







Using neural nets to recognize handwritten digits
Learning with gradient descent
对于一个网络,它的代价函数:
C(w,b)≡12n∑x∥y(x)−a∥2
其中,w和b为权重和偏置,n为输入样本总数,y(x)为输入样本x所属的类别,也就是groundtruth,a为经过网络计算后得到的向量。另外,C可以称作是二次代价函数,或者均方误差(MSE)。
我们要做的就是尽可能找到一组权重和偏置(w,b)来最小化代价函数,也就是说让预测值越接近groundtruth越好。训练算法采用梯度下降法(gradient descent)。
最小化 C(v) ,而 v=v1,v2,… ,其中用 v 来表示w和b。假设代价函数C有两个分量,
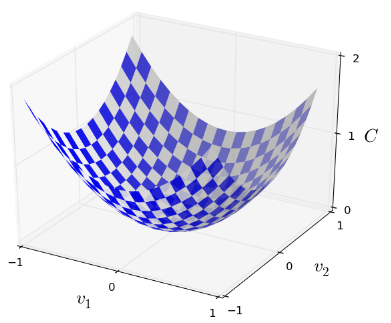
我们要做的就是找到曲面的最低点,因此要得到C的梯度信息。
ΔC≈∂C∂v1Δv1+∂C∂v2Δv2
注意啊,这里是变化值,不是梯度啊!
然后将上式中的导数部分提出来作为一个向量有: (∂C∂v1,∂C∂v2)T ,那么有:
∇C≡(∂C∂v1,∂C∂v2)T
注意这里就是梯度信息了啊! 然后
v1和v2
也提出来作为一个向量:
Δv≡(Δv1,Δv2)T
,然后见证奇迹的时刻到了!
ΔC≈∇C⋅Δv
再然后令
Δv=−η∇C
,得到:
ΔC≈−η∇C⋅∇C=−η|∇C|2
其中,
η
就是所谓的学习率啦(learning rate)。这样,由于
∥∇C∥2≥0
,而且
η
为正数,那么就保证了
ΔC≤0
。
v→v′=v−η∇C
按照这种方式逼近全局最小值。
关于learning rate的选取,如果过大会导致 ΔC>0 ,如果过小就会导致 Δv 变化的太慢。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









