






原文链接:Hinge loss
Hinge loss
在机器学习中,hinge loss常作为分类器训练时的损失函数。hinge loss用于“最大间隔”分类,特别是针对于支持向量机(SVM)。对于一个期望输出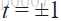
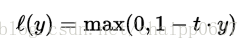
注意:这里的y分类器决策函数的“原始”输出,而不是预测的类别标签。例如,在线性SVM中,y=wx+b,(w,b)是分类超平面的参数,x是要分类的点。
可以看到,当t和y有相同的符号的时候(这意味着y的预测是正确的)并且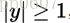
扩展
当然有时二分类的SVM通常会以一对一或者一对多的形式扩展到多分类的任务,为了实现这个目的,也可以扩展hinge loss函数。现在已经有多种hinge loss的不同的变化形式。比如,Crammer and Singer提出的一种针对线性分类器的损失函数:
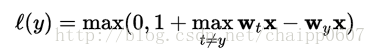
Weston and Watkins提出了一种相似定义,但是用相加取代了求最大值:
在结构化预测中,hinge loss可以进一步扩展到结构化输出空间。具有边缘重新缩放的结构化SVM使用以下变量,其中w表示SVM参数,y表示SVM的预测结果,φ是联合特征函数,Δ表示Hamming loss:
优化
hinge loss是一个凸函数,所以,很多在机器学习中涉及到的凸优化方法同样适用于hinge loss。它是不可微的(不连续啊),但是对于线性SVM(
然而,因为hinge loss在t*y=1的时候导数是不确定的,所以一个平滑版的hinge loss函数可能更加适用于优化,它由Rennie and Srebro提出:
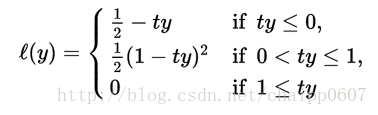
除此之外,还有二次方(平方)平滑:
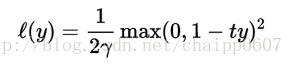
modified Huber loss是在
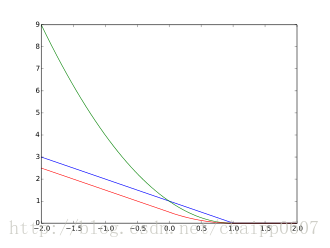
上图为hinge loss函数关于z=ty的三种版本,蓝色的线是原始版,绿色线为二次方平滑,红色的线为分段平滑,也就是被Rennie and Srebro 提出的那一版。
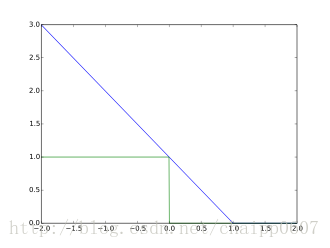
上图中为hinge loss(蓝)和0/1损失(绿)。注意,hinge loss函数惩罚了ty<1(也就是说在ty<1的时候有loss不为0),这个特点和SVM中的分类间隔的概念是相对应的。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









