



http://blog.csdn.net/jingling_zy/article/details/7397883
使用WebDAV从Windows上传日志到HDFS
本篇文章来源于 Linux公社网站(www.linuxidc.com) 原文链接:http://www.linuxidc.com/Linux/2012-01/51652.htm
在讨论如何从windows上传日志到hdfs时,除cygwin外,我们还测试了另外一种手段:webdav。
hdfs-webdav 下载
扩展Hadoop hdfs,实现webdav协议. 以便将hdfs映射为本地文件夹.
免费下载地址在 http://linux.linuxidc.com/
用户名与密码都是www.linuxidc.com
具体下载目录在 /2012年资料/1月/16/使用WebDAV从Windows上传日志到HDFS/
参考文档:http://www.linuxidc.com/Linux/2012-01/51647.htm
网上关于使用webdav进行上传日志的文章,基本上都是以上述链接文档为参考的。而且上述链接文档说的很详细,这里就不再赘述,安装完以后,即可从网页上看到效果。如图:
但是我们在windows上挂载hdfs目录时,出了点问题:必须与webdav同网段的windows机器才能挂载webdav目录!
为了解决这个问题,我们写了一个cshell程序,不用再挂载webdav目录了,直接连接URL进行上传;后来发现一个更简便的方法,就是使用curl的windows版直接上传,创建一个bat文件,用于计划任务,定时执行上传动作。我的bat文件示例如下:
for /R "G:\test" %%s in (*.*) do ( G:\curl_722_0\curl.exe -T %%s http://192.168.9.53:8080/hdfs-webdav/test/ )
注意:webdav的地址最后必须要有一个斜杠 (/)!否则会上传失败。
--------------------------------------------------------------
2011-10-09补充:
按上述做法搭建成功webdav,但是在上传日志到hdfs的时候,发现了一个问题:webdav按照64M大小的分块进行存储文件,默认拷贝3份副本;而我的集群设置为128M的块大小,2份副本。两者不符。
解决办法是,把Hadoop的hdfs-site.xml文件拷贝到webdav的WEB-INF/classes目录下,跟hadoop-site.xml文件放到一起。
本篇文章来源于 Linux公社网站(www.linuxidc.com) 原文链接:http://www.linuxidc.com/Linux/2012-01/51652.htm
解读HDFS
- 博客分类:
- hadoop编程
- 云计算 算法,HDFS
是蛮久木有写过关于hadoop的博客了额,虽然最近也看了一些关于linux的基础知识,但似乎把这个东西忘记了,其实时不时回顾一下以前的知识还是蛮有意思的,且行且忆!
我们Hadoop 主要由HDFS和MapReduce 引擎两部分组成。最底部是HDFS,它存储Hadoop 集群中所有存储节点上的文件。HDFS 的上一层是MapReduce 引擎,该引擎由JobTrackers 和TaskTrackers组成。
这篇博客就主要来讲讲HDFS吧~~~
HDFS是Hadoop Distributed File System的简称,既然是分布式文件系统,首先它必须是一个文件系统,那么在hadoop上面的文件系统会不会也像一般的文件系统一样由目录结构和一组文件构成呢?!分布式是不是就是将文件分成几部分分别存储在不同的机器上呢?!HDFS到底有什么优点值得这么小题大作呢?!......
好吧,让我们带着疑问一个个去探索吧!
一、HDFS基本概念
1、数据块
HDFS默认的最基本的存储单位是64M的数据块,这个数据块可以理解和一般的文件里面的分块是一样的
2、元数据节点和数据节点
元数据节点(namenode)用来管理文件系统的命名空间,它将所有的文件和文件夹的元数据保存在一个文件系统树中。
数据节点(datanode)就是用来存储数据文件的。
从元数据节点(secondarynamenode)不是我们所想象的元数据节点的备用节点,其实它主要的功能是主要功能就是周期性将元数据节点的命名空间镜像文件和修改日志合并,以防日志文件过大。
这里先来弄清楚这个三种节点的关系吧!其实元数据节点上存储的东西就相当于一般文件系统中的目录,也是有命名空间的映射文件以及修改的日志,只是分布式文件系统就将数据分布在各个机器上进行存储罢了,下面你看看这几张说明图应该就能明白了!



