







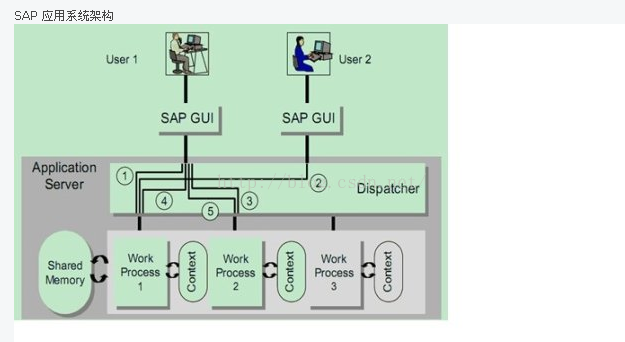
应用层运行着DIALOG进程,每个DIALOG进程绑定一个数据库进程,DIALOG进程与GUI进行通信,每次GUI向应用服务器发送请求时都会通过dispatcher服务为每个GUI的请求分配一个Dialog进程.一个程序运行时,GUI与Dialog进行需要多次通信,每次通信使用的Dialog进程不一定相同,在Dialog进程将控制权转给前台的GUI时,由于Dialog进程同数据库进程绑定,会触发一个隐式数据库提交(COMMIT WORK),如果在Dialog进程发生A类型错误,则触发隐式的数据库回滚(Rollback)
SAP LUW
SAP LUW是DB LUW的一个增强,受体系结构限制,SAP程序每次屏幕切换时(控制权从后台DIALOG进程转移到前台GUI的Session),都会触发一个隐式的数据库提交,一个程序在运行是会产生多个DB 的LUW,这样无法做到全部提交或全部回滚,在某些业务场景下,这种事务的提交机制不足以保证数据的一致性,为此有有了SAP LUW机制.SAP LUW是一种延迟执行的技术,它将本来需要执行的程序块,记录下来.记录的位置在内存或DB Table中,如perform on commit 会记录到内存中,update Funciton module即可以记录到内存也可以记录到VBMOD 和VBMOD表中.系统在执行COMMIT WORK的时候会查询记录,真正执行需要运行的代码,COMMIT WORK一般在最后一个屏幕执行,这样就实现了将跨屏幕的数据更新逻辑绑定到一个DB LUW中,实现复杂情况数据更新的一致性
SAP LUW的绑定方式
CALL FUNCTION...IN UPDATE TASK,
该种方式需要Funciton类型为Update Module类型,同时在调用时使用IN UPDATE TASK参数.
在程序调用 Update Module进行更新时分为本地和非本地
非本地方式:
注册的更新函数记录在VBMOD 和VBMOD表中,COMMIT WORK 时更新操作在UPDATE进程中执行,此时调用程序不等待被调用函数的返回,使用的为异步方式.如果使用COMMIT WORK AND WAIT,此时调用程序等待被调用函数的返回,使用的为同步方式.
本地方式
在调用函数前需要执行 SET UPDATE TASK LOCAL. 这样所有在该语句后使用CALL FUNCTION...IN UPDATE TASK注册的更新函数不会记录到数据库中,而是记录在内存中,在Commit work之后,会从内存取得待执行的函数,在同一个Dialog进程中执行数据的更新,本地方式更新采用的是同步方式,即使在Commit work后指定了and wait参数,仍然是同步执行.
在使用COMMIT WORK之后 SET UPDATE TASK LOCAL的效果会被清除掉,如果COMMIT WORK后注册的更新函数仍然需要采用本地方式,需要再执行一次 SET UPDATE TASK LOCAL语句.
优缺点对比
本地方式不将待执行的更新函数写到数据表中,减少了I/O操作,效率上较高,但由于采用的是同步方式,程序需等待更新结果,用户交互时的会感觉程序运行较慢
非本地方式会将更新结果记录到数据表中,可以通过SM13查看更新情况,同时由于可以进行异步更新,用户交互时感觉会比较快
CALL FUNCTION... IN BACKGROUND TASK DESTINATION,
是一种对RFC函数进行事务绑定的方式
PERFORM ... ON COMMIT
将待执行的程序块注册到内存中,可以使用LEVEL参数指定优先级,优先级按升序进行排列,较小的会优先执行.
使用ON COMMIT参数注册的subroutine,如果同样名字的subroutine被注册了多次,在COMMIT WORK时只执行一次,IN UPDATE TASK方式执行的Funciton没有这个限制
绑定方式的执行顺序
PERFORM ON COMMIT 会优先执行,如果中断,CALL FUNCTION... IN BACKGROUND TASK和CALL FUNCTION...IN UPDATE TASK, DESTINATION 将不会执行,可以保证数据的全部提交和全部回滚
建议不要混合使用CALL FUNCTION... IN BACKGROUND TASK和CALL FUNCTION...IN UPDATE TASK,因为一个是针对本地数据进行的更新,一个是远程数据,从技术上猜测,跨数据库的提交与回滚很难实现,故同时使用这两种方式可能会带来数据不一致的问题,除非本地和远程数据不需要保持数据的一致
V1 & V2 Update

