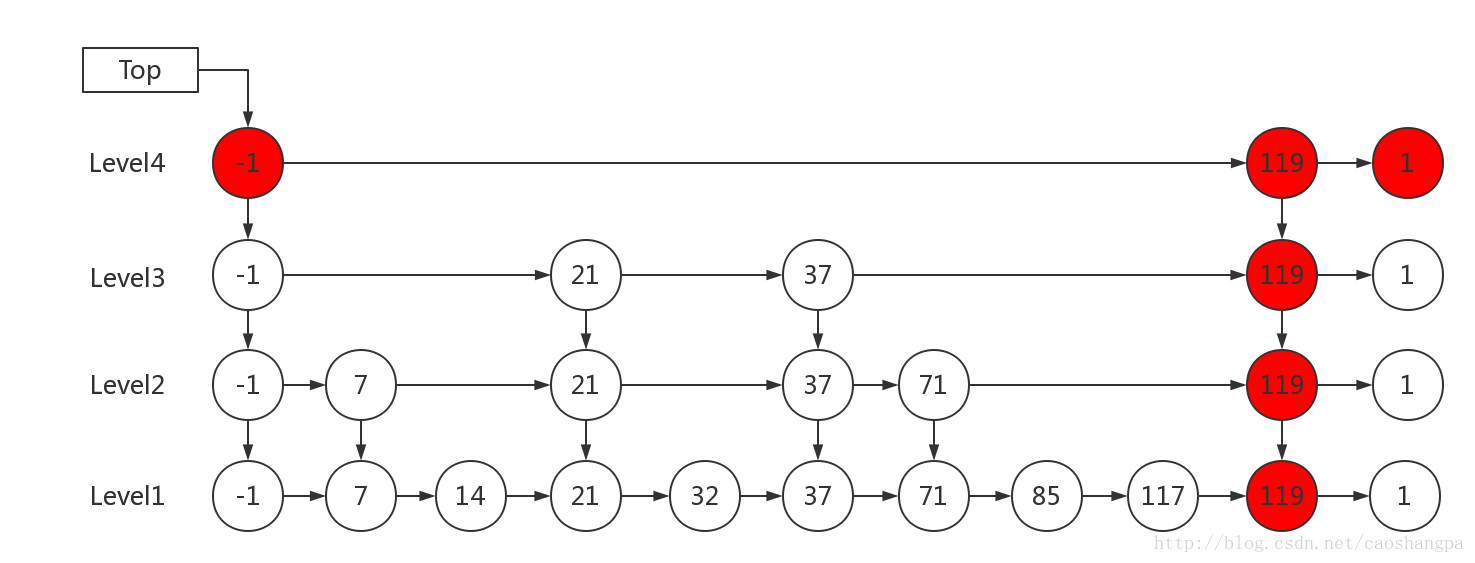
插入元素的时候,元素所占有的层数完全是随机的,通过某种随机算法产生。
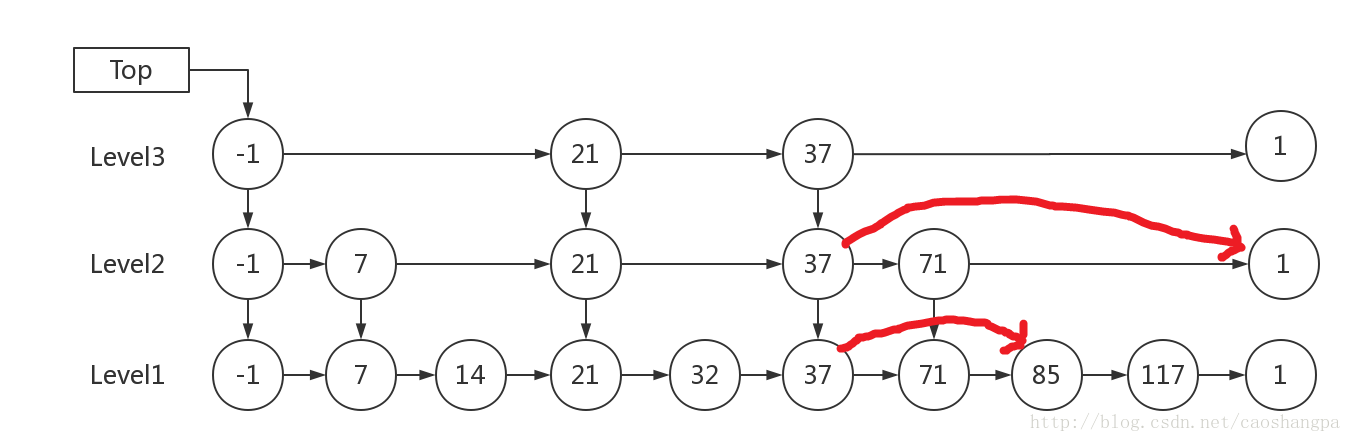
3.跳表的删除
在各个层中找到包含 x 的节点,使用标准的 delete from list 方法删除该节点。
例子:删除 71
三.简单的skiplist实现
#include<stdio.h>
#include<stdlib.h>
#define MAX_LEVEL 10 //最大层数
//结点
typedef struct nodeStructure
{
int key;
int value;
//指针数组
//定义 int *p[n];[]优先级高,先与p结合成为一个数组,再由int*说明这是一个整型指针数组,它有n个指针类型的数组元素。
//这里执行p + 1时,则p指向下一个数组元素,这样赋值是错误的:p = a;因为p是个不可知的表示,只存在p[0]、p[1]、p[2]
//...p[n - 1], 而且它们分别是指针变量可以用来存放变量地址。但可以这样 *p = a; 这里*p表示指针数组第一个元素的值,
//即a的首地址的值。
//这里定义了一个变长指针数组,数组中默认只有一个元素nodeStructure*。使用变长数组(柔性数组)的目的是为了后续对
//该数组扩容,达到动态分配内存,节约空间的目的。
struct nodeStructure *next[1];
}nodeStructure;
//跳表
typedef struct skiplist
{
int level;
nodeStructure *header;
}skiplist;
//创建结点
nodeStructure* createNode(int level, int key, int value)
{
// nodeStructure::next是一个变长数组,额外分配时为什么是level-1倍呢?
// 因为这里是为了兼容性变长数组声明为struct nodeStructure *next[1];(也可以用next[0],但是有些编译器不支持)
// 所以nodeStructure自身已经占了一个,再添加level-1个即可,如果是next[0]的话,就不能减一了。
nodeStructure *ns = (nodeStructure *)malloc(sizeof(nodeStructure) + (level-1)*sizeof(nodeStructure*));
ns->key = key;
ns->value = value;
return ns;
}
//初始化跳表
skiplist* createSkiplist()
{
skiplist *sl = (skiplist *)malloc(sizeof(skiplist));
sl->level = 0;
sl->header = createNode(MAX_LEVEL , 0, 0);
for (int i = 0; i < MAX_LEVEL; i++)
{
sl->header->next[i] = NULL;
}
return sl;
}
//随机产生层数
int randomLevel()
{
int k = 1;
while (rand() % 2)
k++;
k = (k < MAX_LEVEL) ? k : MAX_LEVEL;
return k;
}