Namenode与secondary namenode之间的进行checkpoint的过程。
3、HDFS中的数据流
读文件
客户端(client)用FileSystem的open()函数打开文件,DistributedFileSystem用RPC调用元数据节点,得到文件的数据块信息。对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。DistributedFileSystem返回FSDataInputStream给客户端,用来读取数据。客户端调用stream的read()函数开始读取数据。DFSInputStream连接保存此文件第一个数据块的最近的数据节点。Data从数据节点读到客户端(client),当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。
整个过程就是如图所示:

写文件
客户端调用create()来创建文件,DistributedFileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件。元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。DistributedFileSystem返回DFSOutputStream,客户端用于写数据。客户端开始写入数据,DFSOutputStream将数据分成块,写入data queue。Data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。如果数据节点在写入的过程中失败:关闭pipeline,将ack queue中的数据块放入data queue的开始。
整个过程如图所示:

HDFS构架与设计
Hadoop也是一个能够分布式处理大规模海量数据的软件框架,这一切都是在可靠、高效、可扩展的基础上。Hadoop的可靠性——因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理。Hadoop的高效性——在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。Hadoop的可扩展——依赖于部署Hadoop软件框架计算集群的规模,Hadoop的运算是可扩展的,具有处理PB级数据的能力。
Hadoop 主要由HDFS(Hadoop Distributed File System)和MapReduce 引擎两部分组成。最底部是HDFS,它存储Hadoop 集群中所有存储节点上的文件。HDFS 的上一层是MapReduce 引擎,该引擎由JobTrackers 和TaskTrackers组成。
HDFS 可以执行的操作有创建、删除、移动或重命名文件等,架构类似于传统的分级文件系统。需要注意的是,HDFS 的架构基于一组特定的节点而构建(参见图2),这是它自身的特点。HDFS 包括唯一的NameNode,它在HDFS 内部提供元数据服务;DataNode 为HDFS 提供存储块。由于NameNode 是唯一的,这也是HDFS 的一个弱点(单点失败)。一旦NameNode 故障,后果可想而知。
1、HDFS构架(如图所示)

2、HDFS的设计
1)错误检测和快速、自动的恢复是HDFS的核心架构目标。
2)比之关注数据访问的低延迟问题,更关键的在于数据访问的高吞吐量。
3)HDFS应用对文件要求的是write-one-read-many访问模型。
4)移动计算的代价比之移动数据的代价低。
3、文件系统的namespace
Namenode维护文件系统的namespace,一切对namespace和文件属性进行修改的都会被namenode记录下来,连文件副本的数目称为replication因子,这个也是由namenode记录的。
4、数据复制
Namenode全权管理block的复制,它周期性地从集群中的每个Datanode接收心跳包和一个Blockreport。心跳包的接收表示该Datanode节点正常工作,而Blockreport包括了该Datanode上所有的block组成的列表。HDFS采用一种称为rack-aware的策略来改进数据的可靠性、有效性和网络带宽的利用。完成对副本的存放。
5、文件系统元数据的持久化
Namenode在内存中保存着整个文件系统namespace和文件Blockmap的映像。这个关键的元数据设计得很紧凑,因而一个带有4G内存的 Namenode足够支撑海量的文件和目录。当Namenode启动时,它从硬盘中读取Editlog和FsImage,将所有Editlog中的事务作用(apply)在内存中的FsImage ,并将这个新版本的FsImage从内存中flush到硬盘上,然后再truncate这个旧的Editlog,因为这个旧的Editlog的事务都已经作用在FsImage上了。这个过程称为checkpoint。在当前实现中,checkpoint只发生在Namenode启动时,在不久的将来我们将实现支持周期性的checkpoint。
6、通信协议
所有的HDFS通讯协议都是构建在TCP/IP协议上。客户端通过一个可配置的端口连接到Namenode,通过ClientProtocol与 Namenode交互。而Datanode是使用DatanodeProtocol与Namenode交互。从ClientProtocol和 Datanodeprotocol抽象出一个远程调用(RPC),在设计上,Namenode不会主动发起RPC,而是是响应来自客户端和 Datanode 的RPC请求。
HDFS不是这么简单就能说清楚的,在以后的博客中我还会继续研究hadoop的分布式文件系统,包括HDFS的源码分析等,现由于时间有限,暂时只做了以上一些简单的介绍吧,希望对大家由此对HDFS有一定的了解!
<!--EndFragment-->
一家公司使用apache的ftpserver开发框架开发了针对hadoop的hdfs文件系统的ftp服务器,当然是开源的.站点: http://www.hadoop.iponweb.net/Home/hdfs-over-ftp
安装过程非常简单,本人只是在linux下安装过,windows下没有成功安装,linux下安装步骤如下:
1.下载安装文件并解压
http://www.hadoop.iponweb.net/Home/hd ... tp.tar.bz2?attredirects=0
tar zxvf hdfs-over-ftp.tar.bz2
2.配置
软件根目录下的hdfs-over-ftp.conf
设置hdfs-uri的值
hdfs-uri = hdfs://hdfs的namenode的地址:9000
3.用户的设置
软件根目录下的users.conf
缺省用户好象不能login,在文件最后增加如下内容(用户和密码都是hadoop)
ftpserver.user.hadoop.userpassword=0238775C7BD96E2EAB98038A
ftpserver.user.hadoop.homedirectory=/
ftpserver.user.hadoop.enableflag=true
ftpserver.user.hadoop.writepermission=true
ftpserver.user.hadoop.maxloginnumber=0
ftpserver.user.hadoop.maxloginperip=0
ftpserver.user.hadoop.idletime=0
ftpserver.user.hadoop.uploadrate=0
ftpserver.user.hadoop.downloadrate=0
ftpserver.user.hadoop.groups=hadoop,users
密码使用md5生成,JAVA代码如下
