







LevelDB中log文件在LevelDB中的主要作用是系统故障恢复时,能够保证不会丢失数据。因为在将记录写入内存的Memtable之前,会先写入Log文件,这样即使系统发生故障,Memtable中的数据没有来得及Dump到磁盘的SSTable文件,LevelDB也可以根据log文件恢复内存的Memtable数据结构内容,不会造成系统丢失数据。
参考链接: http://blog.csdn.net/tankles/article/details/7663873
下面我们带大家看看log文件的具体物理和逻辑布局是怎样的,LevelDB对于一个log文件,会把它切割成以32K为单位的物理Block,每次读取的单位以一个Block作为基本读取单位,下图展示的log文件由3个Block构成,所以从物理布局来讲,一个log文件就是由连续的32K大小Block构成的。
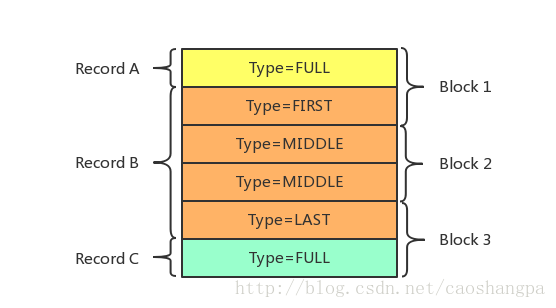
在应用的视野里是看不到这些Block的,应用看到的是一系列的Key/Value对,在LevelDB内部,会将一个Key/Value对看做一条记录的数据,另外在这个数据前增加一个记录头,用来记载一些管理信息,以方便内部处理,下图显示了一个记录在LevelDB内部是如何表示的。
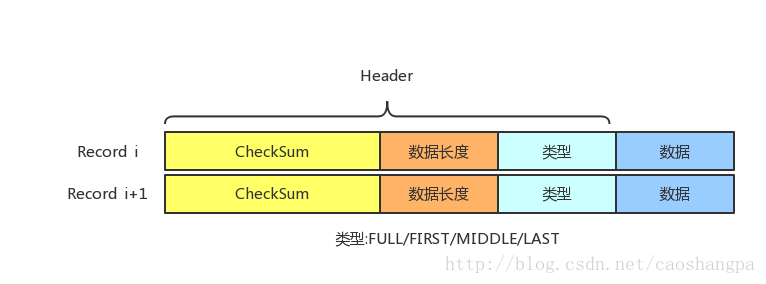
一.log文件的格式
namespace log {
// 记录的类型
enum RecordType {
// 保留位,用于预分配的文件
kZeroType = 0,
// 整个存储
kFullType = 1,
// 分段存储
kFirstType = 2,
kMiddleType = 3,
kLastType = 4
};
static const int kMaxRecordType = kLastType;
// 32K
static const int kBlockSize = 32768;
// Header is checksum (4 bytes), type (1 byte), length (2 bytes).
// chcksum是类型和数据字段的校验码,type是记录类型,length是数据字段的长度。
static const int kHeaderSize = 4 + 1 + 2;
}二.log文件的写
Writer类的头文件很简单,看下cpp文件
namespace log {
Writer::Writer(WritableFile* dest)
: dest_(dest),
block_offset_(0) {// block_offset_
// 分别校验所有类型,并把校验码存储到数组type_crc_中
// 放在构造函数里提前计算类型的校验码,是为了减少运行中计算时的性能损耗
for (int i = 0; i <= kMaxRecordType; i++) {
// 这里直接将int转换为char,因为int的值较小,不会造成精度丢失
char t = static_cast<char>(i);
type_crc_[i] = crc32c::Value(&t, 1);
}
}
Writer::~Writer() {
}
Status Writer::AddRecord(const Slice& slice) {
const char* ptr = slice.data();
size_t left = slice.size();
// Fragment the record if necessary and emit it. Note that if slice
// is empty, we still want to iterate once to emit a single
// zero-length record
Status s;
bool begin = true;
do {
const int leftover = kBlockSize - block_offset_;
assert(leftover >= 0);
// 如果当前Block中剩下的容量leftover小于kHeaderSize的大小
// 则将剩下的容量填充空字符,因为leftover小于kHeaderSize
// 所以最多只能填充六个空字符,当leftover大于等于kHeaderSize时,
// Slice会自行截断
if (leftover < kHeaderSize) {
if (leftover > 0) {
// Fill the trailer (literal below relies on kHeaderSize being 7)
assert(kHeaderSize == 7);
dest_->Append(Slice("\x00\x00\x00\x00\x00\x00", leftover));
}
// 切换到一个新的Block
block_offset_ = 0;
}
// Invariant: we never leave < kHeaderSize bytes in a block.
