







文章主要内容:
本文旨在为读者提供不同算法的原理以及效果的直观展示,并希望读者能够在实际问题中更合理地选用梯度下降法。
文章结构:
1. 简介:梯度下降法
2. 随机梯度下降法
3. 随机梯度下降的问题与挑战
4. 随机梯度下降的优化算法(主要内容)
5. 并行与分布式架构
6. 随机梯度下降的其他优化方法
正文
1 梯度下降法
如果
J(θ)
是一个多元函数,在
θ0
点附近对
J(θ)
做线性逼近
这个线性逼近不能告诉我们极值点在什么地方,他只能告诉我们极值点在什么方向,所以我们只能选取一个比较“小”的学习率 η 来沿着这个方向走下去,并得到梯度下降的序列:
困难:
(1)梯度的计算:在机器学习和统计参数估计问题中目标函数通常是求和函数的形式:
其中每一个函数 Jxi(θ) 都对应于一个样本 xi ,当样本量极大时,梯度的计算就变得非常耗时耗力。
(2)学习率的选择:学习率选择过小会导致收敛太慢,学习率选择过大容易导致算法不收敛。如何选择学习率需要具体问题具体分析。
2 随机梯度下降法
随机梯度下降法主要是为了解决第一个问题:梯度计算。
由于随机梯度下降法的引入,我们通常将梯度下降法分文三种类型:
(1)批梯度下降法(batch-GD)
原始的梯度下降法
(2)随机梯度下降法(SGD)
每次梯度计算只使用一个样本
- 避免在类似样本上计算梯度造成的冗余计算
- 增加了跳出当前的局部最小值的潜力
- 在逐渐缩小学习率的情况下,有与批梯度下降法类似的收敛速度
(3)小批量随机梯度下降法(mini-batch GD)
每次梯度计算使用一个小批量样本
- 梯度计算比单样本更稳定
- 可以很好地利用现成高度优化的矩阵运算工具
注意:神经网络训练的文献中经常把 mini-batch GD称为SGD。
随机梯度下降法的主要困难在于前述的第二个问题:学习率的选取。
(1)局部梯度的反方向不一定是函数整体下降的方向
- 对图像比较崎岖的函数,尤其是隧道型曲面,梯度下降表现不佳
(2)预定学习率衰减的问题
- 学习率衰减很难根据当前数据进行自适应
(3)对不同参数采取不同的学习率的问题
- 在数据有一定稀疏性时,希望对不同特征采取不同的学习率
(4)神经网络训练中梯度下降法容易被困在鞍点附近的问题
- 比起局部最小值,鞍点更加可怕
注:为什么不用牛顿法?
- 牛顿法要求计算目标函数的二阶导数(Hessian matrix),在高维特征情形下这个矩阵非常巨大,计算和存储都成问题
- 在使用小批量情形下,牛顿法对于二介导数的估计噪声太大
- 在目标函数非凸时,牛顿法更容易受到鞍点甚至是最大值点的吸引
3 动量法(Momentum)(适用于隧道型曲面)
梯度下降法在狭长的隧道型函数上表现不佳,如下图所示:
- 函数主体缓缓向右方下降
- 在主体方向两侧各有一面高墙,导致垂直于主体方向有更大的梯度
- 梯度下降法会在隧道两侧频繁震荡
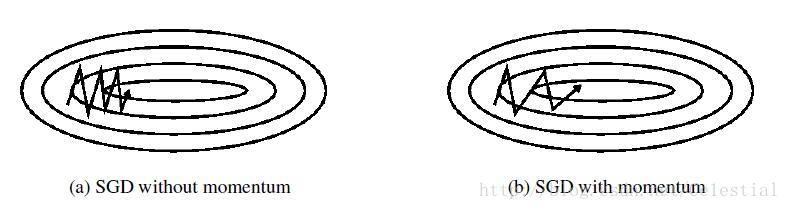
动量法每次更新都吸收一部分上次更新的余势:
这样主体方向的更新就得到了更大的保留,从而效果被不断放大。
物理上这就像是推一个很重的铁球下山,因为铁球保持了下山主体方向的动量,所以在隧道上延两侧震荡次数就会越来越少。
4 Nesterov accelerated gradient (动量法的改进算法)
动量法的一个问题在于:从山顶推下的铁球会越滚越快,以至于到了山底下停不下来。我们希望算法更加聪明一些,可以到达底部之前就自己刹车。
利用主体下降方向提供的先见之明,预判自己下一步的位置,并到预判位置计算梯度。

5 Adagrad (自动调整学习率,适用于稀疏数据)
梯度下降法在每一步对每一个参数使用相同的学习率,这种一刀切的做法不能有效地利用每一个数据自身的特点。
Adagrad是一种自动调整学习率的方法:
- 随着模型的训练,学习率自动衰减
- 对于更新频繁的参数,采用较小的学习率
- 对于更新不频繁的参数,采用较大的学习率
为了实现对于更新频繁的参数使用较小的学习率,Adagrad对每一个参数历史上的每次更新进行叠加,并以此来做下一次更新的惩罚系数。
梯度:
gt,i=∇θJ(θi)
梯度历史矩阵:
Gt对角矩阵,其中Gt,ii=∑kg2k,i
参数更新:
6 Adadelta (Adagrad的改进算法)
Adagrad的一个问题在于随着训练的进行,学习率快速单调衰减。
Adadelta则使用梯度平方的移动平均来取代全部历史平方和。
定义移动平均:
E[g2]t=γE[g2t−1]+(1−γ)g2t
于是就得到参数更新法则:
Adadelta以及一般的梯度下降法的另一个问题在于,梯度与参数的单位不匹配。
Adadelta使用参数更新的移动平均来取代学习率
η
。于是参数更新法则变为:
注意: Adadelta的第一个版本也叫做RMSprop,是Geoff Hinton独立于Adadelta提出来的。
7 Adam (结合了动量法和Adadelta算法)
如果把Adadelta里面梯度的平方和看成是梯度的二阶矩,那么梯度自身的求和就是一阶矩。Adam算法在Adadelta的二阶矩基础上又引入了一阶矩。
而一阶矩,其实就类似于动量法里面的动量。
于是,更新法则为:
注意: 实际操作中 mt 和 vt 采用了更好的无偏估计,来避免前几次更新时候数据不足的问题。
e.g.
8 如何选择算法?
- 动量法与Nesterov的改进方法着重解决目标函数图像崎岖的问题
- Adagrad与Adadelta主要结局学习率更新的问题
- Adam集中了上述两种做法的主要优点
目前为止,Adam可能是几种算法中综合表现最好的。














 887
887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