PasswordEncryptor passwordEncryptor = new Md5PasswordEncryptor();
System.out.println(passwordEncryptor.encrypt("hadoop"));
4.log的设置
软件根目录下的log4j.conf
和普通的Log4j一样的设置
5.启动和停止方法
./hdfs-over-ftp.sh start
./hdfs-over-ftp.sh stop
6.测试结果
只有权限设置不能用,其它常用的ftp命令都能正常执行
而且上传下载速度甚至比直接使用hadoop的shell还快,当然要在网络环境一样的情况下
http://blog.csdn.net/whuqin/article/details/6662378
前面总体上认识了HDFS,本文介绍HDFS的使用,主要是对其Java API的介绍,参考hadoop的在线api。
1.web访问:http://localhost:50070,查看dfs、nodes。
2.命令行调用
格式:hadoop fs -command
具体命令:
[-ls <path>] [-lsr <path>] [-du <path>] [-dus <path>] [-count[-q] <path>] [-mv <src> <dst>] [-cp <src> <dst>] [-rm [-skipTrash] <path>] [-rmr [-skipTrash] <path>] [-mkdir <path>] [-put <localsrc> ... <dst>] [-copyFromLocal <localsrc> ... <dst>] [-copyToLocal [-ignoreCrc] [-moveFromLocal <localsrc> ... <dst>] [-moveToLocal [-crc] <src> <localdst>] [-crc] <src> <localdst>] [-getmerge <src> <localdst> [addnl]] [-cat <src>] [-text <src>] [-crc] <src> <localdst>] [-expunge] [-get [-ignoreCrc] [-setrep [-R] [-w] <rep> <path/file>] [-touchz <path>] [-test -[ezd] <path>] [-stat [format] <path>] [-tail [-f] <file>] [-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] [-chown [-R] [OWNER][:[GROUP]] PATH...] [-chgrp [-R] GROUP PATH...] [-help [cmd]]
每个命令的作用,可以使用hadoop fs -help command得到提示。还可参考http://cloud.it168.com/a2009/0615/589/000000589533.shtml。
3.Java API调用
关于hdfs的api主要在org.apache.hadoop.fs包中。下面的类除标明外,默认都在该包下。
3.1 org.apache.hadoop.conf.Configuration类:封装了一个客户端或服务器的配置,用于存取配置参数。系统资源决定了配置的内容。一个资源以xml形式的数据表示,由一系列的键值对组成。资源可以用String或path命名,String-指示hadoop在classpath中查找该资源;Path-指示hadoop在本地文件系统中查找该资源。
默认情况下,hadoop依次从classpath中加载core-default.xml(对于hadoop只读),core-site.xml(hadoop自己的配置文件,在安装目录的conf中),初始化配置。这里的classpath是指应用运行的类路径。服务端(hadoop)的classpath指向的是conf。客户端,classpath就是客户端应用的类路径(src)。
方法:addResource系列方法在配置中增加资源。
3.2 FileSystem抽象类:与hadoop的文件系统交互的接口。可以被实现为一个分布式文件系统,或者一个本地件系统。使用hdfs都要重写FileSystem,可以像操作一个磁盘一样来操作hdfs。
方法:
获得FileSystem实例:
static FileSystem get(Configuration):从默认位置classpath下读取配置。
static FileSystem get(URI,Configuration):根据URI查找适合的配置文件,若找不到则从默认位置读取。uri的格式大致为hdfs://localhost/user/tom/test,这个test文件应该为xml格式。
读取数据:
FSDataInputStream open(Path):打开指定路径的文件,返回输入流。默认4kB的缓冲。
abstract FSDataInputStream open(path,int buffersize):buffersize为读取时的缓冲大小。
写入数据:
FSDataOutputStream create(Path):打开指定文件,默认是重写文件。会自动生成所有父目录。有11个create重载方法,可以指定是否强制覆盖已有文件、文件副本数量、写入文件时的缓冲大小、文件块大小以及文件许可。
public FSDataOutputStream append(Path):打开已有的文件,在其末尾写入数据。
其他方法:
boolean exists(path):判断源文件是否存在。
boolean mkdirs(Path):创建目录。
abstract FileStatus getFileStatus(Path):获取一文件或目录的状态对象。
abstract boolean delete(Path f,boolean recursive):删除文件,recursive为ture-一个非空目录及其内容会被删除。如果是一个文件,recursive没用。
boolean deleteOnExit(Path):标记一个文件,在文件系统关闭时删除。
3.2 Path类:用于指出文件系统中的一个文件或目录。Path String用 “/" 隔开目录,如果以 / 开头表示为一个绝对路径。一般路径的格式为”hdfs://ip:port/directory/file"。
3.3 FSDataInputStream类:InputStream的派生类。文件输入流,用于读取hdfs文件。支持随机访问,可以从流的任意位置读取数据。完全可以当成InputStream来进行操作、封装使用。
方法:
int read(long position,byte[] buffer,int offset,int length):从position处读取length字节放入缓冲buffer的指定偏离量offset。返回值是实际读到的字节数。
void readFully(long position,byte[] buffer) / void readFully(long position,byte[] buffer,int offset,int length)。
long getPos():返回当前位置,即距文件开始处的偏移量
void seek(long desired):定位到desired偏移处。是一个高开销的操作。
3.4 FSDataOutputStream:OutputStream的派生类,文件输出流,用于写hdfs文件。不允许定位,只允许对一个打开的文件顺序写入。
方法:除getPos特有的方法外,继承了DataOutputStream的write系列方法。
3.5 其他类
org.apache.hadoop.io.IOUtils:与I/O相关的实用工具类。里面的方法都是静态!