//插入节点
bool insert(skiplist *sl, int key, int value)
{
nodeStructure *update[MAX_LEVEL];
nodeStructure *p, *q = NULL;
p = sl->header;
int k = sl->level;
//这里还是查找插入位置阶段,并未开始插入
//从最高层往下,每层都查找插入位置,当遍历到该层的尾部(p->next[i]==NULL)
//也没有找到比key大的结点时,将该层的最后一个结点的指针放到update[i]中。
//如果在某层中找到了比key大或等于key的结点时,将该结点之前的那个比key小的结点的指针
//放到update[i]中。
//这样一来,参考(二.skiplist原理中的跳表插入章节图),以插入119为例,因为此时k暂时是最大层数,
//update[i]存放的是37、71和117所在结点的指针。
for (int i = k - 1; i >= 0; i--){
while ((q = p->next[i]) && (q->key < key))
{
p = q;
}
update[i] = p;
}
//不能插入相同的key,这里排除掉了上述等于key的情况。
//此时q是第一层中的某个结点。
if (q&&q->key == key)
{
return false;
}
//产生一个随机层数k
k = randomLevel();
//更新跳表的level,这里假设k=sl->level+1,参考(二.skiplist原理中的跳表插入章节图),以插入119为例,
//update[3]应该直接等于新增那层头结点的指针,就像下面代码写的那样。
if (k > (sl->level))
{
for (int i = sl->level; i < k; i++){
update[i] = sl->header;
}
sl->level = k;
}
//新建一个待插入结点q,从低到高一层层插入
q = createNode(k, key, value);
//逐层更新结点的指针,和普通链表插入一样
for (int i = 0; i < k; i++)
{
q->next[i] = update[i]->next[i];
update[i]->next[i] = q;
}
return true;
}
//搜索指定key的value
int search(skiplist *sl, int key)
{
nodeStructure *p, *q = NULL;
p = sl->header;
//从最高层往下开始搜索
int k = sl->level;
for (int i = k - 1; i >= 0; i--){
while ((q = p->next[i]) && (q->key <= key))
{
if (q->key == key)
{
return q->value;
}
p = q;
}
}
return NULL;
}
//删除指定的key
bool deleteSL(skiplist *sl, int key)
{
nodeStructure *update[MAX_LEVEL];
nodeStructure *p, *q = NULL;
p = sl->header;
//从最高层往下开始搜索
int k = sl->level;
for (int i = k - 1; i >= 0; i--){
