







来源:AI科技评论
概要:这里,我们为大家奉上机器学习学者 Alex Honcha 所展望的 2018 年最可能产生突破的 AI 领域。
2017年马上就要过去了,而 AI 也在2017年中得到了快速发展。研究人员们提出了很多有趣而又富有开创性的工作。而作为 AI 从业人员的我们,也不禁会对明年 AI 的发展有了更多的憧憬。以下是机器学习学者 Alex Honcha 所展望的 2018 年最可能产生突破的 AI 领域。
在这篇文章中的预测,是基于 2012 年以来学术界和科技巨头实验室的研究思路的演变。我选择了一些处于初步发展阶段的领域,但是它们已经准备充分,可以进行深入研究并可能在 2018 年取得突破性进展,并最终在 2019-2020 年真正地被应用到现实中去。
开源的科研
来自其他科研领域对的人士经常会有一个问题:那些AI的家伙研究的怎么这么快?
首先,大多数机器学习领域的文章并不会在期刊上发表,而是发表在会议上,同时还有即时的 arXiv 预印本,所以研究者可以随时看到最新的研究成果,而不是等到发出文章之后的好几个月。
其次,我们不发布「顺势」的文章:为了使得文章能够发表,我们必须提出最高水平的或者能够与目前最高水平方法相近的新方法。另外,新方法需要在不同的指标下接受检验:速度,准确度,并行执行,数学证明,处理不同大小的数据集等。这使得方法的泛化能力大大提升。
最后,所有的主要文章都开源了算法的实现,所以结果可以被其他人运行,进行多重检验,甚至可以进一步改进。
无需平行语料库的语言模型
我们考虑这样一个简单的问题:
取 50 本阿拉伯语书,16 本德语书,以及 7 本乌克兰语书,要求你学会将阿拉伯语翻译到到乌克兰语,以及将乌克兰语翻译到德语。
你能够做到吗?我打赌不能。但是机器已经做到了这点!在 2017 年,两个突破性的文章被发表:「Unsupervised Machine Translation Using Monolingual Corpora Only」(https://arxiv.org/abs/1711.00043),「Unsupervised Neural Machine Translation」(https://arxiv.org/abs/1710.11041)。机器翻译基本的想法是将意思相似的句子放在一起,训练一些通用人类语言表达空间。这种想法并不新鲜,但是目前最新的方法已经不需要明确的成对的德语-阿拉伯语句子了。
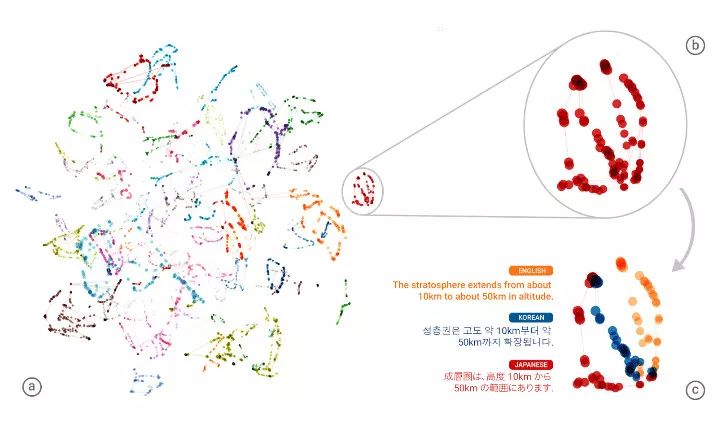
一种多语言表示空间的示例
这几篇文章的作者声称,只要很少的监督,模型翻译的质量就可以急速上升。我预计这项研究会在2018年夏天至年底完成。这种监督,而又不是真正监督学习的思想,将会而且一定会拓展到其他领域。
是时候更好地理解视频了
我们已经创造出了能够超越人类的计算机视觉系统,这多亏了各种更深,更宽,以及更密集连接的网络。
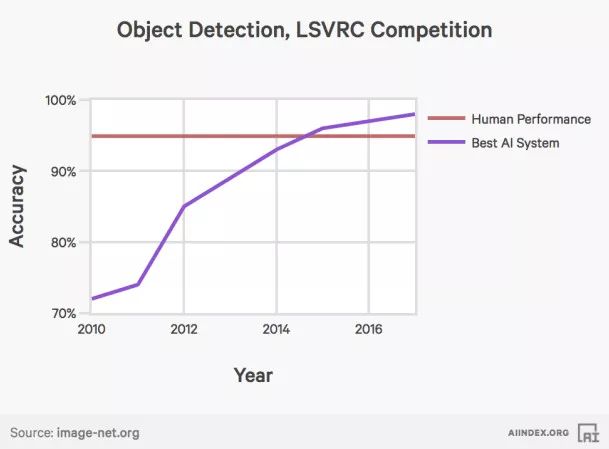
物体检测准确度变化(来自http://aiindex.org/2017-report.pdf)
但是目前的成果仅限于静态图像,然而现实中人类更习惯于用眼睛观察图像序列、视频或者就是真实的世界,所以我们需要将计算机视觉方法应用到视频中,并使得它们能够像处理静态图像那样快。
多模态/多任务学习
在我们观察周围的世界的时候,我们不仅仅看到了移动的图像:还听到了声音,感受到外面的温度,还能感受到一些情绪。这意味着我们从不同的来源「看到」了我们周围的世界,我们称这种源为模态。而且,即使只“看到”一种模态,比如听到了一段人说话的声音,我们不仅仅是把它像语音识别系统一样翻译成文字,我们也能懂得说话人的性别和年龄,以及交谈的人的情绪。我们能够同时理解不同的事物。我们希望机器也能具有这样的能力。
人类能够处理超过十个模态,为什么机器不能?