assert(kBlockSize - block_offset_ - kHeaderSize >= 0);
// 如果当前Block中剩下的容量leftover大于等于kHeaderSize的大小
// 则leftover-kHeaderSize为可用大小,即avail
const size_t avail = kBlockSize - block_offset_ - kHeaderSize;
const size_t fragment_length = (left < avail) ? left : avail;
// 如果新的slice小于avail,则该slice可用整个添加到当前Block中,
// 不需要分段,此时type=kFullType
// 如果slice大于等于avail,则该slice需要分段存储,如果是第一段
// type = kFirstType,如果是最后一段type = kLastType,否则type = kMiddleType
RecordType type;
const bool end = (left == fragment_length);
if (begin && end) {
type = kFullType;
} else if (begin) {
type = kFirstType;
} else if (end) {
type = kLastType;
} else {
type = kMiddleType;
}
// 将数据组建成指定格式后存储到磁盘
s = EmitPhysicalRecord(type, ptr, fragment_length);
ptr += fragment_length;
left -= fragment_length;
begin = false;
} while (s.ok() && left > 0);
return s;
}
Status Writer::EmitPhysicalRecord(RecordType t, const char* ptr, size_t n) {
assert(n <= 0xffff); // 最大为两个字节
assert(block_offset_ + kHeaderSize + n <= kBlockSize);
// Format the header
char buf[kHeaderSize];
// 长度的低位放到数组的第五个字节
// 长度的高位放到数组的第六个字节
buf[4] = static_cast<char>(n & 0xff);
buf[5] = static_cast<char>(n >> 8);
// 类型放到数组的第七个字节
buf[6] = static_cast<char>(t);
// Compute the crc of the record type and the payload.
uint32_t crc = crc32c::Extend(type_crc_[t], ptr, n);
crc = crc32c::Mask(crc); // Adjust for storage
// 1.添加校验码到header中(包括类型字段和数据字段的校验)
EncodeFixed32(buf, crc);
// 2.添加header
// Write the header and the payload
Status s = dest_->Append(Slice(buf, kHeaderSize));
if (s.ok()) {
// 3.添加数据
s = dest_->Append(Slice(ptr, n));
if (s.ok()) {
// 写入到磁盘
s = dest_->Flush();
}
}
// 偏移的自增
block_offset_ += kHeaderSize + n;
return s;
}
}Reader类的头文件
namespace log {
class Reader {
public:
// 报告错误的接口
class Reporter {
public:
virtual ~Reporter();
// 如果有损坏被检测到,那么bytes就是由于检测到的损坏而丢失大概字节数
virtual void Corruption(size_t bytes, const Status& status) = 0;
};
// Reader的功能时从log文件中读取记录
// 如果reporter不是NULL,只要有一些数据由于检测到的损坏而丢失,就会通知它。
// 如果“校验和”为真,则验证校验和是否可用。
// Reader会从文件内物理位置大于等于initial_offset的第一条记录开始读
Reader(SequentialFile* file, Reporter* reporter, bool checksum,
uint64_t initial_offset);
~Reader();
// 读取下一个记录到*record中,*scratch用于临时存储
bool ReadRecord(Slice* record, std::string* scratch);
// 返回上一条记录的物理偏移
// 在第一次调用ReadRecord前调用该函数是无定义的。
// 因此要在ReadRecord之后调用该函数。
uint64_t LastRecordOffset();
private:
SequentialFile* const file_;
// 数据损坏报告
Reporter* const reporter_;
// 是否进行数据校验
bool const checksum_;
// read以Block为单位去从磁盘取数据,取完数据就是存在blocking_store_里面,
// 其实就是读取数据的buffer
char* const backing_store_;
// 指向blocking_store_的slice对象,方便对blocking_store_的操作
Slice buffer_;
// 是否到了文件尾
bool eof_;
// 上一条记录的偏移
uint64_t last_record_offset_;
// 当前Block的结束位置的偏移
uint64_t end_of_buffer_offset_;
// 初始Offset,从该偏移出查找第一条记录
uint64_t const initial_offset_;
// 这些特殊值是记录类型的扩展
enum {
kEof = kMaxRecordType + 1,
// Returned whenever we find an invalid physical record.