static void copyBytes(InputStream in,OutputStream out,Configuration conf)
static void copyBytes(InputStream in, OutputStream out,Configuration conf,boolean close)
static void copyBytes(InputStream,OutputStream,int buffsize,boolean close)
static void copyBytes(InputStream in,OutputStream out,int buffSize)
copyBytes方法:把一个流的内容拷贝到另外一个流。close-在拷贝结束后是否关闭流,默认关闭。
static void readFully(InputStream in,byte[] buf, int off,int len):读数据到buf中。
FileStatus类:用于向客户端显示文件信息,封装了文件系统中文件和目录的元数据,包括文件长度、块大小、副本、修改时间、所有者以及许可信息。
FileSystem的继承关系如下:
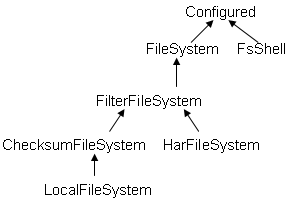
FsShell类:Provide command line access to a FileSystem,是带有主函数main的类,可以直接运行,如java FsShell [-ls] [rmr]。猜测:在终端使用hadoop fs -ls等命令时,hadoop应该就调用了该类FsShell。
ChecksumFileSystem抽象类:为每个源文件创建一个校验文件,在客户端产生和验证校验。HarFileSystem:hadoop存档文件系统,包括有索引文件_index*,内容文件part-*
LocalFileSystem:对ChecksumFileSystem的本地实现。
3.6 使用示例代码
- Configuration conf=new Configuration();
- FileSystem fs=FileSystem.get(conf);
- //读取数据
- FSDataInputStream in=fs.open(new Path("hdfs://localhost:9000/user/whuqin/input/file01"));
- //方法一
- BufferedReader bf=new BufferedReader(
- new InputStreamReader(in));
- System.out.println(bf.readLine());
- //方法二
- IOUtils.copyBytes(in, System.out, 1024,true);
- in.close();
- //写入数据
- FSDataOutputStream out=fs.create(
- new Path("hdfs://localhost:9000/user/whuqin/input/fileNew"));
- out.writeChars("hello OutputStrea\n");
- out.close();
- //删除文件
- fs.delete(new Path("hdfs://localhost:9000/user/whuqin/input/file01"),true);
方法一:编译成class后,放到hadoop的安装目录下,运行:hadoop HDFSTest(类名)。
方法二:将hadoop的core-site.xml复制到应用的类路径下,直接运行。
补:在命令行模式下,查看了下hdfs的目录结构发现如下:
- /home/whuqin/tmp/mapred/system/jobtracker.info
- /user/whuqin
HADOOP出现的错误:
Cannot create file/. Name node is in safe mode.
解方方法:
hadoop dfsadmin -safemode leave
参考资料
Hadoop 解除 "Name node is in safe mode"
|
运行hadoop程序时,有时候会报以下错误: 之前在hadoop执行过程中使用了"ctrl+c"操作 -----------------------------最近在測試hadoop,但是沒想到在reduce時卡點, 沒辦法只好Ctrl+c,但是問題也就跟著來了XD 先將hadoop停止後,再啟動hadoop 然後要刪除DFS裡的資料時, 就出現name node is in safe mode,就沒辦法刪除資料啦! 找了好久才找到答案, bin/hadoop dfsadmin -safemode leave 就可以把safemode解除,為了這個問題煩惱了好久Orz ----------------------------- safemode模式 NameNode在启动的时候首先进入安全模式,如果datanode丢失的block达到一定的比例(1-dfs.safemode.threshold.pct),则系统会一直处于安全模式状态即只读状态。 dfs.safemode.threshold.pct(缺省值0.999f)表示HDFS启动的时候,如果DataNode上报的block个数达到了元数据记录的block个数的0.999倍才可以离开安全模式,否则一直是这种只读模式。如果设为1则HDFS永远是处于SafeMode。 下面这行摘录自NameNode启动时的日志(block上报比例1达到了阀值0.9990) The ratio of reported blocks 1.0000 has reached the threshold 0.9990. Safe mode will be turned off automatically in 18 seconds. hadoop dfsadmin -safemode leave 有两个方法离开这种安全模式 1. 修改dfs.safemode.threshold.pct为一个比较小的值,缺省是0.999。 2. hadoop dfsadmin -safemode leave命令强制离开 http://bbs.hadoopor.com/viewthread.php?tid=61&extra=page%3D1 ----------------------------- Safe mode is exited when the minimal replication condition is reached, plus an extension time of 30 seconds. The minimal replication condition is when 99.9% of the blocks in the whole filesystem meet their minimum replication level (which defaults to one, and is set by dfs.replication.min). 安全模式的退出前提 - 整个文件系统中的99.9%(默认是99.9%,可以通过dfs.safemode.threshold.pct设置)的Blocks达到最小备份级别(默认是1,可以通过dfs.replication.min设置)。 dfs.safemode.threshold.pct float 0.999 The proportion of blocks in the system that must meet the minimum replication level defined by dfs.rep lication.min before the namenode will exit safe mode. Setting this value to 0 or less forces the name-node not to start in safe mode. Setting this value to more than 1 means the namenode never exits safe mode. ----------------------------- 用户可以通过dfsadmin -safemode value 来操作安全模式,参数value的说明如下: enter - 进入安全模式 leave - 强制NameNode离开安全模式 get - 返回安全模式是否开启的信息 wait - 等待,一直到安全模式结束。 |