在我决定将多模态学习加入到这篇文章之前,本来想写人工智能在金融方面的应用,但是当我看到下面这个数据集发布之后,我就知道金融交易就再也没有机会加入到这篇文章中了。这个 HoME 数据集包含了很令人震惊的环境, 它包含了视觉,语音,语义,物理,以及与其他物体交互等多种数据。你可以教机器人在一个几乎真实的房间中去看,去感觉,去听每一个东西!
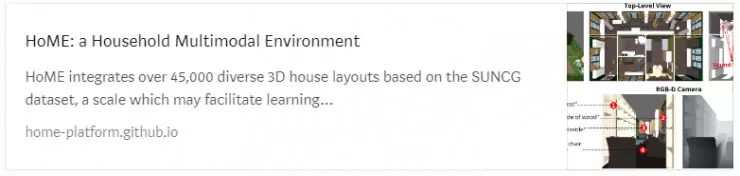
https://home-platform.github.io/
强化学习:游戏不止
强化学习对我来说是最激动人心和最令人怀疑的领域之一:它可以在没有任何监督的情况下,通过自我博弈取得象棋,围棋和扑克这样复杂游戏的胜利,但是与此同时,强化学习几乎没有任何在真实世界中的应用,比如能够在人工环境中攀爬的3D玩具人物,或者可以移动的机械臂。这也是为什么我认为关于强化学习的研究在明年仍需要继续。我认为会发生两个主要的突破:OpenAI的 Dota 2(已经 1v 1打败过职业选手),以及 DeepMind 的星际争霸2。
我非常确定 DotA 和星际争霸的冠军未来会被 OpenAI 以及 DeepMind 的机器人击败。现在你已经可以使用 OpenAI 的实验环境(https://github.com/alibaba/gym-starcraft)玩星际争霸2了。
对于那些不喜欢玩游戏的研究者,OpenAI 也有一些有趣的结果:竞争性自我博弈(http://t.cn/RWta4ie),从其他模型中学习(https://blog.openai.com/learning-to-model-other-minds/),学习交流与合作,当然,还有 Facebook 的学习谈判。我希望能够在未来的一到两年中在聊天机器人中看到这些结果,但是目前为止,还有很多研究要做。
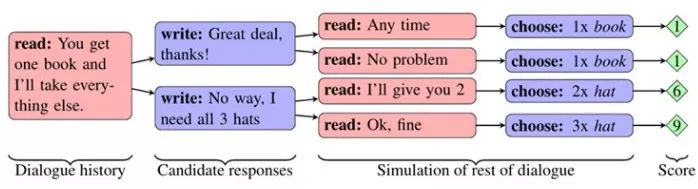
Facebook 谈判机器人
AI 需要自我解释
使用神经网络很酷,你可以使用不同层数的神经网络,不同密度的连接在 ImageNet 上得到 0.05 的提升,甚至可以应用在医疗放射图像的分析上,但是如果它们甚至不能自我解释,我们真的可以依靠它们吗?