// Currently there are three situations in which this happens:
// * The record has an invalid CRC (ReadPhysicalRecord reports a drop)
// * The record is a 0-length record (No drop is reported)
// * The record is below constructor's initial_offset (No drop is reported)
kBadRecord = kMaxRecordType + 2
};
// 跳过"initial_offset_"之前的所有Block.
bool SkipToInitialBlock();
// 读取一条记录中的数据字段,存储在result中,返回记录类型或者上面的特殊值之一
unsigned int ReadPhysicalRecord(Slice* result);
// 将损坏的字节数报告给reporter.
void ReportCorruption(size_t bytes, const char* reason);
void ReportDrop(size_t bytes, const Status& reason);
// No copying allowed
Reader(const Reader&);
void operator=(const Reader&);
};
}namespace log {
Reader::Reporter::~Reporter() {
}
Reader::Reader(SequentialFile* file, Reporter* reporter, bool checksum,
uint64_t initial_offset)
: file_(file),
reporter_(reporter),
checksum_(checksum),
backing_store_(new char[kBlockSize]),
buffer_(),
eof_(false),
last_record_offset_(0),
end_of_buffer_offset_(0),
initial_offset_(initial_offset) {
}
Reader::~Reader() {
delete[] backing_store_;
}
bool Reader::SkipToInitialBlock() {
// 构造时传入的initial_offset大于等于kBlockSize,则block_start_location
// 是第(initial_offset_ / kBlockSize)+1个Block起始位置的偏移。
// 当initial_offset比kBlockSize小时,则block_start_location是第1个Block
// 起始位置的偏移
size_t offset_in_block = initial_offset_ % kBlockSize;
uint64_t block_start_location = initial_offset_ - offset_in_block;
// offset_in_block > kBlockSize - 6,说明已经到了一个Block的尾部,
// 尾部填充的是6个空字符。此时只能定位到下一个Block的开头。
if (offset_in_block > kBlockSize - 6) {
offset_in_block = 0;
block_start_location += kBlockSize;
}
end_of_buffer_offset_ = block_start_location;
// 如果block_start_location大于0,则文件中应该跳过block_start_location
// 个字节,到达目标Block的开头。否则将数据损坏信息打印到LOG文件。
if (block_start_location > 0) {
Status skip_status = file_->Skip(block_start_location);
if (!skip_status.ok()) {
ReportDrop(block_start_location, skip_status);
return false;
}
}
return true;
}
bool Reader::ReadRecord(Slice* record, std::string* scratch) {
if (last_record_offset_ < initial_offset_) {
if (!SkipToInitialBlock()) {
return false;
}
}
scratch->clear();
record->clear();
// 是否是分段的记录
bool in_fragmented_record = false;
// 当前读取的记录的逻辑偏移
uint64_t prospective_record_offset = 0;
Slice fragment;
while (true) {
// buffer_会在ReadPhysicalRecord中自偏移,实际上buffer_中存储的是当前Block
// 还未解析的记录,而end_of_buffer_offset_是当前Block的结束位置的偏移
uint64_t physical_record_offset = end_of_buffer_offset_ - buffer_.size();
const unsigned int record_type = ReadPhysicalRecord(&fragment);
switch (record_type) {
case kFullType:
if (in_fragmented_record) {
// Handle bug in earlier versions of log::Writer where
// it could emit an empty kFirstType record at the tail end
// of a block followed by a kFullType or kFirstType record
// at the beginning of the next block.
if (scratch->empty()) {
in_fragmented_record = false;
} else {
ReportCorruption(scratch->size(), "partial record without end(1)");
}
}
// 当为kFullType时,物理记录和逻辑记录1:1的关系,所以offset也是一样的
prospective_record_offset = physical_record_offset;
scratch->clear();
*record = fragment;
last_record_offset_ = prospective_record_offset;
return true;
case kFirstType:
if (in_fragmented_record) {
// Handle bug in earlier versions of log::Writer where
// it could emit an empty kFirstType record at the tail end
// of a block followed by a kFullType or kFirstType record
// at the beginning of the next block.