图例说明
Immediate start 表示V1方式,更新出错后,可以在SM13里重新执行
Immediate start -no restrat possible V1方式,出错后不可以在SM13里重新执行,有些更新脱离具体程序后再执行可能会带来数据的不一致,可以考虑使用这种方式
Start delayed V2方式 V1方式更新完成后触发,
Collective run V2方式 需使用Collective(RSM13005)程序手动或JOB方式执行,
更新函数分为V1和V2
V1优先级高于V2,V2被设计为依赖于V1,适合执行需要在V1完成后进行的操作,
V1更新使用V1进程处理,V1进程名字一般为UPD,V1进程绑定独立的数据库进程.在V1进程中调度的更新函数如果更新失败,回滚,不进行V2操作.成功则提交更改到数据库,同时删除所有的SAP锁
V2更新使用V2进程处理,如果没有配置V2进程则共用V1进程,V2进程名字为UP2,V2更新在独立DB LUW中,V2更新回滚后不会影响到V1更新提交的数据,由于V1更新结束后会删除SAP的锁,所以V2更新是在没有逻辑锁的情况下进行的,V2更新出错后可以在SM13中重新执行
SAP Locks
SAP 的锁是一种逻辑锁,通过加锁函数和解锁函数进行处理
锁类型
S 共享锁 读锁,可以累加
E 独占锁 写锁 进程内可以累加
X 排他锁 写锁 不可以累加
慎用S锁,S锁的累加特性会造成锁无法彻底释放,造成其他程序无法写入,E锁可以保证只加一次锁
锁对象
通过锁对象可以生成加锁和解锁函数
其中scope 参数 1 表示程序内,有效 2 表示 update module 内有效 3 全部
_wait 表示如果对象已经被锁定,是否等待后再尝试加锁,最大的等待时间 有系统参数 ENQUE/DELAY_MAX控制
_COLLECT 参数表示是否收集后进行统一提交,COLLECT 是一种缓存与批处理方法,即如果指定了Collect,加锁信息会放到Lock Container 中,Lock Container实际上是一个funciton Group控制的内存区域,如果程序中加了很多锁,锁信息会先放到内存中,这样可以减少对SAP锁管理系统访问,若使Lock Container中的锁生效,需执行FLUSH_ENQUEUE 这个Funciton,将锁信息更新到锁管理系统中,此时加锁操作生效,使用函数 RESET_ENQUEUE可以清除Lock Container中的锁信息
释放锁
调用DEQUEUE函数
如果程序更新用到到V1 Update时,在commit work是会删除所有的锁
程序中止
rollback
为什么需要使用SAP Lock
SAP Lock是一种逻辑锁,相对于DB Lock,是一种轻量级的锁,DB Lock一旦发现不能加锁会进行延迟等待,使用SAP Lock 一定程度上可以减少对DB Lock的占用,避免死锁,同时合理使用SAP Lock可以保证数据的一致性
其他
select for update 是在DB层次上加的锁
参考
SM66查看活动进程,如果有V1和V2更新,可以看到UPD和UP2进程
SM13查看出错或未执行完的V1和V2更新














 2454
2454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