http://hi.baidu.com/tekkie1987/blog/item/fe5c1883cb18639ff603a612.html
http://www.codelast.com/?p=3182
- 准备3台机器,一台作为Namenode,命名为master,两台作为dataNode,命名为slave01, slave02
- 在3台机器上都设置hadoop用户。
- 设置hadoop用户从master到slave ssh不需要密码,设置方法参见“设置SSH服务器只采用密钥认证”一文。
注意:(1)authorized_keys文件的访问权限应该设置为644,否则可能导致无密码登录失败。
(2)从master到master登录也需要配置无密码登录,否则会导致Namenode启动失败 - 下载并安装JDK,并在/etc/profile配置相应的环境变量,比如
JAVA_HOME=/usr/java/jdk1.6.0_18
CLASSPATH=.:$JAVA_HOME/lib
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH - 在三台机器上创建相同的目录路径,为HDFS运行准备环境,比如在/da
ta目录下创建hadoop目录,将其属主改成hadoop,然后在下面如下创建4个目录:
install:Hadoop源码解压后,放在该目录下
name:HDFS的名字节点存放目录
data01, da ta02:HDFS的数据存放目录,当然也可以是一个。
tmp:临时空间
注意:name目录只存放在master上,且权限为755,否则会导致后面的格式化失败。
- 编辑HDFS配置文件,所有节点都要保持一致,共有四个:
core-site.xml: 核心配置
hdfs-site.xml:站点多项参数配置
masters:主节点,在HDFS中就是Namenode的名称
slaves:数据节点(Datanode)名称
各个配置文件举例
核心配置:core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
站点节点配置:hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/data/hadoop/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/data/hadoop/da ta01,/da ta/hadoop/da ta02</value>
</property>
<property>
<name>dfs.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
</configuration>
主节点名称:masters
master
数据节点名称:slaves
master
slave01
slave02
注意:(1) 如需要,可以在hadoop-env.sh中配置JAVA_HOME变量,比如:
export JAVA_HOME=/usr/java/jdk1.6.0_18
(2) 保证各个节点上配置文件的一致性。 - 初始化namenode节点
登录到namenode上,cd /data/hadoop/install/bin,然后格式化Image文件的存储空间:
./hadoop namenode -format
如果出错,就查看/data/hadoop/install/logs下的日志文件。
- 启动HDFS服务
在/data/hadoop/install/bin下有很多命令,
* start-all.sh 启动所有的Hadoop守护,包括namenode, datanode,jobtracker,tasktrack,secondarynamenode。
* stop-all.sh 停止所有的Hadoop。
* start-mapred.sh 启动Map/Reduce守护,包括Jobtracker和Tasktrack。
* stop-mapred.sh 停止Map/Reduce守护
* start-dfs.sh 启动Hadoop DFS守护,Namenode和Datanode。
* stop-dfs.sh 停止DFS守护 - 简单使用
创建目录:./hadoop dfs -mkdir test
查看目录:./hadoop dfs -ls
drwxr-xr-x - hadoop supergroup 0 2010-03-04 21:27 /user/hadoop/test
拷贝文件:./hadoop dfs -put /etc/services test,即把本地的文件存放到HDFS中 - WEB界面
HDFS启动后,可以通过WEB界面来查看,缺省端口为50070,比如
http://master:50070/
即可查看整个HDFS的状态以及使用统计。
对于Mapreduce的WEB界面,缺省端口是50030
http://www.infoq.com/cn/articles/hadoop-config-tip
|
hadoop计算需要在hdfs文件系统上进行,文件上传到hdfs上通常有三种方法:a hadoop自带的dfs服务,put;b hadoop的API,Writer对象可以实现这一功能;c 调用OTL可执行程序,数据从数据库直接进入hadoop hadoop计算需要在hdfs文件系统上进行,因此每次计算之前必须把需要用到的文件(我们称为原始文件)都上传到hdfs上。文件上传到hdfs上通常有三种方法: a hadoop自带的dfs服务,put; b hadoop的API,Writer对象可以实现这一功能; c 调用OTL可执行程序,数据从数据库直接进入hadoop 由于存在ETL层,因此第三种方案不予考虑 将a、b方案进行对比,如下: 1 空间:方案a在hdfs上占用空间同本地,因此假设只上传日志文件,则保存一个月日志文件将消耗掉约10T空间,如果加上这期间的各种维表、事实表,将占用大约25T空间 方案b经测试,压缩比大约为3~4:1,因此假设hdfs空间为100T,原来只能保存约4个月的数据,现在可以保存约1年 2 上传时间:方案a的上传时间经测试,200G数据上传约1小时 方案b的上传时间,程序不做任何优化,大约是以上的4~6倍,但存在一定程度提升速度的余地 3 运算时间:经过对200G数据,大约4亿条记录的测试,如果程序以IO操作为主,则压缩数据的计算可以提高大约50%的速度,但如果程序以内存操作为主,则只能提高5%~10%的速度 4 其它:未压缩的数据还有一个好处是可以直接在hdfs上查看原始数据。压缩数据想看原始数据只能用程序把它导到本地,或者利用本地备份数据 压缩格式:按照hadoop api的介绍,压缩格式分两种:BLOCK和RECORD,其中RECORD是只对value进行压缩,一般采用BLOCK进行压缩。 对压缩文件进行计算,需要用SequenceFileInputFormat类来读入压缩文件,以下是计算程序的典型配置代码: JobConf conf = new JobConf(getConf(), log.class); conf.setMapperClass(MapClass.class); 接下来的处理与非压缩格式的处理一样 |
最近一段时间一直在从事和hadoop相关的工作,主要是技术内容学习、安装配置优化以及一些框架结构的设计。在此期间,我对于RDBMS和Hadoop的结合应用有了一些自己的看法,写出来大家共同探讨一下。
1、为什么要用Hadoop
这个在网上已近有很多的人说过这个问题,我在这里就不多述了。但是我想说下,对于一个工具而言,只有最合适的应用场景没有最牛的工具。hadoop对我而言也只是一个工具,所以,更多的时候我是从业务角度出发去考虑hadoop能给我带来什么。
2、RDBMS?
