






在进行深度学习的过程中,我们经常会遇到一些自己不懂的概念和术语,比如,softmax, batch,min-batch,iterations,epoch,那么如何快速和容易的理解这些术语呢? 因为笔者也是深度学习的初学者,所以笔者在学习和浏览文章的过程中,把一些自己不太容易和理解的一些概率记录了下来。希望对其他初学者也有所帮助。
@softmax 函数
softmax是一个函数,其主要用于输出节点的分类,它有一个特点,所以的值相加会等于1. 从李宏毅老师的PPT里面找到了一张图,感觉解释的非常形象。先借花献福分享给大家。
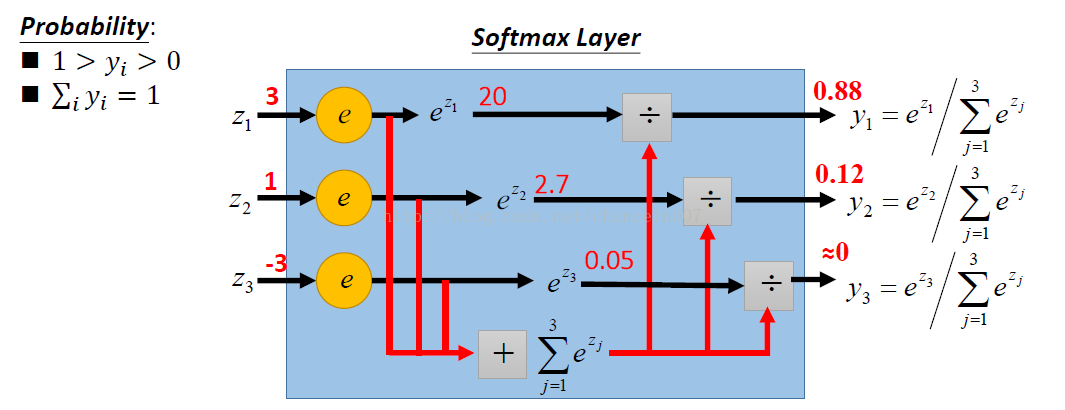
具体例子,可以举图像识别,比如图像识别数字,0~9, 线设置图像识别的输出数字为10个输出节点,然后通过softmax算法,算出对于一张图像的输入,其经过神经网络的计算,会输出10个值,那当前输出的值就是0~9的可能性,但是总和是1.那个数字的输出的概率最大,则这次手写数字的识别结果就是那个数字。
@ batch VS min_batch VS Iteration
在学习深度学习或者使用Keras框架的时候,我们经常会遇到比如,设置batch和min-batch的值,让其来训练输入样本。 为了更好的理解这个概念,我们可以举一个例子,
比如,我们有1050个样本,如果我们设置 batch_size等于100(这个时候100就是min_batch),算法则会首先从训练集取前100(1~100)个输入数据去训练网络;下一次取(101~200),我们一直这样循环,
知道我们把所有的训练样本都取到了。但是问题经常会发生在最后一个训练样本。比如1050不能被100整除,这个时候,我们对于后面的50个样本可以单独拿出来训练;所以总共是11次训练其网络参数的Iteration(迭代)。如果设置我们设置了batch等于1050,也就是全集(这个时候1050就是全集),同时也训练11次(Iteration)。
- min_batch的优点:
只需要更少的内存
训练速度快
- min_batch的缺点:
精度低
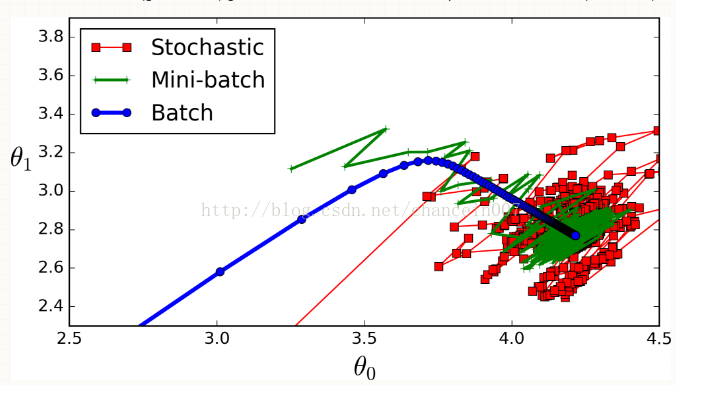
具体请见下面一张图。
@ Epoch
Epoch就是把训练数组全部训练完成的一个正向和反向计算的过程。比如,我们有1000个样本,batch size是500,其将会有2个Iterations。这两个Iteration完成一个
Epoch。太拗口了。。。。。。。。。。
后面遇到,将会继续待续。。。。。。。
@ SGD
参考文献:
https://stats.stackexchange.com/questions/153531/what-is-batch-size-in-neural-network
http://sebastianruder.com/optimizing-gradient-descent/














 2426
2426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