if (scratch->empty()) {
in_fragmented_record = false;
} else {
ReportCorruption(scratch->size(), "partial record without end(2)");
}
}
// 因为是第一分段,所以物理记录的offset,也是逻辑记录的offset
// 注意第一个分段用的是assign添加到scratch
prospective_record_offset = physical_record_offset;
scratch->assign(fragment.data(), fragment.size());
in_fragmented_record = true;
break;
case kMiddleType:
if (!in_fragmented_record) {
ReportCorruption(fragment.size(),
"missing start of fragmented record(1)");
} else {
scratch->append(fragment.data(), fragment.size());
}
break;
case kLastType:
if (!in_fragmented_record) {
ReportCorruption(fragment.size(),
"missing start of fragmented record(2)");
} else {
scratch->append(fragment.data(), fragment.size());
*record = Slice(*scratch);
// 逻辑记录结束,更新最近一条逻辑记录的offset
last_record_offset_ = prospective_record_offset;
return true;
}
break;
case kEof:
if (in_fragmented_record) {
ReportCorruption(scratch->size(), "partial record without end(3)");
scratch->clear();
}
return false;
case kBadRecord:
if (in_fragmented_record) {
ReportCorruption(scratch->size(), "error in middle of record");
in_fragmented_record = false;
scratch->clear();
}
break;
default: {
char buf[40];
snprintf(buf, sizeof(buf), "unknown record type %u", record_type);
ReportCorruption(
(fragment.size() + (in_fragmented_record ? scratch->size() : 0)),
buf);
in_fragmented_record = false;
scratch->clear();
break;
}
}
}
return false;
}
uint64_t Reader::LastRecordOffset() {
return last_record_offset_;
}
void Reader::ReportCorruption(size_t bytes, const char* reason) {
ReportDrop(bytes, Status::Corruption(reason));
}
void Reader::ReportDrop(size_t bytes, const Status& reason) {
if (reporter_ != NULL &&
end_of_buffer_offset_ - buffer_.size() - bytes >= initial_offset_) {
reporter_->Corruption(bytes, reason);
}
}
unsigned int Reader::ReadPhysicalRecord(Slice* result) {
while (true) {
// 两种情况下该条件成立
// 1.出现在第一次read,因为buffer_在reader的构造函数里是初始化空
// 2.当前buffer_的内容为Block尾部的6个空字符,这时实际上当前Block
// 以及解析完了,准备解析下一个Block
if (buffer_.size() < kHeaderSize) {
if (!eof_) {
// 清空buffer_,存储下一个Block
buffer_.clear();
// 从文件中每次读取一个Block,Read内部会做偏移,保证按顺序读取
Status status = file_->Read(kBlockSize, &buffer_, backing_store_);
// 当前Block结束位置的偏移
end_of_buffer_offset_ += buffer_.size();
// 读取失败,打印LOG信息,并将eof_设置为true,终止log文件的解析
if (!status.ok()) {
buffer_.clear();
ReportDrop(kBlockSize, status);
eof_ = true;
return kEof;
// 如果读到的数据小于kBlockSize,也说明到了文件结尾,eof_设为true
} else if (buffer_.size() < kBlockSize) {
eof_ = true;
}
// 跳过后面的解析,因为buffer_.size() < kHeaderSize时,buffer是无法解析的
continue;
} else if (buffer_.size() == 0) {
// 如果eof_为false,但是buffer_.size,说明遇到了Bad Record,也应该终止log文件的解析
return kEof;
} else {
// 如果最后一个Block的大小刚好为kBlockSize,且结尾为6个空字符
size_t drop_size = buffer_.size();
buffer_.clear();
ReportCorruption(drop_size, "truncated record at end of file");
return kEof;
}
}
// Parse the header
const char* header = buffer_.data();
const uint32_t a = static_cast<uint32_t>(header[4]) & 0xff;
const uint32_t b = static_cast<uint32_t>(header[5]) & 0xff;
const unsigned int type = header[6];
const uint32_t length = a | (b << 8);
// 一个Block里放不下一条记录,显示是Bad Record
if (kHeaderSize + length > buffer_.size()) {
size_t drop_size = buffer_.size();
buffer_.clear();
ReportCorruption(drop_size, "bad record length");
return kBadRecord;
}
// 长度为0的记录,显然也是Bad Record
if (type == kZeroType && length == 0) {
// Skip zero length record without reporting any drops since
// such records are produced by the mmap based writing code in
// env_posix.cc that preallocates file regions.
buffer_.clear();
return kBadRecord;
}
// 如果校验失败,也是Bad Record
if (checksum_) {
uint32_t expected_crc = crc32c::Unmask(DecodeFixed32(header));
uint32_t actual_crc = crc32c::Value(header + 6, 1 + length);
if (actual_crc != expected_crc) {
// Drop the rest of the buffer since "length" itself may have
// been corrupted and if we trust it, we could find some
// fragment of a real log record that just happens to look
// like a valid log record.
size_t drop_size = buffer_.size();
buffer_.clear();
ReportCorruption(drop_size, "checksum mismatch");
return kBadRecord;
}
}
// buffer_的自偏移
buffer_.remove_prefix(kHeaderSize + length);
// 这样的记录也是Bad Record,不解释了,太明显
if (end_of_buffer_offset_ - buffer_.size() - kHeaderSize - length <
initial_offset_) {
result->clear();
return kBadRecord;
}
// 取出记录中的数据字段
*result = Slice(header + kHeaderSize, length);
return type;
}
}
}参考链接: http://blog.csdn.net/tankles/article/details/7663873















 516
516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