RDBMS是关系型数据库英文缩写,但对于我而言,就是oracle(因为我现在的公司用就是)。关于RDBMS和NOSQL谁更好这个话题争论的太多了,我也看了不少。但是我个人的感觉是,当前的RDBMS做的工作想用Hadoop来替代,基本是不可能,二者只能是互补互助,才能和谐共进(构建和谐社会,哈哈)。
3、数据仓库和数据库
就我个人的理解,数据仓库更倾向于数据的挖掘和分析,对实时性要求较低。而数据库则是对实时性响应较高,做为数据挖掘而言,虽然就目前当前看来是可以胜任,但是一旦数据量庞大(TB级别数据甚至PB级别),直接结果将是数据检索速度急剧下降,一些oracle执行的的挖掘job都有可能跑不出结果。所以,这也是为什么我在思考如何将hadoop和RDBMS结合应用的原因。废话不多说了,自己画了个草图大家先看看:

4、总体思想
由于工作环境和工作内容的特殊性,我这里并不涉及到大并发访问,所以,只要满足实时性的查询和数据挖掘即可。基于上图,我的总体思想如下:
a、将数据源在输入的时候就对数据进行拆分,一些侧重于数据分析和对实施响应要求较低的数据文件划分为“低实时性数据”。将一些相应速度要求较高的数据文件划分为“高实时性数据”。当然,这样划分可能数据之间可能会有交集,也就是说存在数据重复存放的可能性,所以,划分的具体原则需要结合业务详细制定。
b、“低实时性数据”存入HDFS文件系统,采用M/R或是Hive来进行一些挖掘的工作。而“高实时性数据”则存放在传统的RDBMS中,用以响应用户的实时查询需求。
c、Hadoop挖掘的数据结果可以协商好的格式存放到RDBMS中,提供为数据分析的基础。实际上,可以理解是Hadoop对数据内容进行的预处理,RDBMS则是在该结果的基础上进行高级功能(分析、比对、数据碰撞等)内容展示和二次分析。
d、用户也可直接的发送指令给Hadoop,进行一些特殊的数据挖掘工作,结果不需要存放到RDBMS中,直接反馈到用户web界面。(图上没表现出来)
5、总结
a、当前这样的应用模型可能会带来一些冗余数据,但是至少缓解了一些当前RDBMS的压力。
b、我最早也想过完全替换RDBMS,对于实时的查询我想采用hbase,但是在一段时间之后我发现hbase对一些查询支持的并不好。这里专门提出来也是希望大家能够给我解疑答惑,对于hbase如何应用是合适的?或者说在这个模型中是否还有hbase的位置?
b、上面说的内容都是基于我当前的工作环境来论述,大家如果觉得有疑问可以给我留言或发邮件(dajuezhao@gmail.com)。
http://blog.csdn.net/dajuezhao/article/details/5750459
1、Map-Reduce的逻辑过程
假设我们需要处理一批有关天气的数据,其格式如下:
- 按照ASCII码存储,每行一条记录
- 每一行字符从0开始计数,第15个到第18个字符为年
- 第25个到第29个字符为温度,其中第25位是符号+/-
| 0067011990999991950051507+0000+ 0043011990999991950051512+0022+ 0043011990999991950051518-0011+ 0043012650999991949032412+0111+ 0043012650999991949032418+0078+ 0067011990999991937051507+0001+ 0043011990999991937051512-0002+ 0043011990999991945051518+0001+ 0043012650999991945032412+0002+ 0043012650999991945032418+0078+ |
现在需要统计出每年的最高温度。
Map-Reduce主要包括两个步骤:Map和Reduce
每一步都有key-value对作为输入和输出:
- map阶段的key-value对的格式是由输入的格式所决定的,如果是默认的TextInputFormat,则每行作为一个记录进程处理,其中key为此行的开头相对于文件的起始位置,value就是此行的字符文本
- map阶段的输出的key-value对的格式必须同reduce阶段的输入key-value对的格式相对应
对于上面的例子,在map过程,输入的key-value对如下:
| (0, 0067011990999991950051507+0000+) (33, 0043011990999991950051512+0022+) (66, 0043011990999991950051518-0011+) (99, 0043012650999991949032412+0111+) (132, 0043012650999991949032418+0078+) (165, 0067011990999991937051507+0001+) (198, 0043011990999991937051512-0002+) (231, 0043011990999991945051518+0001+) (264, 0043012650999991945032412+0002+) (297, 0043012650999991945032418+0078+) |
在map过程中,通过对每一行字符串的解析,得到年-温度的key-value对作为输出:
| (1950, 0) (1950, 22) (1950, -11) (1949, 111) (1949, 78) (1937, 1) (1937, -2) (1945, 1) (1945, 2) (1945, 78) |
在reduce过程,将map过程中的输出,按照相同的key将value放到同一个列表中作为reduce的输入
| (1950, [0, 22, –11]) (1949, [111, 78]) (1937, [1, -2]) (1945, [1, 2, 78]) |
在reduce过程中,在列表中选择出最大的温度,将年-最大温度的key-value作为输出:
| (1950, 22) (1949, 111) (1937, 1) (1945, 78) |
其逻辑过程可用如下图表示:

2、编写Map-Reduce程序
编写Map-Reduce程序,一般需要实现两个函数:mapper中的map函数和reducer中的reduce函数。
一般遵循以下格式:
- map: (K1, V1) -> list(K2, V2)
| public interface Mapper<K1, V1, K2, V2> extends JobConfigurable, Closeable { void map(K1 key, V1 value, OutputCollector<K2, V2> output, Reporter reporter) throws IOException; } |
- reduce: (K2, list(V)) -> list(K3, V3)
| public interface Reducer<K2, V2, K3, V3> extends JobConfigurable, Closeable { void reduce(K2 key, Iterator<V2> values, OutputCollector<K3, V3> output, Reporter reporter) throws IOException; } |
对于上面的例子,则实现的mapper如下:
