








注:本文章是作者CC对Jake Bouvrie论文《Notes on Convolutional Neural Networks》的翻译。鉴于作者水平有限,错误难免,仅作读者参考,也作为自己科研道路的一个微不足道的脚印。
《卷积神经网络笔记》——Jake Bouvrie 2006年11月22日
1.介绍
这篇文档讨论了卷积神经网络(CNNS)的推导与实现[3,4],其次是一些简单的扩展(extension)。卷积神经网络比起权重包含更多的连接;其结构本身实现了一种规则的形式。此外,一个卷积网络自动提供一些不变量。这个特殊种类的神经网络认为我们希望学习一种滤波器,用数据驱动的方式,作为一种方式去提取特征描述输入。推导过程我们提供了详细的二维数据和卷积,但是能够被扩展任意维度而不需要太多额外的努力。
我们开篇描述经典(classical)全连接反向传播,然后推导出滤波和子采样层在二维卷积神经网络通过反向传播更新。通过讨论,我们强调实现的效率,并给出Matlab代码小片段(snippets)来伴随方程。写有效的代码重要性当谈到CNNs不能够被夸大。我们将话题转为如何通过前面层自动联合特征匹配,特别考虑,学习特征匹配的稀疏联合。
免责声明(Disclaimer):这个粗糙的笔记可以包含错误,夸大(exaggerations)和错误的声明。
2.Vanilla 反向传播通过全连接网络
在典型的卷积神经网络你也许在文献中可以发现,早期的分析可选择神经和自采样操作的组成,同时最后一步的结构组成通用的(generic)多层网络:最后几层(最靠近输出)将会被全局连接1维层。当你准备通过最后2D特征匹配作为输入到全局连接1D网络,这经常非常方便仅仅连接所有的特征表现在所有的输出匹配在一个长的输入向量,我们返回vanilla反向传播。标准的反向传播算法将被描述,然后再详细到卷积网络下(看e.g.[1]获取更多的详细信息)。
2.1前馈传播
在下面的推导过程中,我们将考虑二次误差损失方程。对于一个多分类问题,有c类和N个训练样本,这个误差为:

这里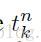
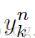
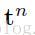
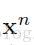
因为误差在全部数据集上仅仅是各个模式上个体误差的和,我们将考虑反向传播对单一模式,设第n个为:
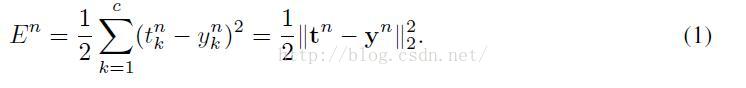
传统的全局连接层,我们能够计算导出E遵从下面的反向传播规则形式计算网络权重。令l表示当前层,输出层设计设计为L层,输入层设计为l层。定义输出层为
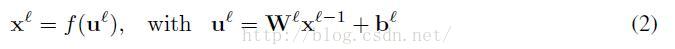
这里,输出激活函数f(·)通常选择为logistic(sigmoid)函数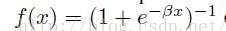
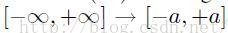

2.2 反向传播
反向传播的错误率通过网络能够被认为灵敏的在各个单元遵从偏导数。这就是说,

因为在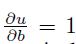

这里“o”表示单元数组元素相乘(element-wise multiplication)。对于误差方程(1),对输出层神经元的灵敏度将采用一个细微的不同形式:
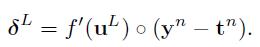
最后,delta法则来更新权重分配去给一个神经元仅仅是个输入神经元的拷贝,通过神经元delta的缩放。用向量形式,这个计算作为外积计算(outer product)在输入向量(这个是从前层获得的输出)和灵敏度 向量:

类似表达形式为了(3)给出的偏移更新。特别的有一个学习率参数
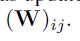
3. 卷积神经网络(CNN)
典型的卷积层由子采样层来减少计算时间和渐渐建立深度空间和构型不变量。然而一个小的子采样被期望为了保持细化在同一时间。当然,这个主意现在并不新,然而,概念是简单有效的。哺乳动物的视觉皮层(mammalian visual cortex)和其模型[12,8,7]很大程度上吸引了这个主题(draw heavily on these themes),听觉神经系统(auditory neureoscience)在过去的十年显示(revealed),因此这些相同的设计参数能够被发现在最初的和belt听觉领域在许多不同的动物皮层(cortex[6,11,9])。层次分析(Hierarchical)和学习结构可能主要的成功在听觉领域。
3.1 卷积层(Convolution Layers)
对于卷积层在网络中,让我们移除前向来获取反向传播更新。在卷积层,前面的层的特征匹配被可学习的核来卷积。使激活函数来规范化输出特征匹配。每一个输出匹配可能联合卷积通过多重输入匹配。通常,我们有:
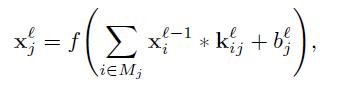
Mj表示输入匹配选择,卷积有效的边界操作类型当在MATLAB中实现。一些输入匹配通用的选择包括全对偶或者所有
三联体(all-triplets),但是我们将讨论如何一个能够学习联合在下面。每一个输出匹配给一个另外的偏数b,然而对于一个特别的输出匹配,这个输入匹配将被卷积用一个明显的卷积核。这就是说,假如输出匹配j和k两者和超过输入匹配i,那么这个核应用去匹配i是不同的对于输出匹配j和k。
3.1.1 计算梯度(Computing the Gradients)
我们假设每一个卷积层l被跟踪通过一个降采样层l+1.这个反向传播算法认为为了计算每个单元层l的灵敏度,我们应该首先计算相应的下一个层灵敏度的总和。相应的感兴趣节点在最近层l,乘以这些连接的每一个通过联系权重定义在层l+1。然后我们乘以这个数量通过评估当前层前一个激活函数的输出而得到的激活函数,u。在降采样层之后的卷积层场合下,一个像素在另一个层连接灵敏度匹配
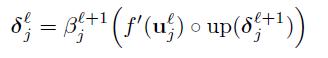
这里(·)表示一个上采样操作,简单的拼贴每一个像素在输入 水平和垂直n次在输出,假如子采样层通过子采样通过n因素。因为我们将在下面讨论,一个可能的方式有效的实现这个方程就是用Kronecker点乘:
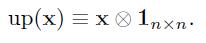
现在我们有给出匹配的灵敏度,我们实现计算偏梯度通过简单所有记录的综合在
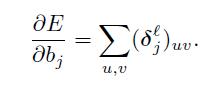
最后,这个和权重的梯度用反向传播计算,除了在这个场合相同的权重被分享通过许多连接。我们因此求和梯度根据一个给定的权重在所有的连接提到权重,正如我们偏转项的操作:

这里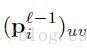
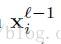
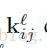


这里我们旋转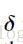
3.2 子采样层
一个子采样层产生输出匹配的降采样版本。假如有N个输入匹配,那么将准确的有N个输出匹配,尽管输出匹配将会是更小。更通常的:
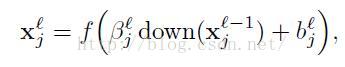
这里下降(·)表达一个子采样方程。典型的这个方程将每一个有区别的n*n快求和在输入图像,因此输出图像将会是n倍小在这二维空间。每一个输出匹配给出了他的自己倍数偏量
3.2.1 计算梯度
这里的困难是计算匹配灵敏度。一旦我们获取他们,仅仅只有一个需要学习的参数来更新是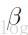
当我们尝试着计算3.1.1部分的核梯度的时候,我们需要理解哪一个补丁在最近曾灵敏度匹配相应的一个给定的像素在另一个层灵敏度匹配为了应用delta递归(recursion)看起来像等式(4)。当然,权重多重连接在输入补丁和输出像素将会被精确的卷积核权重。这进一步有效的实现 用卷积:
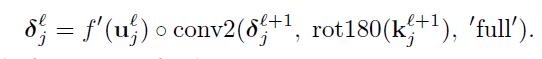
正如前面的,我们旋转核使得卷积方程表现出互关联(cross-correlation)。主义在这场合下,然而,我们要求全卷积边界处理,来进一步借助MATLAB的命名法。这个小的不同让我们处理边界情况更加简单和有效,这里输入的数量在l+1层的一个单元不是n*n卷积核全尺寸。在这些场合下,全卷机将会自动填补(pad)缺失的输入用0.
在这一点上我们准备好了去计算b和
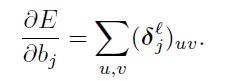
倍数偏数
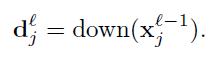
那么

3.3 学习结合特征匹配
很多时候,这是有优点的去提供一个输出匹配包含一个和在不同输入匹配的几个卷积。在文章中,联合形成一个给定输出匹配的输入匹配经常首选。然而,我们能够尝试着去学习这个联合在训练期间。令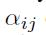
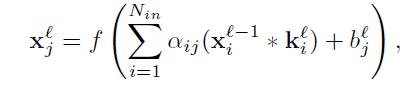
服从(subject to)下面的约束(constrains):
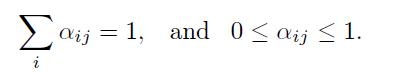
约束能够强化通过设定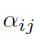
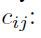
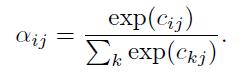
因为每一个权重
获得softmax方程给定如下:

这里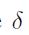
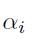
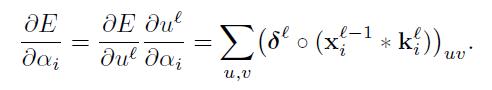
这里,
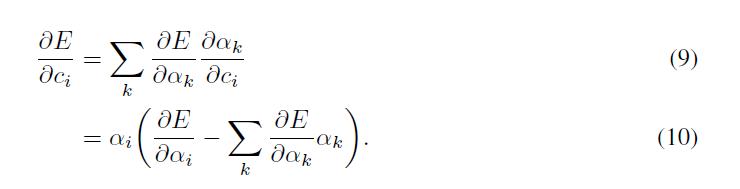
3.3.1 执行稀疏结合
我们能够尝试着利用(impose)稀疏约束在权重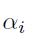


发现规则化的贡献对于梯度的权重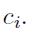
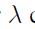
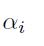

每一个地方出了在原点。结合(8)的结点将允许我们获得贡献:
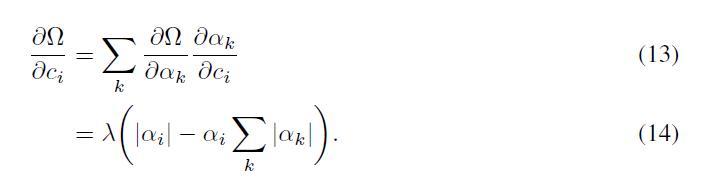
最后的梯度对于权重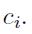
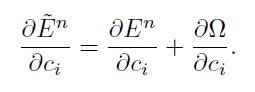
3.4 用它更快用MATLAB
在网络用可选择的子采样和卷积层,主要的计算瓶颈是(bottle-neck)是:
1.在前馈传递中:降采样卷积层输出匹配
2.在反向传递过程中:更高的子采样层的delta的上采样去匹配更低卷积层的输出匹配尺寸。
3.应用sigmoid和他的派生(derivatice)。
表现卷积在反馈和反向传播阶段当然也是瓶颈,但是假设2D卷积路线是有效的实现,没有更多我们能够做关于它。
一个尝试可能用MATLAB的建立图像处理路线来处理上下采样操作。对于上采样,imresize将会做这个工作,但是伴随着重大的开销(significant overhead)。一个更快的选择是用Kronecker点积方程kron,用矩阵成为上采样,一个矩阵。这个可能成为快速放大的顺序。当他来与下采样阶段在反馈过程中,imresize不能提供选项去下采样通过求和独一无二的n*n块。最近邻方法将会替代一个像素快通过块中的原始像素。一个可选择去应用blkproc对于每一个独一无二的块,或者一些联合im2col和colfilt。当这些选项的两者仅仅计算这些必要的。重复调用用户定义的快处理方程暴露重大的消耗。一个更快可循则在这个场合下就是去卷积图像用一个矩阵,然后简单的带走每一个序列用标准指标(如,y=x(1:2:end,1:2:end)。尽管卷积在这个场合下准确的计算4倍或者更多的输出(假设2x降采样)正如我们真正需要,这个方法仍然一个数量级顺序或者更快比起前面提到的方法。
许多作者,看起来,实现sigmoid激活方程和获得用inline方程定义。在这个写的时候,“inline”MATLAB方程定义不是想C宏指令(macros),采用一个巨大的时间数量来评估。因此,经常值得去简单的代替所有的参考对于f和f‘用准确的代码。有权衡在优化你的代码和保持可读性。
4. 训练时事件(不完整)
4.1 Batch cs.在线更新
Stochastic 下降vs.batch 学习
4.2 学习率
LeCun’s的stochastic在线方法(hessian对角线)。这个值得?VIrene’s的观点:至少有一个不同的率对于每一层,因为梯度在低层更小和更低的考烤箱。LeCun做了相似的称述在[5].
4.3 误差方程的选择
二次误差(MLE),vs.点乘序列。最近的能够更加有效对于一些分类任务[2].
4.4 检查Your工作用有限微分
有限微分能够一个不可缺少的(indispensable)工具当他来时间去证实你能够获得你的反向传递正确的实现。他是显著地简单去做许多错误和仍然有一个网络,发现学习东西。检车梯度你的代码反对有限的不同去估计一种方式去确保你不能够有任何错误:对于一个简单的输入模式,估计梯度用二次有限微分:
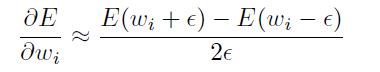
检查反对梯度你的反向传播代码返回。Epsilon应该是小的,但是不能太小而导致数据精度问题。一些事情比如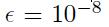

















 3815
3815











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









