









第一章:计算机系统漫游
信息是什么?昨天和同学走的时候,正好就说起了这个话题,“信息就是概率”,同学如是说。那么信息在计算机里是什么呢?总不能还说是概率吧,计算机可不懂什么概率。
在本书第一章第一页的标题上赫然写着“信息就是位+上下文”。什么是位?位就是比特,就是二进制。计算机里没有概率,有的只是一连串0或1的序列。那什么是上下文?这个跟我们经常在英文阅读理解里遇到的“上下文”是差不多的,举个例子,二进制数10000011,对应十六进制的0x83,对应十进制的131,尽管在计算机里存的是10000011,但根据不同的“上下文”,却有着不同的含义,若把它当作指令,则表示“add”,是对两个操作数求和,若把它当作short短整型,则表示131,它还有可能是double型的一部分……总之,计算机里实实在在存的都是一些二进制码,应该把它解释成什么,则要根据“语境”。
第一章中我认为比较重要的有两个部分,一个是可执行程序的诞生过程,描述由一个高级语言源文件(比如C、C++或Java文件)经过加工走到可执行程序的过程;另一个是操作系统存放数据的位置,比如堆和栈等,这个在面试中常常作为操作系统的基础知识去考察,若这个也不清楚的话,面试官就认为你一点也不懂操作系统了。
先谈谈一个可执行程序的诞生过程。现在有了很方便的IDE(集成开发环境),比如我们常用的Visual Studio(简称VS),还有eclipse等等,已经淡化了从一个文本文件到可执行程序的过程。初学者在VS环境下输入代码,然后单击编译连接按钮:
若没有语法错,可执行程序就生成完毕了,却不知这个按钮按下后,发生了哪些事情。

如上图所示,现在编程大部分都是用高级语言(因为可移植性好,自己和别的程序猿也容易看的懂),我们在称之为源文件的地方书写代码,如下图所示。

以主流的C/C++为例,若是用C语言写的源文件(source program),源文件后缀一般是.c,若是用C++语言写的源文件,则后缀一般是.cpp(不要小看这个后缀,有时调程序时,出现很多离奇的错误往往就是这个后缀造成的,因为如果你用.c作为后缀,那么当你的程序里出现了class等关键字的时候,编译器就认不出来了,另外,C语言的行文要求也比C++严格,C++语法通过的地方,C可能反而通不过)。
在编译器编译前,其实还有一个预编译(pre-process)的过程,在预编译时,宏会被展开,一些常义变量也会被替换为常量。这里就多谈谈预编译的问题:关于宏定义,一定要多写写括号,不然展开就会有问题,比如
#define HELLO 3+5
这个看似和定义
#define HELLO 8
差不多,其实差远了,请看
…
int hi = HELLO *3;
…
现在问hi是什么?是24吗?我们不妨展开来看,预编译器是这样做的:
int hi = 3 + 5 * 3
hi其实是18!
这个问题看似比较简单,但却是笔试题中常考的地方。
还有常义变量,比如
const int count = 3;
…
int *p = (int*)&count;
*p = 5;
cout << count << “ ” << *p << endl;
…
现在问输出的是什么?这是今年中兴笔试的题(类似,具体数字忘了),老实说,这道题我当时纠结了不少时间,总是觉得*p = 5 会报错,其实不然。程序是可以执行的,且输出一个是3,一个是5,为什么会这样?
原来这是一个常量替换(更正式的说法是常量折叠),在预编译时,count就被替换为3了,所以输出的语句实际上早就变成了
cout << 3 << “ “ << *p << endl;
那为什么可以修改常量的值?这是因为强制类型转换将const int* 转成了 int*。
言归正传,由预处理器生成的文件是hello.i,接下来交由编译器来编译,编译后得到汇编程序文件hello.s,汇编程序与机器码已经可以一一对应了,汇编器将汇编程序文件转成目标文件hello.o,在hello中还会使用到来自本程序“外部”的函数,比如printf,它位于系统提供的库中,外部库也有目标文件,比如这里的printf.o,链接器将hello.o和printf.o链接到一起生成可执行的二进制文件(在windows下一般是用.exe结尾的,但在linux下不一定,取决于你的定义,这里就直接是hello了,在linux环境中当前目录的命令行下输入“./hello”,就可以执行这个程序了)。再宏观地看一眼这个流程,我们程序员可以看懂的文件(ASCII码文件)包括高级语言源文件(如hello.c)、预编译文件(如hello.i)和汇编程序文件(如hello.s),看不懂的文件(二进制文件,打开后都是乱码)包括目标文件(如hello.o)和可执行程序文件(如hello)。
最后谈谈操作系统的基础知识,也就是程序内存中的分布,以windows操作系统为例,地址空间从高到低依次是数据段、代码段、堆和栈。数据段存放程序的全局变量和静态变量,堆存放动态分配的内存(在C++中是new出来的内存,C中是malloc出来的内存),代码段顾名思义是存放程序的机器码,栈则存放局部的变量。在360面试的时候,面试官就问栈的生长方向,是向低地址区生长还是高地址区生长?即对一个栈push(x)后再push(y),x和y在内存中的地址孰高孰低?这个需要记忆一下,栈在堆的下面(“下”表示地址更低),且栈是向低地址方向生长,而堆在栈的上面(“上“表示地址更高),且堆是向高地址方向生长,两者生长方向是背离的。注意linux的内存分布与windows不同。
下面在VS中验证win32环境下的内存分布,代码如下:

1 int main() 2 { 3 int b = 3; // 栈 4 int *c = new int[2]; // 堆 5 6 // 输出观察地址空间 7 cout << "静态变量地址 " << &a << endl; 8 cout << "全局变量地址 " << &d << endl; 9 cout << "常量地址(与代段存在一起)" << &hello << endl; 10 cout << "栈地址 " << &b << endl; 11 cout << "堆地址1 " << &c[0] << "堆地址2 " << &c[1]<<endl; 12 delete [] c; 13 14 int ss = 4; 15 int sss = 5; 16 cout << "第一个栈元素地址 " << &ss << endl; 17 cout << "第二个栈元素地址 " << &sss << endl; 18 }
运行结果为:
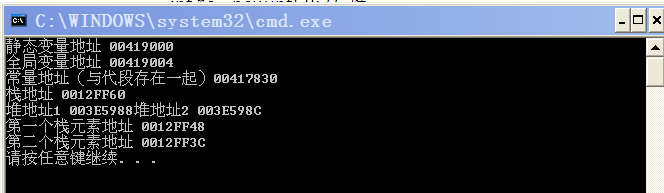
转自 http://www.cnblogs.com/jerry19880126/
另在linux试验下ss的地址也大于sss的地址,但是我在compilr.com上运行的结果却不一致,供大家参考:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