我想知道,为什么这个网络认为这个图像是狗,为什么认为这个人在微笑,或者为什么说我有一些疾病。
然而,即使神经网络能够给出非常准确的结果,但是它并不能给出上面问题的答案:

AI的解释问题仍然被考虑为一个开放问题,尽管我们已经有了一些成功的应用,例如:从深度神经网络提取基于树的规则(extraction of tree-based rules from deep networks ,http://t.cn/RH6wi1M),卷积层的可视化,以及更复杂的概念,例如隐含概念(latent conception ,http://t.cn/RH6wT1q),与或图训练(http://t.cn/RH6wemy),或者生成视觉解释(https://arxiv.org/pdf/1603.08507.pdf):

图片来自 https://arxiv.org/pdf/1603.08507.pdf
以及目前最好的模型:InterpretNet
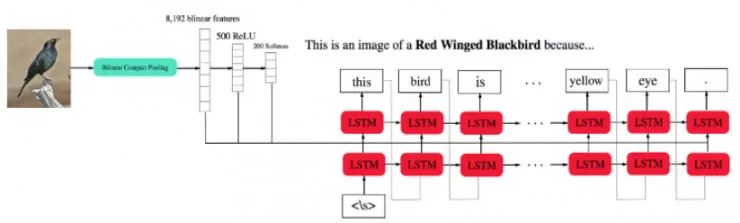
图片来自 https://arxiv.org/pdf/1710.09511.pdf
我们也应该更多考虑贝叶斯方法,它能够跟踪预测的确定性。这一定是明年机器学习的一个热门话题。
AI 安全性:不再是一个小问题
在 AI 解释性之后,要解决的第二个重要任务就是现代机器学习算法的脆弱性,它很容易被对抗性样本攻击。
http://t.cn/Rce5gfy
https://blog.openai.com/adversarial-example-research/
对于这些问题,Ian Goodfellow做出了名为 CleverHans 的原创性工作。以及数据的隐私和基于加密数据进行训练的问题,可以查看来自牛津博士的精彩文章(http://t.cn/R6PpKUp),它展示了一个简单的同态加密神经网络的例子。
我们需要保护 AI 的输入(隐私数据),内部结构(以防被攻击),以及它所学到的东西(确保它的行动的安全性)
然而这些并不是今天人工智能的所有问题,从数学角度来看(特别是在强化学习中),算法仍然不能安全的探索环境,这意味着如果我们现在让物理机器人自由地探索世界,它们在训练过程无法完全避免错误或者做出不安全的行为;同时我们仍然不能完全使我们的模型适应新的分布,模型的泛化能力是一个重要问题,比如基于真实世界数据集训练的网络很难识别手绘的物体。
3D和图形的几何深度学习(Geometrical Deep Learning)
在 NIPS 上出现这篇演讲(https://www.youtube.com/watch?v=LvmjbXZyoP0)之前,我并没有真正意识到这个课题。当然,我知道现实世界的数据通常位于更高维度的空间,并且数据和信息本身拥有自己的几何和拓扑结构。三维物体可以被认为是点云,但实际上他是一个表面(流形manifold),一个具有自己的局部和全局数学(微分几何)的形状。或者考虑图(graph),你可以用一些邻接矩阵的形式来描述它们,但是你会丢掉一些局部结构或者一些图形。其他的多为对象,例如图像,声音,文本也可以从几何角度考虑。我相信我们会从这个领域中的研究得到许多有趣的见解。
所有数据都具有我们无法避免的局部和全局几何信息
可以在这个链接中找到更多的信息:
http://geometricdeeplearning.com/
结论
除了以上讨论的内容,我们还可以谈论知识表示、迁移学习、单次学习、贝叶斯学习、可微计算等等方面,但是实际上,这些领域还没有做好充分的准备,并不能在 2018 年发展到一个全新的阶段。在贝叶斯学习中,我们陷入了数学抽样中;微分计算很酷,但是神经图灵机、DeepMind 的微分神经计算机仍然遥遥无期;表征学习已经是深度学习算法的核心,所以并不值得去写;单次(one-shot)和少次(few-shot)学习同样还没有发展起来,也没有很好定义的评价标准以及数据集。我希望本文中提到的各个主题能够在逐步成熟,并在2019-2020年更多的应用到实际世界中。
除此之外,下面是一些希望大家能够关注的网站,它们能够提供很多最新的研究进展:
OpenAI:http://openai.com/
DeepMind:https://deepmind.com/
IBM AI Research:http://www.research.ibm.com/ai/
Berkley AI:http://bair.berkeley.edu/
Stanford ML Group:https://stanfordmlgroup.github.io/
Facebook Research:https://research.fb.com/
Google Research:https://research.googleblog.com/
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。由互联网进化论作者,计算机博士刘锋与中国科学院虚拟经济与数据科学研究中心石勇、刘颖教授创建。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”















 4362
4362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