| public class MaxTemperatureMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { @Override public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = value.toString(); String year = line.substring(15, 19); int airTemperature; if (line.charAt(25) == '+') { airTemperature = Integer.parseInt(line.substring(26, 30)); } else { airTemperature = Integer.parseInt(line.substring(25, 30)); } output.collect(new Text(year), new IntWritable(airTemperature)); } } |
实现的reducer如下:
| public class MaxTemperatureReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { int maxValue = Integer.MIN_VALUE; while (values.hasNext()) { maxValue = Math.max(maxValue, values.next().get()); } output.collect(key, new IntWritable(maxValue)); } } |
欲运行上面实现的Mapper和Reduce,则需要生成一个Map-Reduce得任务(Job),其基本包括以下三部分:
- 输入的数据,也即需要处理的数据
- Map-Reduce程序,也即上面实现的Mapper和Reducer
- 此任务的配置项JobConf
欲配置JobConf,需要大致了解Hadoop运行job的基本原理:
- Hadoop将Job分成task进行处理,共两种task:map task和reduce task
- Hadoop有两类的节点控制job的运行:JobTracker和TaskTracker
- JobTracker协调整个job的运行,将task分配到不同的TaskTracker上
- TaskTracker负责运行task,并将结果返回给JobTracker
- Hadoop将输入数据分成固定大小的块,我们称之input split
- Hadoop为每一个input split创建一个task,在此task中依次处理此split中的一个个记录(record)
- Hadoop会尽量让输入数据块所在的DataNode和task所执行的DataNode(每个DataNode上都有一个TaskTracker)为同一个,可以提高运行效率,所以input split的大小也一般是HDFS的block的大小。
- Reduce task的输入一般为Map Task的输出,Reduce Task的输出为整个job的输出,保存在HDFS上。
- 在reduce中,相同key的所有的记录一定会到同一个TaskTracker上面运行,然而不同的key可以在不同的TaskTracker上面运行,我们称之为partition
- partition的规则为:(K2, V2) –> Integer, 也即根据K2,生成一个partition的id,具有相同id的K2则进入同一个partition,被同一个TaskTracker上被同一个Reducer进行处理。
| public interface Partitioner<K2, V2> extends JobConfigurable { int getPartition(K2 key, V2 value, int numPartitions); } |
下图大概描述了Map-Reduce的Job运行的基本原理:

下面我们讨论JobConf,其有很多的项可以进行配置:
- setInputFormat:设置map的输入格式,默认为TextInputFormat,key为LongWritable, value为Text
- setNumMapTasks:设置map任务的个数,此设置通常不起作用,map任务的个数取决于输入的数据所能分成的input split的个数
- setMapperClass:设置Mapper,默认为IdentityMapper
- setMapRunnerClass:设置MapRunner, map task是由MapRunner运行的,默认为MapRunnable,其功能为读取input split的一个个record,依次调用Mapper的map函数
- setMapOutputKeyClass和setMapOutputValueClass:设置Mapper的输出的key-value对的格式
- setOutputKeyClass和setOutputValueClass:设置Reducer的输出的key-value对的格式
- setPartitionerClass和setNumReduceTasks:设置Partitioner,默认为HashPartitioner,其根据key的hash值来决定进入哪个partition,每个partition被一个reduce task处理,所以partition的个数等于reduce task的个数
- setReducerClass:设置Reducer,默认为IdentityReducer
- setOutputFormat:设置任务的输出格式,默认为TextOutputFormat
- FileInputFormat.addInputPath:设置输入文件的路径,可以使一个文件,一个路径,一个通配符。可以被调用多次添加多个路径
- FileOutputFormat.setOutputPath:设置输出文件的路径,在job运行前此路径不应该存在
当然不用所有的都设置,由上面的例子,可以编写Map-Reduce程序如下:
| public class MaxTemperature { public static void main(String[] args) throws IOException { if (args.length != 2) { System.err.println("Usage: MaxTemperature <input path> <output path>"); System.exit(-1); } JobConf conf = new JobConf(MaxTemperature.class); conf.setJobName("Max temperature"); FileInputFormat.addInputPath(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); conf.setMapperClass(MaxTemperatureMapper.class); conf.setReducerClass(MaxTemperatureReducer.class); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); JobClient.runJob(conf); } } |
3、Map-Reduce数据流(data flow)
Map-Reduce的处理过程主要涉及以下四个部分:
- 客户端Client:用于提交Map-reduce任务job
- JobTracker:协调整个job的运行,其为一个Java进程,其main class为JobTracker
- TaskTracker:运行此job的task,处理input split,其为一个Java进程,其main class为TaskTracker
- HDFS:hadoop分布式文件系统,用于在各个进程间共享Job相关的文件