while ((q = p->next[i]) && (q->key < key))
{
p = q;
}
update[i] = p;
}
//这里和插入类似,只不过找到该结点后删除
if (q&&q->key == key)
{
//逐层删除,和普通链表删除一样
for (int i = 0; i < sl->level; i++){
if (update[i]->next[i] == q){
update[i]->next[i] = q->next[i];
}
}
free(q);
//如果某些层只有被删除的这个结点,那么需要更新跳表的level
for (int i = sl->level - 1; i >= 0; i--){
if (sl->header->next[i] == NULL){
sl->level--;
}
}
return true;
}
else
{
return false;
}
}
//释放跳表,虽然每个结点分了很多层,单归根结底是一个结点,所以和单链表的释放是一样的。
void freeSL(skiplist *sl)
{
if (!sl)
return;
nodeStructure *p, *q = NULL;
p = sl->header;
while (p)
{
q = p->next[0];
free(p);
p = q;
}
free(sl);
}
void printSL(skiplist *sl)
{
//从最高层开始打印
nodeStructure *p, *q = NULL;
int k = sl->level;
for (int i = k - 1; i >= 0; i--)
{
p = sl->header;
while (1)
{
q = p->next[i];
printf("%d -> ", p->value);
p = q;
if (p==NULL)
{
break;
}
}
printf("\n");
}
printf("\n");
}
int main()
{
skiplist *sl = createSkiplist();
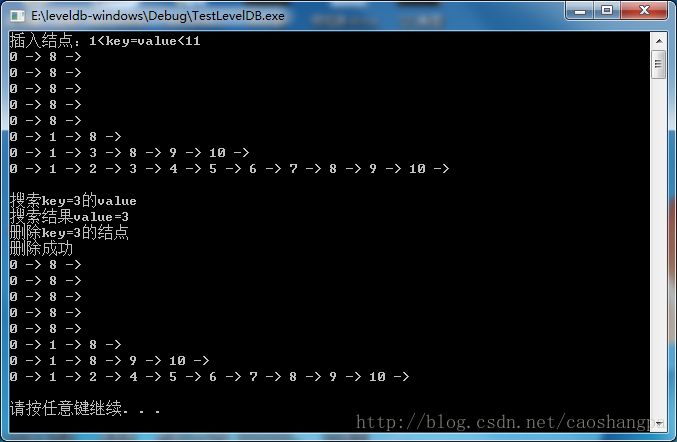
printf("插入结点:1<key=value<11\n");
for (int i = 1; i < 11; i++)
{
insert(sl, i, i);
}
printSL(sl);
//搜索
printf("搜索key=3的value\n");
int i = search(sl, 3);
printf("搜索结果value=%d\n",i);
//删除
printf("删除key=3的结点\n");
bool b = deleteSL(sl, 3);
if (b)
{
printf("删除成功\n");
}
printSL(sl);
freeSL(sl);
system("pause");
return 0;
}
参考链接:http://kenby.iteye.com/blog/1187303
参考链接:http://dsqiu.iteye.com/blog/1705530
参考链接:http://www.cnblogs.com/xuqiang/archive/2011/05/22/2053516.html















 1194
1194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











