






论文题目:The YouTube Video Recommendation System
YouTube 电影推荐存在的难题:
- 用户上传的电影几乎没有电影的相关描述
- 电影的数量和活跃用户的用户数量在同一数量级
- 电影长度比较短,用户对电影的交互也短,所以数据噪声比较大
- 电影的生存周期比较短,推荐列表需要实时更新
推荐数据源:
第一类:视频数据流,视频元数据(标题,描述等)
第二类:用户活动数据,主要分为两种。
1 -> 直接活动:对电影评分,对电影点赞,订阅一个上传
2 -> 间接活动:用户观看电影的时长
计算两个电影之间的相似度
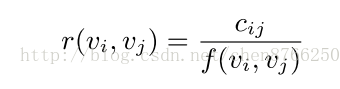
其中Cij表示电影i和电影j在一定时间段内,用户同时看电影i和电影j的用户数量
f(vi,vj) 归一化函数,可以是f(vi,vj) = ci * cj , 其中ci表示在时间段t内,观看电影i的用户数量,cj也类似
f函数的归一化方式可以参考如下论文。
a large-scale study in the orkut social network kdd 2005 ACM
寻找相似电影:
根据电影之间的相似性,以电影为顶点,电影直接爱你的相似性为边,构建无项有权的图W。
在图中可以找电影的相似电影。
首先构造用户喜欢电影集合S
再根据如下公式找寻推荐集合C1
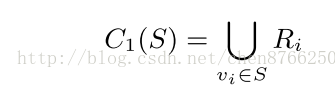
该计算公式只考虑与S相似的电影,这样推荐不够新颖和多样性,所以可以进行拓展,按如下公式进行计算
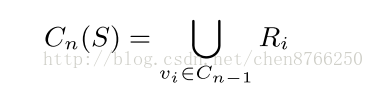
最终候选集如下:
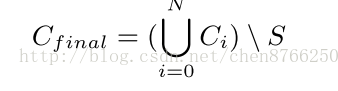
如何对这些候选推荐电影进行排序,可以按如下想法进行;
1 考虑电影的质量
2 考虑用户的个人爱好
3 考虑多样性














 967
967











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