3.1、任务提交
JobClient.runJob()创建一个新的JobClient实例,调用其submitJob()函数。
- 向JobTracker请求一个新的job ID
- 检测此job的output配置
- 计算此job的input splits
- 将Job运行所需的资源拷贝到JobTracker的文件系统中的文件夹中,包括job jar文件,job.xml配置文件,input splits
- 通知JobTracker此Job已经可以运行了
提交任务后,runJob每隔一秒钟轮询一次job的进度,将进度返回到命令行,直到任务运行完毕。
3.2、任务初始化
当JobTracker收到submitJob调用的时候,将此任务放到一个队列中,job调度器将从队列中获取任务并初始化任务。
初始化首先创建一个对象来封装job运行的tasks, status以及progress。
在创建task之前,job调度器首先从共享文件系统中获得JobClient计算出的input splits。
其为每个input split创建一个map task。
每个task被分配一个ID。
3.3、任务分配
TaskTracker周期性的向JobTracker发送heartbeat。
在heartbeat中,TaskTracker告知JobTracker其已经准备运行一个新的task,JobTracker将分配给其一个task。
在JobTracker为TaskTracker选择一个task之前,JobTracker必须首先按照优先级选择一个Job,在最高优先级的Job中选择一个task。
TaskTracker有固定数量的位置来运行map task或者reduce task。
默认的调度器对待map task优先于reduce task
当选择reduce task的时候,JobTracker并不在多个task之间进行选择,而是直接取下一个,因为reduce task没有数据本地化的概念。
3.4、任务执行
TaskTracker被分配了一个task,下面便要运行此task。
首先,TaskTracker将此job的jar从共享文件系统中拷贝到TaskTracker的文件系统中。
TaskTracker从distributed cache中将job运行所需要的文件拷贝到本地磁盘。
其次,其为每个task创建一个本地的工作目录,将jar解压缩到文件目录中。
其三,其创建一个TaskRunner来运行task。
TaskRunner创建一个新的JVM来运行task。
被创建的child JVM和TaskTracker通信来报告运行进度。
3.4.1、Map的过程
MapRunnable从input split中读取一个个的record,然后依次调用Mapper的map函数,将结果输出。
map的输出并不是直接写入硬盘,而是将其写入缓存memory buffer。
当buffer中数据的到达一定的大小,一个背景线程将数据开始写入硬盘。
在写入硬盘之前,内存中的数据通过partitioner分成多个partition。
在同一个partition中,背景线程会将数据按照key在内存中排序。
每次从内存向硬盘flush数据,都生成一个新的spill文件。
当此task结束之前,所有的spill文件被合并为一个整的被partition的而且排好序的文件。
reducer可以通过http协议请求map的输出文件,tracker.http.threads可以设置http服务线程数。
3.4.2、Reduce的过程
当map task结束后,其通知TaskTracker,TaskTracker通知JobTracker。
对于一个job,JobTracker知道TaskTracer和map输出的对应关系。
reducer中一个线程周期性的向JobTracker请求map输出的位置,直到其取得了所有的map输出。
reduce task需要其对应的partition的所有的map输出。
reduce task中的copy过程即当每个map task结束的时候就开始拷贝输出,因为不同的map task完成时间不同。
reduce task中有多个copy线程,可以并行拷贝map输出。
当很多map输出拷贝到reduce task后,一个背景线程将其合并为一个大的排好序的文件。
当所有的map输出都拷贝到reduce task后,进入sort过程,将所有的map输出合并为大的排好序的文件。
最后进入reduce过程,调用reducer的reduce函数,处理排好序的输出的每个key,最后的结果写入HDFS。

3.5、任务结束
当JobTracker获得最后一个task的运行成功的报告后,将job得状态改为成功。
当JobClient从JobTracker轮询的时候,发现此job已经成功结束,则向用户打印消息,从runJob函数中返回。
http://www.cnblogs.com/forfuture1978/archive/2010/11/14/1877086.html
使用Cygwin从Windows上传日志到HDFS
本篇文章来源于 Linux公社网站(www.linuxidc.com) 原文链接:http://www.linuxidc.com/Linux/2012-01/51651.htm
windows操作系统:windows server2003
对cygwin不熟,所幸我只是需要进行很简单的应用,在同事的帮助下完成了这个工作。这里大致说一下,给大家提供一个思路。
1、安装JDK,并配置环境变量。要注意安装路径不要空格,不要安装到类似于program files这种目录,否则cygwin会出问题。
2、部署Hadoop。直接拉一个liux上部署的hadoop,并部署到本地。我把它放到了D盘的根目录下。
3、安装cygwin。主要是几个组件,不必细说。我把它安装到了D盘的根目录下。
4、创建windows用户cloud。这里创建的用户,必须与linux里运行hadoop的用户相同,否则在上传文件时会提示没有权限。
5、创建一个供cloud用户调用的bat文件,写入:
D:\cygwin\bin\bash --login -i D:/hadoop-0.20.2-CDH3B4/bin/hadoop -ls / 上述脚本的目的是为了测试使用windows脚本通过cygwin调用Hadoop命令是否成功。注意斜杠的不同: 前半部分是windows下的斜杠,后半部分是linux下的斜杠!
以cloud用户的身份运行这个脚本后,cygwin会其安装目录下的home文件下创建一个cloud的用户目录!
6、上述测试通过以后,则在cygwin中的cloud用户目录中创建一个sh文件,比如名为upload.sh的文件,写入:
#!/bin/bash D:/ Hadoop-0.20.2-CDH3B4/bin/hadoop fs -put $DIR/$FILES $HDFS 然后,重新编辑刚才的bat文件,把后面的命令更改为sh脚本名称:
D:\cygwin\bin\bash --login -i /home/cloud/upload.sh 7、其它的部分的修改,主要是Hadoop配置文件,一般要把其中的JAVA环境变量注释掉,或者某些部分的斜杠要改成windows的习惯,或者要修改windows的hosts表。
本篇文章来源于 Linux公社网站(www.linuxidc.com) 原文链接:http://www.linuxidc.com/Linux/2012-01/51651.htm


















 1391
1391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











